Собираетесь изучать NLP и заниматься разработкой приложений, основанных на обработке естественного языка? Хотите создать свое приложение или программу для голосового помощника Amazon Alexa или Яндекс Алиса? В статье мы расскажем о направлениях развития и техниках, которые применяются для решения задач NLP, чтобы вам стало проще ориентироваться.
Что такое обработка естественного языка
Обработка естественного языка (далее NLP — Natural language processing) — область, находящаяся на пересечении computer science, искусственного интеллекта и лингвистики. Цель заключается в обработке и “понимании” естественного языка для перевода текста и ответа на вопросы.
С развитием голосовых интерфейсов и чат-ботов, NLP стала одной из самых важных технологий искусственного интеллекта. Но полное понимание и воспроизведение смысла языка — чрезвычайно сложная задача, так как человеческий язык имеет особенности:
- Человеческий язык — специально сконструированная система передачи смысла сказанного или написанного. Это не просто экзогенный сигнал, а осознанная передача информации. Кроме того, язык кодируется так, что даже маленькие дети могут быстро выучить его.
- Человеческий язык — дискретная, символьная или категориальная сигнальная система, обладающая надежностью.
- Категориальные символы языка кодируются как сигналы для общения по нескольким каналам: звук, жесты, письмо, изображения и так далее. При этом язык способен выражаться любым способом.
Где применяется NLP
Сегодня быстро растет количество полезных приложений в этой области:
- поиск (письменный или устный);
- показ подходящей онлайн рекламы;
- автоматический (или при содействии) перевод;
- анализ настроений для задач маркетинга;
- распознавание речи и чат-боты,
- голосовые помощники (автоматизированная помощь покупателю, заказ товаров и услуг).
Глубокое обучение в NLP
Существенная часть технологий NLP работает благодаря глубокому обучению (deep learning) — области машинного обучения, которая начала набирать обороты только в начале этого десятилетия по следующим причинам:
- Накоплены большие объемы тренировочных данных;
- Разработаны вычислительные мощности: многоядерные CPU и GPU;
- Созданы новые модели и алгоритмы с расширенными возможностями и улучшенной производительностью, c гибким обучением на промежуточных представлениях;
- Появились обучающие методы c использованием контекста, новые методы регуляризации и оптимизации.
Большинство методов машинного обучения хорошо работают из-за разработанных человеком представлений (representations) данных и входных признаков, а также оптимизации весов, чтобы сделать финальное предсказание лучше.
В глубоком обучении алгоритм пытается автоматически извлечь лучшие признаки или представления из сырых входных данных.
Созданные вручную признаки часто слишком специализированные, неполные и требуют время на создание и валидацию. В противоположность этому, выявленные глубоким обучением признаки легко приспосабливаются.
Глубокое обучение предлагает гибкий, универсальный и обучаемый фреймворк для представления мира как в виде визуальной, так и лингвистической информации. Вначале это привело к прорывам в областях распознавания речи и компьютерном зрении. Эти модели часто обучаются с помощью одного распространенного алгоритма и не требуют традиционного построения признаков под конкретную задачу.
Недавно я закончил исчерпывающий курс по NLP с глубоким обучением.
Этот курс — подробное введение в передовые исследование по глубокому обучению, примененному к NLP. Курс охватывает представление через вектор слов, window-based нейросети, рекуррентные нейросети, модели долгосрочной-краткосрочной памяти, сверточные нейросети и некоторые недавние модели с использованием компонента памяти. Со стороны программирования, я научился применять, тренировать, отлаживать, визуализировать и создавать собственные нейросетевые модели.
Замечание: доступ к лекциям из курса и домашним заданиям по программированию находится в этом репозитории.
Векторное представление (text embeddings)
В традиционном NLP слова рассматриваются как дискретные символы, которые далее представляются в виде one-hot векторов. Проблема со словами — дискретными символами — отсутствие определения cхожести для one-hot векторов. Поэтому альтернатива — обучиться кодировать схожесть в сами векторы.
Векторное представление — метод представления строк, как векторов со значениями. Строится плотный вектор (dense vector) для каждого слова так, чтобы встречающиеся в схожих контекстах слова имели схожие вектора. Векторное представление считается стартовой точкой для большинства NLP задач и делает глубокое обучение эффективным на маленьких датасетах. Техники векторных представлений Word2vec и GloVe, пользуются популярностью и часто используются для задач NLP. Давайте рассмотрим эти техники.
