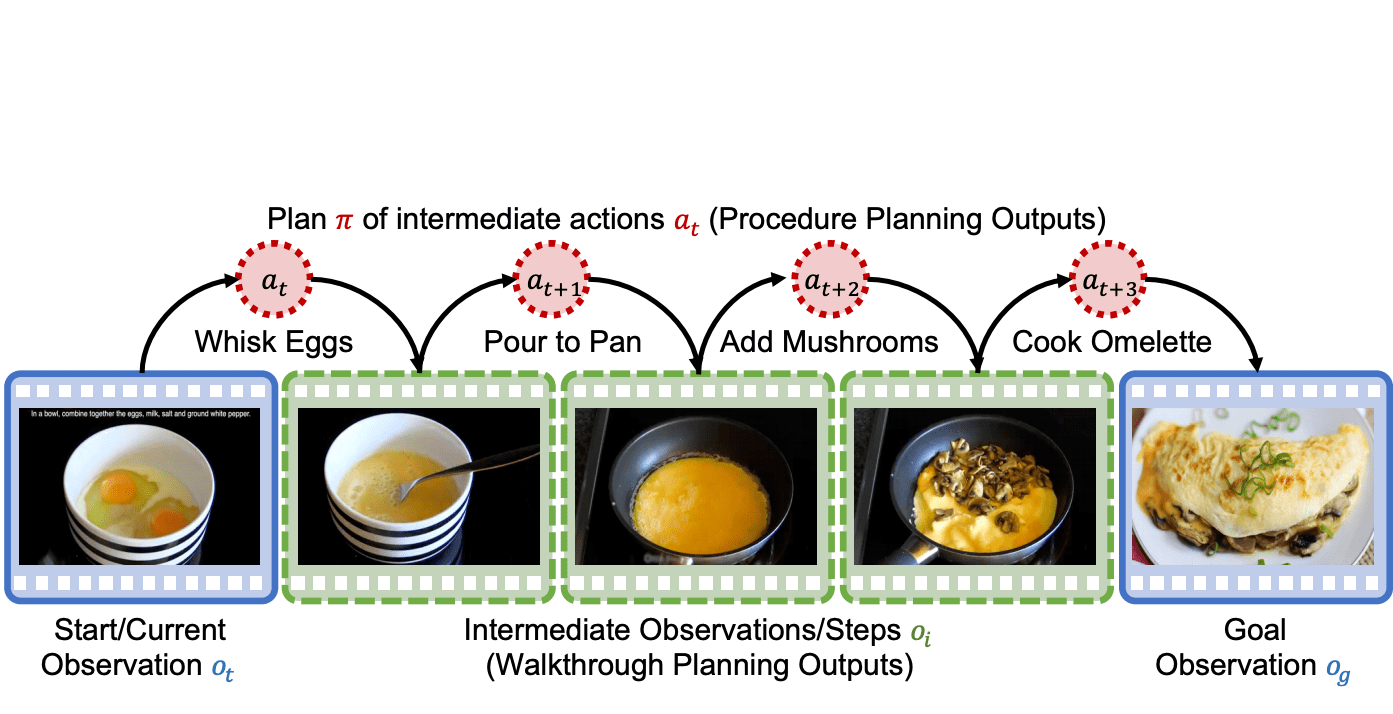
Исследователи из Stanford обучили нейросеть, которая после просмотра обучающего видео воспроизводит последовательность действий для достижения цели.
Реальный мир содержит в себе широкий набор вероятностей действий. Большинство традиционных подходов для планирования не учитывают эти вероятности. Исследователи предлагают представить характеристики среды в латентном пространстве, чтобы выучить модель сопоставлять текущее состояние среды и действие, которое необходимо предпринять.
Архитектура модели
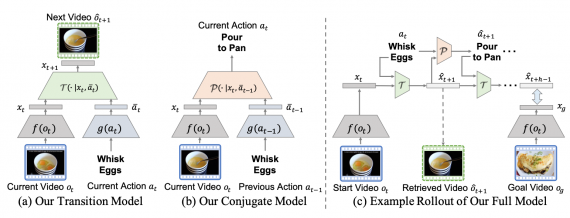
Модель для создания латентного пространства и сопоставления характеристик среды и действий, делится на 2 компонента:
- Переходная модель (transition model), которая предсказывает следующее состояние на основании текущего состояния и действия;
- Conjugate constraint модель сопоставляет текущие действия с ранее совершенными действиями — в основе лежит RNN
Нейросеть берет видео и выучивает переходы между состояниями с помощью двух основных компонентов. На выходе выходе генерируется последовательность действий, которая из состояния А приведет к состоянию Б.
Подходы к планированию
Исследователи экспериментируют с двумя подходами к планированию, которые опираются на свойства действий, полученные из нейросети.
Первый подход сопоставляет текущее состояние среды и целевое в латентном пространстве. В то же время алгоритм сопоставляет возможные действия с совершенными и семплирует из разных действий, чтобы дойти до целевого состояния.
Второй подход исследователи называют “walkthrough planning”. Идея в том, что алгоритм выдает визуальные различия между текущим и целевым состояниями среды. Это не прямой подход к решению задачи и не выдает последовательность действий, но может служить как сигнал о награде в другой модели.
Данные
Для исследования был использован датасет с обучающими видео CrossTask. Датасет состоит из видеозаписями решения 83 задач. Среди примеров задач — жарка блинов, замена колеса.
Проверка работы модели
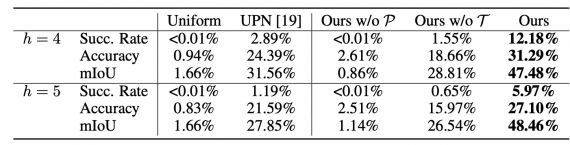
Исследователи сравнили нейросеть с несколькими базовыми решениями:
- Случайно выбирать действия из равномерного распределения;
- Universal Planning Networks (UPN) — наиболее схожая модель из предшествующих работ
Помимо этого, исследователи проверили, вклад каждого из компонентов нейросети в точность предсказаний. Метрики для оценки были — Success rate, Accuracy и mIoU.
Ниже видно, что точность модели не превысила 50%. Несмотря на то, что по метриками модель обходит конкурирующие подходы, нельзя говорить о корректности сравнений.
Задача восстановления последовательности действий — это комплексная задача. Более привычно к решению подобной задачи подходить не через RNN, а через алгоритмы обучения с подкреплением.