В последнее время рост спроса на навыки в области data science рос быстрее, чем уровень квалификации специалистов. Сегодня трудно представить себе бизнес, который не выиграл бы от подробного анализа данных, которые проводят ученые и алгоритмы машинного обучения. Поскольку искусственный интеллект проникает во все уголки отрасли, трудно удовлетворить потребности ученых-данных в каждом возможном случае использования. Чтобы уменьшить давление, создаваемое этим дефицитом, несколько компаний начали разрабатывать структуры, способные частично автоматизировать процесс, обычно используемый дата саентистами.
Перевод статьи «AutoML — A Tool to Improve Your Workflow», автор — Tom Allport, ссылка на оригинал — в подвале статьи.
AutoML — это метод, который автоматизирует процесс применения методов машинного обучения к данным. Как правило, специалист по обработке данных тратит большую часть своего времени на предварительную обработку, инженерию признаков, выбор и настройку моделей, а затем оценку результатов. AutoML может автоматизировать эти задачи, предоставляя базовый результат, а также может обеспечить высокую производительность при определенных проблемах и дать понимание того, где можно продолжить исследование.
В этой статье мы рассмотрим модуль Python H2O и его функцию AutoML. H2O — это программное обеспечение на основе Java для моделирования данных и общих вычислений. Согласно H2O.ai, «Основное назначение H2O — это распределенный, параллельный механизм обработки памяти (до нескольких сотен гигабайт у параметра Xmx для JVM)».
AutoML — это функция в H2O, которая автоматизирует процесс построения большого количества моделей с целью поиска «лучшей» модели без каких-либо предварительных знаний. AutoML не выиграет вас ни в каких соревнованиях (однако, эта информация устарела — прим. редактора), но он может предоставить много информации, которая поможет вам создавать лучшие модели и сократить время, затрачиваемое на изучение и тестирование различных моделей.
Текущая версия функции AutoML может обучать и выполнять кросс-валидацию для случайного леса, экстремально случайного леса, случайной сетки машин градиентного бустинга, случайной сетки глубоких нейронных сетей, а затем обучать составной ансамбль, используя все модели.
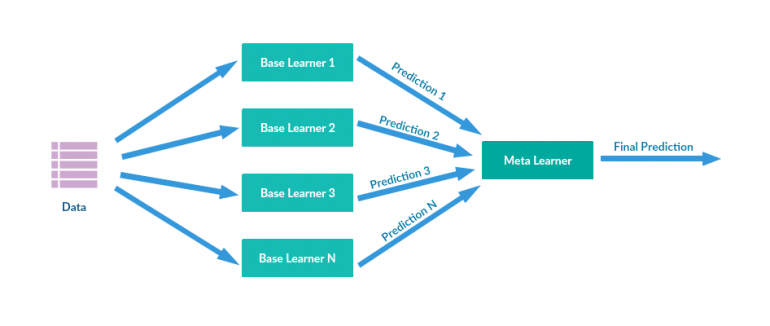
Стекинг (также называемый метаансамблирование) — это метод ансамблирования моделей, используемый для объединения информации из нескольких прогнозирующих моделей для создания новой модели. Часто скомбинированная модель (также называемая моделью 2-го уровня) превосходит каждую из отдельных моделей благодаря своей сглаживающей природе и способности выделять каждую базовую модель там, где она работает лучше всего, и ослаблять каждую базовую модель, где она работает плохо. По этой причине стекинг наиболее эффективен, когда базовые модели существенно отличаются.
Стеки предсказаний моделей машинного обучения очень часто превосходят современные академические результаты и широко используются в соревнованиях Kaggle. С другой стороны, они, как правило, требуют больших вычислительных ресурсов. Но если время и ресурсы не являются проблемой, то зачастую минимальное процентное улучшение прогноза может, например, помочь компаниям сэкономить много денег.
Исследование данных
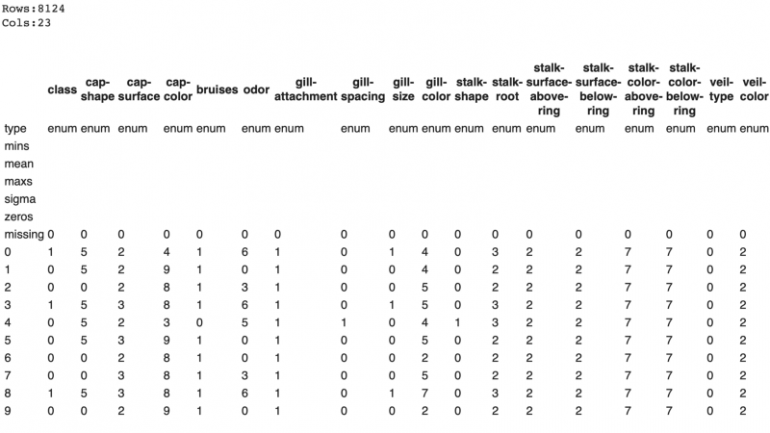
В этой статье мы рассмотрим Mushroom Classification Dataset, который можно найти на Kaggle и который предоставлен UCI Machine Learning. Датасет содержит 23 категориальных признака и более 8000 объектов. Данные подразделяются на две категории: съедобные и ядовитые. Классы распределяются достаточно равномерно, с 52% объектами в съедобном классе. В данных отсутствуют пропущенные наблюдения. Это популярный датасет с более чем 570 кернелами на Kaggle, которые мы можем использовать, чтобы увидеть, насколько хорошо AutoML работает по сравнению с традиционными рабочими методами.