Word2Vec
Word2vec принимает большой корпус (corpus) текста, в котором каждое слово в фиксированном словаре представлено в виде вектора. Далее алгоритм пробегает по каждой позиции t в тексте, которая представляет собой центральное слово c и контекстное слово o. Далее используется схожесть векторов слов для c и o, чтобы рассчитать вероятность o при заданном с (или наоборот), и продолжается регулировка вектор слов для максимизации этой вероятности.
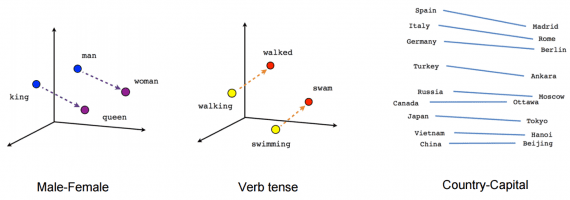
Для достижения лучшего результата Word2vec из датасета удаляются бесполезные слова (или слова с большой частотой появления, в английском языке — a,the,of,then). Это поможет улучшить точность модели и сократить время на тренировку. Кроме того, используется отрицательная выборка (negative sampling) для каждого входа, обновляя веса для всех правильных меток, но только на небольшом числе некорректных меток.
Word2vec представлен в 2 вариациях моделей:

- Skip-Gram: рассматривается контекстное окно, содержащее k последовательных слов. Далее пропускается одно слово и обучается нейронная сеть, содержащая все слова, кроме пропущенного, которое алгоритм пытается предсказать. Следовательно, если 2 слова периодически делят cхожий контекст в корпусе, эти слова будут иметь близкие векторы.
- Continuous Bag of Words: берется много предложений в корпусе. Каждый раз, когда алгоритм видим слово, берется соседнее слово. Далее на вход нейросети подается контекстные слова и предсказываем слово в центре этого контекста. В случае тысяч таких контекстных слов и центрального слова, получаем один экземпляр датасета для нашей нейросети. Нейросеть тренируется и ,наконец, выход закодированного скрытого слоя представляет вложение (embedding) для определенного слова. То же происходит, если нейросеть тренируется на большом числе предложений и словам в схожем контексте приписываются схожие вектора.
Единственная жалоба на Skip-Gram и CBOW — принадлежность к классу window-based моделей, для которых характерна низкая эффективность использования статистики совпадений в корпусе, что приводит к неоптимальным результатам.
GloVe
GloVe стремится решить эту проблему захватом значения одного word embedding со структурой всего обозримого корпуса. Чтобы сделать это, модель ищет глобальные совпадения числа слов и использует достаточно статистики, минимизирует среднеквадратичное отклонение, выдает пространство вектора слова с разумной субструктурой. Такая схема в достаточной степени позволяет отождествлять схожесть слова с векторным расстоянием.
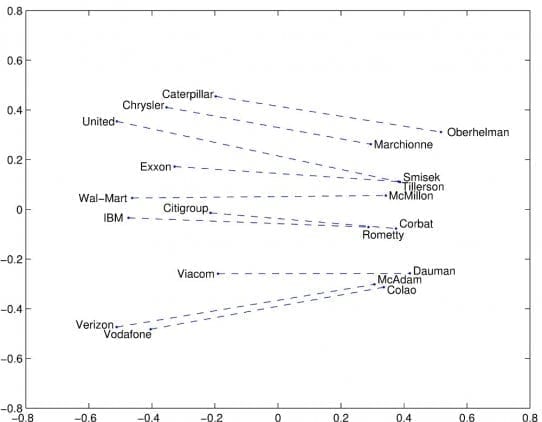
Помимо этих двух моделей, нашли применение много недавно разработанных технологий: FastText, Poincare Embeddings, sense2vec, Skip-Thought, Adaptive Skip-Gram.
Машинный перевод
Машинный перевод (Machine translation) — преобразование текста на одном естественном языке в эквивалентный по содержанию текст на другом языке. Делает это программа или машина без участия человека. В машинном переводе использутся статистика использования слов по соседству. Системы машинного перевода находят широкое коммерческое применение, так как переводы с языков мира — индустрия с объемом $40 миллиардов в год. Некоторые известные примеры:
- Google Translate переводит 100 миллиардов слов в день.
