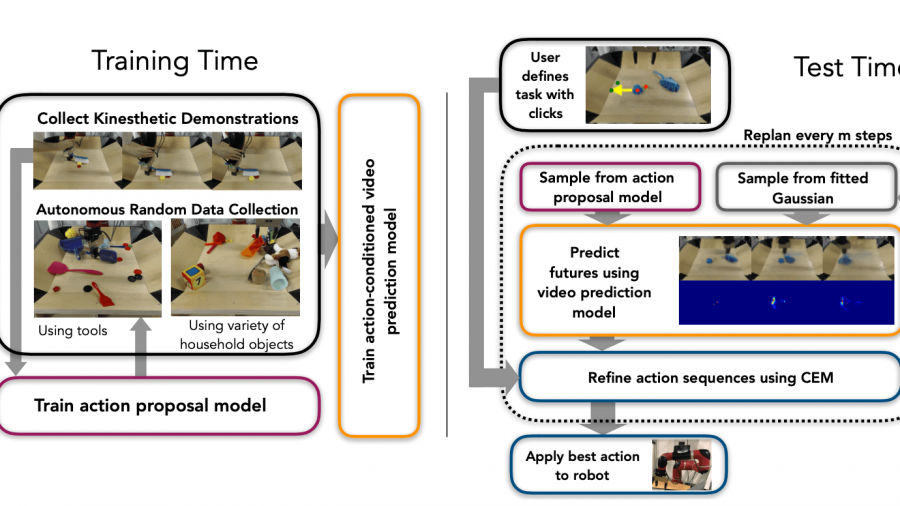
Исследователи UC Berkeley поставили задачу обучить модель одновременно выполнять комплексные задания и обобщать имеющиеся знания на новые виды объектов.
Ученые попытались решить эту проблему, разработав нейросеть GVF, которая обучается выполнять задания, состоящие из 2 и более действий, на основе начального изображения среды.
Модель с роботом в качестве интерфейса действует так:
- принимает на вход задачу (например, смахнуть мусор в совок) и начальное изображение с тем, как должна выглядеть среда;
- определяет доступные в его окружении предметы;
- воспроизводит это действие, используя доступные предметы и основываясь на изображении.
Обучение и архитектура решения
Процесс обучения делится на три этапа:
- Сначала исследователи записывают видео того, как совершают действия с предметами (чаще всего действия связаны с задачами вида «взять предмет и использовать его для манипуляции над другим»);
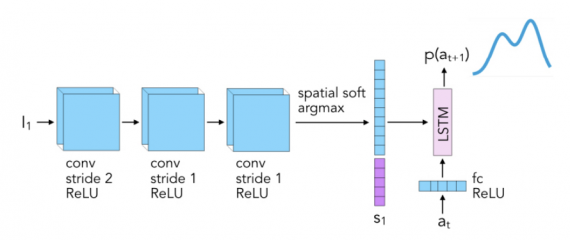
Эти данные используются для обучения модели, предсказывающей то, какое действие роботу необходимо совершить. Для этой задачи в качестве модели была выбрана autoregressive RNN.
- Помимо человеческих демонстраций, робот автономно собирает данные о взаимодействии со средой, исполняя случайно выбранные команды;
- Затем исследователи обучают модель, которая предсказывает продолжение видео-последовательности на основе начального изображения и соответствующей последовательности действий.
В качестве модели на третьем шаге была выбрана Recurrent Convolutional Neural Network (R-CNN).
Результаты
Исследователи оценили работу модели как количественным способом, так и качественным.
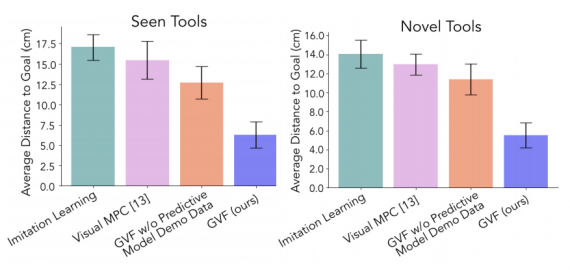
Видно, что предложенная модель, в сравнении с существующими архитектурами, в два раза более эффективна. В качестве архитектур для сравнения выступают Imitation Learning, Visual MPC, GVF без использования данных из шага 1 (см. Данные и архитектура решения).
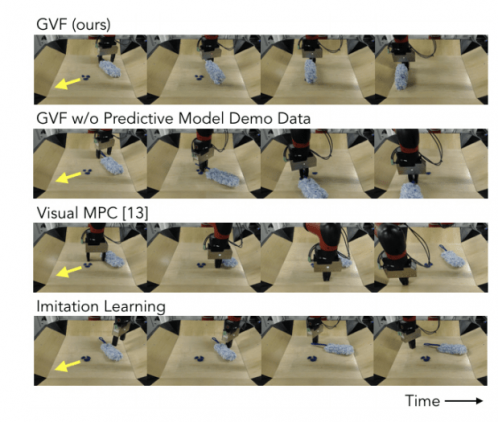
Кроме того, как можно заметить на изображении ниже, конкурирующие архитектуры более шумно исполняют требуемое действие в сравнении с GVF.
Ограничения и будущие исследования
Исследователи признают наличие у работы двух ограничений, которые впоследствии будут более подробно изучены:
- Задачи, которые поступают роботу, несмотря на разнообразие, в большинстве случаев задействуют только три действия (протереть, подмести, подержать).
В будущей работе планируется расширить данные и включить в список действий такие, как «порезать», «нанизать» и «прикрутить».
- Текущий подход полагается исключительно на визуальные подсказки.
В схожих моделях на вход поступают тактильные данные, которые робот собирает автономно. Исследователи планируют разнообразить типы входных данных для GVF, добавив тактильные данных к визуальным. Это вносит дополнительные сложности для обучения и оценки перформанса модели.
Так, исследователи предложили модель, которая эффективнее существующих решает задачу единовременного обучения роботов комплексным действиям и генерализации навыков на широкий спектр предметов.