Модель генерации вопросов к изображению, предложенная исследователями из Стенфордского университета, показала результаты лучше, чем существующие state-of-the-art модели IA2Q и V-IA2Q.
Проблема и предыдущие исследования
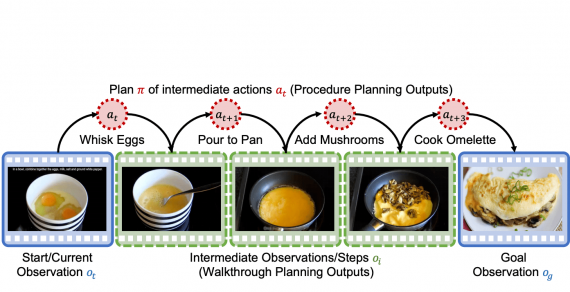
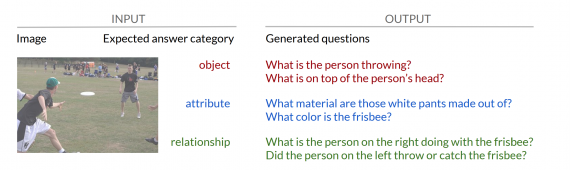
Ученые поставили перед собой задачу image-to-sequence генерации, когда на входе принимается картинка и желаемый тип ответа, а на выдается сгенерированный вопрос, учитывающий контекст того, что изображено картинке.
Привычный подход к решению этой задачи — кодировать изображения через CNN и декодировать вопросы через RNN с использованием MLE. Однако ограничение этого подхода в том, что сгенерированные вопросы получаются однообразными и не учитывают тип ответа.
Что предложили, чтобы улучшить
Исследователи решили проблему с невозможности учитывать заданную категорию ответа с помощью максимизации взаимной информации (MI) между сгенерированным вопросом и изображением, а также между сгенерированными вопросом и категорией ответа.
Для оптимизации MI ученые вводят z-space — скрытое пространство.
Процесс обучения проходит следующим образом:
-
- Изображение и ответ переводятся в вектора в скрытом пространстве z;
-
- Оптимизируется совместная информация между изображением и ответов, чтобы восстановить изображение и ответ;
-
- Из z пространства генерируется вопрос, формулировка которого оптимизируется с помощью MLE;
- Вводится второе скрытое пространство t, которое обучается через минимизацию расстояния Кульбака-Лейблера и позволяет генерировать вопрос без привязки к поданному на вход ответу, но с опорой на категорию ответа.
Проверка работы модели
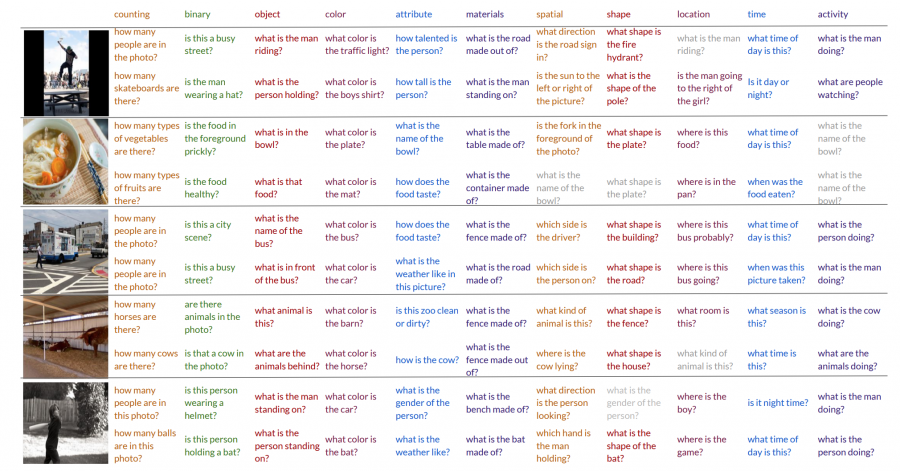
Для проверки эффективности модели исследователи сравнили ее с такими архитектурами, как IA2Q и V-IA2Q. Проверка проводилась на датасете VQA. Категории ответов выделялись вручную (15 категорий), для каждой категории ответа были размечены 500 самых часто встречаемых ответов (82% от всего датасета) с помощью ResNet18. Итоговый сет данных для тренировки и валидации составил 367 тыс. объектов.
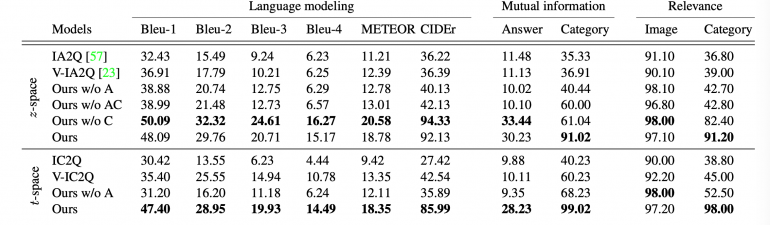
Наилучшие результаты стабильно показывали полная модель (Ours), модель без скрытого пространства t, генерирующая вопросы только из ответов (Ours w/o C) и модель без максимизации взаимной информации (Ours w/o A). Предложенные модели превзошли существующие.