- Facebook использует машинный перевод для автоматического перевода текстов в постах и комментариях, чтобы разрушить языковые барьеры и позволить людям из разных частей света общаться друг с другом.
- eBay использует технологии машинного перевода, чтобы сделать возможным трансграничную торговлю и соединить покупателей и продавцов из разных стран.
- Microsoft применяют перевод на основе искусственного интеллекта к конечным пользователям и разработчикам на Android, iOS и Amazon Fire независимо от доступа в Интернет.
- Systran стал первым поставщиком софта для запуска механизма нейронного машинного перевода на 30 языков в 2016 году.
В традиционных системах машинного перевода приходится использовать параллельный корпус — набор текстов, каждый из которых переведен на один или несколько других языков. Например, имея исходных язык f (Французский) и целевой e (Английский), требуется построить статистическую модель, включающую вероятностную формулировку для правила Байеса, модель перевода p(f|e) , обученную на параллельном корпусе, и модель языка p(e) , обученную только на корпусе с английским языком.
Излишне говорить, что этот подход пропускает сотни важных деталей, требует большого количества спроектированных вручную признаков, состоит из различных и независимых задач машинного обучения.
Нейросетевой машинный перевод (Neural Machine Translation) — подход к моделированию перевода с помощью рекуррентной нейронной сети (Recurrent Neural Network, RNN). RNN — нейросеть c зависимостью от предыдущих состояний, в которая имеет связи между проходами. Нейроны получают информацию из предыдущих слоев, а также из самих себя на предыдущем шаге. Это означает, что порядок, в котором подается на вход данные и тренируется сеть, важен: результат подачи “Дональд” — “Трамп” не совпадает с результатом подачи “Трамп” — “Дональд”.
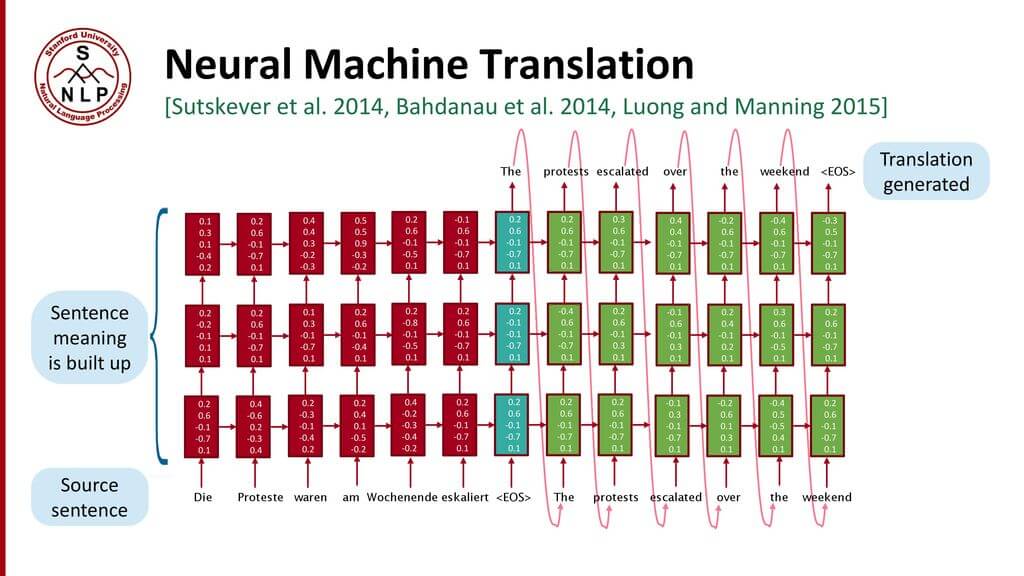
Стандартная модель нейро-машинного перевода является сквозной нейросетью, где исходное предложение кодируется RNN, называемой кодировщик (encoder), а целевое слово предсказывается с помощью другой RNN, называемой декодер (decoder). Кодировщик «читает» исходное предложение со скоростью один символ в единицу времени, далее объединяет исходное предложение в последнем скрытом слое. Декодер использует обратное распространение ошибки для изучение этого объединения и возвращает переведённую вариант. Удивительно, что находившийся на периферии исследовательской активности в 2014 году нейро-машинный перевод стал стандартом машинного перевода в 2016 году. Ниже представлены достижения перевода на основе нейронной сети:
- Сквозное обучение: параметры в NMT (Neural Machine Translation) одновременно оптимизируются для минимизации функции потерь на выходе нейросети.
- Распределенные представления: NMT лучше использует схожести в словах и фразах.
- Лучшее исследование контекста: NMT работает больше контекста — исходный и частично целевой текст, чтобы переводить точнее.
- Более беглое генерирование текста: перевод текста на основе глубокого обучения намного превосходит по качеству метод параллельного корпуса.
Главная проблема RNN — проблема исчезновения градиента, когда информация теряется с течением времени. Интуитивно кажется, что это не является серьезной проблемой, так как это только веса, а не состояния нейронов. Но с течением времени веса становятся местами, где хранится информация из прошлого. Если вес примет значение 0 или 100000, предыдущее состояние не будет слишком информативно. Как следствие, RNN будут испытывать сложности в запоминании слов, стоящих дальше в последовательности, а предсказания будут делаться на основе крайних слов, что создает проблемы.
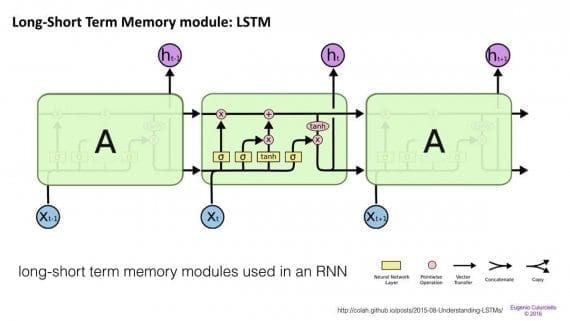
Сети краткосрочной-долгосрочной памяти (Long/short term memory, далее LSTM) пытаются бороться с проблемой градиента исчезновения вводя гейты (gates) и вводя ячейку памяти. Каждый нейрон представляет из себя ячейку памяти с тремя гейтами: на вход, на выход и забывания (forget). Эти затворы выполняют функцию телохранителей для информации, разрешая или запрещая её поток.
- Входной гейт определяет, какое количество информации из предыдущего слоя будет храниться в этой ячейке;
- Выходной гейт выполняет работу на другом конце и определяет, какая часть следующего слоя узнает о состоянии текущей ячейки.
- Гейт забывания контролирует меру сохранения значения в памяти: если при изучении книги начинается новая глава, иногда для нейросети становится необходимым забыть некоторые слова из предыдущей главы.
Было показано, что LSTM способны обучаться на сложных последовательностях и, например, писать в стиле Шекспира или сочинять примитивную музыку. Заметим, что каждый из гейтов соединен с ячейкой на предыдущем нейроне с определенным весом, что требуют больше ресурсов для работы. LSTM распространены и используются в машинном переводе. Помимо этого, это стандартная модель для большинства задач маркировки (labeling) последовательности, которые состоят из большого количества данных.
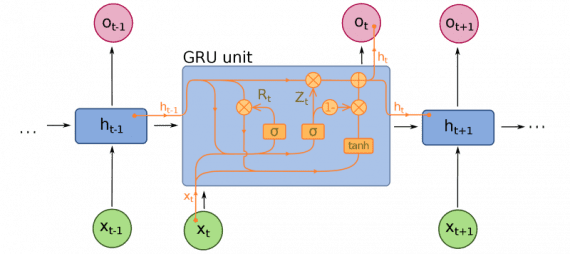
Закрытые рекуррентные блоки (Gated recurrent units, далее GRU) отличаются от LSTM, хотя тоже являются расширением для нейросетевого машинного обучения. В GRU на один гейт меньше, и работа строится по-другому: вместо входного, выходного и забывания, есть гейт обновления (update gate). Он определяет, сколько информации необходимо сохранить c последнего состояния и сколько информации пропускать с предыдущих слоев.
Функции сброса гейта (reset gate) похожи на затвор забывания у LSTM, но расположение отличается. GRU всегда передают свое полное состояние, не имеют выходной затвор. Часто эти затвор функционирует как и LSTM, однако, большим отличием заключается в следующем: в GRU затвор работают быстрее и легче в управлении (но также менее интерпретируемые). На практике они стремятся нейтрализовать друг друга, так как нужна большая нейросеть для восстановления выразительности (expressiveness), которая сводит на нет приросты в результате. Но в случаях, где не требуется экстра выразительности, GRU показывают лучше результат, чем LSTM.
Помимо этих трех главных архитектур, за последние несколько лет появилось много улучшений в нейросетевом машинном переводе. Ниже представлены некоторые примечательные разработки:
- Sequence-to-Sequence Learning with Neural Networks доказали эффективность LSTM для нейронного машинного перевода. Статья представляет общий подход для последовательного обучения, для которого характерны минимальные предположения о структуре последовательности. Этот метод использует многослойную LSTM, чтобы отобразить входящую последовательность в виде вектора с фиксированной размерностью, далее идет применение другой LSTM для декодирования целевой последовательности из вектора.
- Neural Machine Translation by Jointly Learning to Align and Translate представили механизм внимания (attention mechanism) в NLP (который будет рассмотрен в следующей части). Признавая факт, что использование вектора фиксированной длины является узким местом в улучшении результативности NMT, авторы предлагают разрешать модели автоматически искать части исходного предложение, которые релевантны к предсказанию целевого слова, без необходимости явного формирования этих частей.
- Convolutional over Recurrent Encoder for Neural Machine Translation усиливают стандартный RNN кодировщик в NMT с помощью дополнительного сверточного слоя, чтобы захватывать более широкий контекст на выходе кодировщика.
- Google создала собственную NMT систему, называемую Google’s Neural Machine Translation, которая решает задачи точности и простоты применения. Модель состоит из глубокой LSTM сети с 8 кодирующими и 8 декодирующими слоями и использует как остаточные связи, так и attention-связи от декодер- до кодер-сети.
- Вместо использования рекуррентных нейросетей, Facebook AI Researchers используют сверточную нейронную сеть для задач sequence-to-sequence обучения в NMT.
Голосовые помощники
Много статей написано о “разговорном” искусственном интеллекте (ИИ), большинство разработок фокусируется на вертикальных чат-ботах, мессенджер-платформах, возможностях для стартапов (Amazon Alexa, Apple Siri, Facebook M, Google Assistant, Microsoft Cortana, Яндекс Алиса). Способности ИИ понимать естественный язык пока остаются ограничены, поэтому создание полноценного разговорного ассистента остается открытой задачей. Тем не менее, представленные ниже работы — отправная точка для людей, заинтересованных в прорыве в области голосовых помощников.
Исследователи из Монреаля, Технического Института Технологий Джорджии, Microsoft и Facebook создали нейросеть, способную создавать чувствительные к контексту ответы в разговоре. Эта система может тренироваться на большом количестве неструктурированных диалогов в Twitter. Архитектура рекуррентной нейросети используется для ответов на разреженные вопросы, которые появляются при интегрировании контекстной информации в классическую статистическую модель, что позволяет системе учесть сказанное ранее. Модель показывает уверенное улучшение результата над контент-чувствительной и контент-нечувствительной базовой линией машинного перевода и поиска информации.
Разработанная в Гонконге нейронная машина для ответов (далее NRM — Neural Responding Machine) — генератор ответов для коротких текстовых бесед. NRM использует общий кодер-декодер фреймворк. Сначала формализуется создание ответа, как процесс расшифровки на основе скрытого представления входного текста, пока кодирование и декодирование реализуется с помощью рекуррентных нейросетей. NRM обучен на больших данных с односложными диалогами, собранными из микро-блогов. Эмпирическим путем установлено, что NRM способен генерировать правильные грамматические и уместные в данном контексте ответы на 75% поданных на вход текстов, опережая в результативности современные модели с теми же настройками.
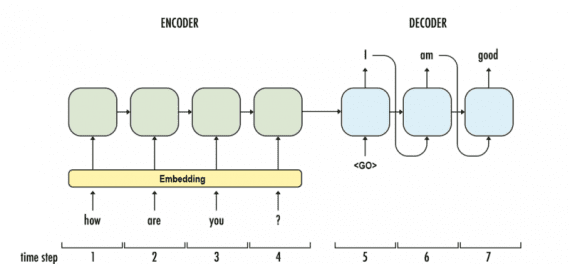
Последняя модель — Google’s Neural Conversational Model предлагает простой подход к моделированию диалогов, используя sequence-to-sequence фреймворк. Модель поддерживает беседу благодаря предсказанию следующего предложения, используя предыдущие предложения из диалога. Сильная сторона этой модели — способность к сквозному обучению, из-за чего требуется намного меньше рукотворных правил.
Модель способна создавать простые диалоги на основе обширного диалогового тренировочного сета, способна извлекать знания из узкоспециализированных датасетов, а также больших и зашумленных общих датасетов субтитров к фильмам. В узкоспециализированной области справочной службы для ИТ-решений модель находит решения технической проблемы с помощью диалога. На зашумленных датасетах транскриптов фильмов модель способна делать простые рассуждения на основе здравого смысла.
Вопросно-ответные (QA) системы
Идея вопросно-ответных (Question-answering, далее — QA) систем заключается в извлечении информации непосредственно из документа, разговора, онлайн поиска или любого другого места, удовлетворяющего потребности пользователя. Вместо того, чтобы заставлять пользователя читать полный текст, QA системы предпочитают давать короткие и лаконичные ответы. Сегодня QA системы легко комбинируются с чат-ботами, выходят за пределы поиска текстовых документов и извлекают информацию из набора картинок.
Большинство NLP задач могут быть рассмотрены как вопросно-ответные задачи. Парадигма проста: отправляется запрос, на который машина предоставляет ответ. Через чтение текста или набора инструкций разумная система должна находить ответ на большой круг вопросов. Естественно, требуется создать модель для ответов на общие вопросы.

Специально для QA задач создана и оптимизирована мощная архитектура глубокого обучения — Сеть Динамической Памяти (Dynamic Memory Network, далее — DNM). Обученная на тренировочном наборе из входных данных и вопросов, DNM формирует эпизодические воспоминания и использует их для генерации подходящих ответов. Эта архитектура состоит из следующих компонент:
- Модуль семантической памяти, аналогичный базе знаний, состоит из предварительно подготовленных GloVe векторов, которые используются для создания последовательностей векторных представлений слов из входящих предложений. Эти вектора будут использоваться, как входные данные модели.
- Входной модуль перерабатывает связанные с вопросом входящие вектора в наборов векторов, называемый фактами. Этот модуль реализован с помощью Управляемого рекуррентного блока (Gated Recurrent Unit, далее — GRU), который позволяет сети узнать релевантность рассматриваемого предложения.
- Вопросный модуль обрабатывает вопрос слово за словом и выдает вектор, используя тот же GRU, что и в входном модуле, с такими же весами.
- Модуль эпизодической памяти сохраняет извлеченные на входе векторы фактов и вопросов, закодированные как вложения. Это похоже на происходящий в гиппокампе мозга процесс по извлечению временных состояний в ответ на звук или вид.
- Ответный модуль генерирует подходящий ответ. На последнем шаге эпизодическая память содержит необходимую для ответа информацию. Этот модуль использует другой GRU, обученный с классификацией кросс-энтропийной ошибки верной последовательности, которая конвертируется обратно на естественный язык.
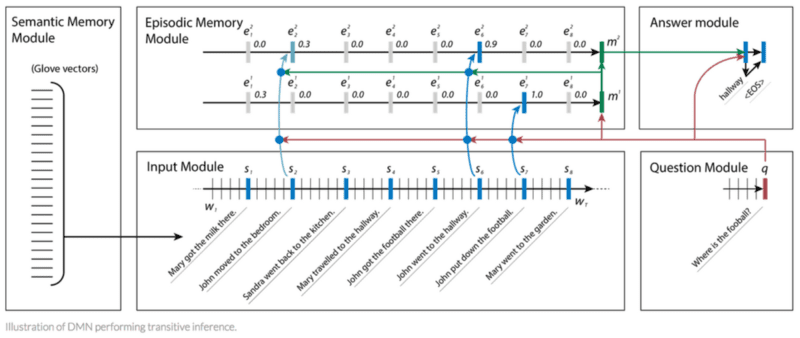
DNM хорошо справляется с QA задачами и превосходит в результатах другие архитектуры для семантического анализа и частеречной разметки (part-of-speech tagging). С момента выпуска начальной версии DMN претерпела ряд улучшений для дальнейшего совершенствования точности в QA задачах:
- DMN для ответов на текстовые и визуальные вопросы — DNM применимая к изображениям. Здесь входные модули и модули памяти модернизированы для ответов на визуальные вопросы. Такая модель улучшает результат существующей архитектуры на большинстве тестов на визуальных вопросно-ответных датасетах без учителя.
- Динамические coattention-сети для ответов на вопросы выступают с решением проблемы выхода из локального максимума, соответствующего неправильному ответу. Модель сливает со-зависимые представления вопроса и текст,чтобы сфокусироваться на их подходящих частях. Далее динамический указательный декодер проходит через полный набор потенциальных ответов.
Краткое изложение текста (Text Summarization)
Человеку сложно вручную выделить краткое содержание в большом объеме текста. Поэтому в NLP возникает проблема создания точного и лаконичного резюме для исходного документа. Извлечение краткого содержания (Text Summarization) — важный инструмент для помощи в интерпретации текстовой информации. Push-уведомления и дайджесты статей привлекают большое внимание, а количество задач по созданию разумных и точных резюме для больших фрагментов текста растет день ото дня.
Автоматическое извлечение краткого содержания из текста работает следующим образом. Сначала считается частота появления слова во полном текстовом документе, затем 100 наиболее частых слов сохраняются и сортируются. После этого каждое предложение оценивается по количеству часто употребимых слов, причем вес больше у более часто встречающегося слова. Наконец, первые Х предложений сортируются с учетом положения в оригинальном тексте.
С сохранением простоты и обобщающей способности алгоритм автоматического извлечения краткого содержания способен работать в сложных ситуациях. Например, многие реализации терпят неудачи на текстах с иностранными языками или уникальными словарными ассоциациями, которые не содержатся в стандартных массивах текстов.
Выделяют два фундаментальных подхода к сокращению текста: извлекательный и абстрактный. Первый извлекает слова и фразы из оригинального текста для создания резюме. Последний изучает внутреннее языковое представление, чтобы создать человекоподобное изложение, перефразируя оригинальный текст.
Методы в извлекательном сокращении работают на основе выбора подмножества. Это достигается за счет извлечения фраз или предложений из статьи для формирования резюме. LexRank и TextRank — хорошо известные представители этого подхода, которые используют вариации алгоритм сортировки страниц Google PageRank.
LexRank — алгоритм обучения без учителя на основе графов, который использует модифицированный косинус обратной частоты встречи слова, как мера похожести двух предложений. Похожесть используется как вес грани графа между двумя предложениями. LexRank также внедряет шаг умной постобработки, которая убеждается, что главные предложения не слишком похожи друг на друга.
TextRank похож на алгоритм LexRank, но имеет некоторые улучшений. К ним относятся:
- использование лемматизация вместо стемминга
- применение частеречной разметки и распознавания имени объекта
- извлечению ключевых фраз и предложений, на основе этих слов
- вместе с кратким содержанием статьи TextRank извлекает важные ключевые фразы.
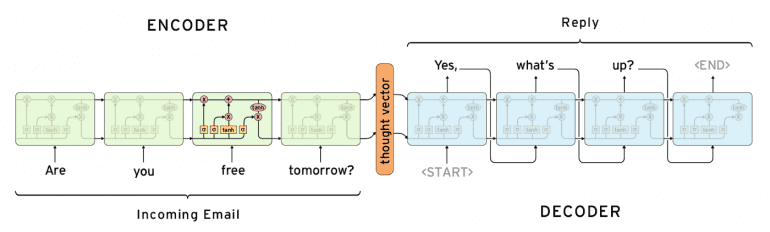
Модели для абстрактного резюмирования используют глубокое обучение, которое позволило сделать прорывы в таких задачах. Ниже представлены примечательные результаты больших компаний в области NLP:
- Facebook Neural Attention — нейросетевая архитектура, которая использует локальную модель с механизвом внимания, способную генерировать каждое слово резюме в зависимости от входного предложения.
- Google Sequence-to-sequence придерживается кодер-декодер архитектуры. Кодер отвечает за чтение исходного документа и кодировку во внутреннее представление. Декодер отвечает за генерацию каждого слова в сводке на выходе и использует кодированное представление исходного документа.
- IBM Watson использует похожую Sequence-to-sequence модель, но со свойствами внимательной и двунаправленной рекуррентной нейросети.
Интересные статьи:
- NLP Architect от Intel: open source библиотека моделей обработки естественного языка
- Рекуррентные нейронные сети: типы, обучение, примеры и применение
- Word2Vec: как работать с векторными представлениями слов