Запуск H2O
Сначала вам нужно установить и импортировать модуль Python H2O и класс H2OAutoML, как и в любой другой библиотеке, и инициализировать локальный кластер H2O (для этой статьи я использую Google Colab).
import h2o from h2o.automl import H2OAutoML h2o.init()
Затем нам нужно загрузить данные, это можно сделать прямо в «H2OFrame» или (как я сделаю для этого датасета) в pandas DataFrame, чтобы мы могли применить label encoding и затем преобразовать их в H2OFrame. Как и многие вещи в H2O, H2OFrame работает очень похожим образом на Pandas DataFrame, но с небольшими отличиями и другим синтаксисом.
# Load data into H2O path = "./gdrive/My Drive/Mushrooms/mushrooms.csv" # df = h2o.import_file(path=path, header =1) df = pd.read_csv(path) labelEncoder = preprocessing.LabelEncoder() for col in df.columns: df[col] = labelEncoder.fit_transform(df[col]) df = h2o.H2OFrame(df) df = df.asfactor()
Хотя AutoML будет выполнять на начальных этапах большую часть работы за нас, важно, чтобы у нас все еще было хорошее понимание данных, которые мы пытаемся проанализировать, чтобы мы могли опираться на его работу.
df.describe ()
Подобно функциям в sklearn, мы можем создать разделение на train и test, чтобы можно было проверить работу модели в невидимом (test) датасете, чтобы предотвратить переобучение. Важно отметить, что при разделении H2O-фреймов не происходит точного разделения. Он предназначен для работы с большими данными с использованием метода вероятностного разделения, а не точного разделения. Например, при указании разделения 0,70/0,15 H2O будет производить разделение train/test с ожидаемым значением 0,70/0,15, а не точным 0,70/0,15. Для небольших датасетов размеры результирующих разбиений будут отличаться от ожидаемого значения больше, чем для больших данных, где они будут очень близки к точным.
train, test, valid = df.split_frame ( ratios = [ .7 , .15 ])
Затем нам нужно получить имена столбцов для датасета, чтобы мы могли передать их в функцию. В AutoML есть несколько параметров, которые должны быть определены: x, y, training_frame и validation_frame, из которых y и training_frame — обязательные, а остальные не являются обязательными. Вы также можете настроить значения для max_runtime_sec и max_models. max_runtime_sec является обязательным параметром, а max_model — необязательным. Если вы не передаете какой-либо параметр, он принимает значение NULL по умолчанию. Параметр x является вектором признаков из training_frame. Если вы не хотите использовать все признаки из переданного фрейма, вы можете пропустить параметр x.
Для решения этой проблемы мы собираемся использовать все параметры в датафрейме x (кроме целевого) и установить значение max_runtime_sec в 10 минут (некоторые из этих моделей занимают много времени). Теперь пришло время запустить AutoML:
y = "class" x_train = train.columns x_train.remove(y) aml = H2OAutoML(max_runtime_secs=600, seed = 1) aml.train(x = x_train, y = y, training_frame = train)
Здесь была указана функция для запуска 10 минутного периода обучения, но вместо этого можно было указать максимальное количество моделей. Если вы хотите настроить процесс работы AutoML, есть также множество дополнительных параметров, которые вы можете передать для этого:
- validation_frame: Этот параметр используется для ранней остановки отдельных моделей в AutoML. Это датафрейм, который вы передаете для проверки модели, или он может быть частью обучающих данных, если вы их не пропустили.
- leaderboard_frame: Если указано, модели будут оцениваться в соответствии с этими значениями вместо использования показателей кросс-валидации. Опять же, значения являются частью обучающей выборки, если они не пропущены вами.
- nfolds: количество фолдов в k-fold кросс-валидации. По умолчанию 5, может способствовать снижению производительности модели.
- fold_columns: Указывает индекс для кросс-валидации.
- weights_column: Если вы хотите указать весовые коэффициенты для определенных столбцов, вы можете использовать этот параметр. Назначение веса 0 означает, что вы исключаете столбец.
- ignored_columns: Обратно параметру x.
- stopping_metric: Указывает метрику для ранней остановки поиска в сетке. По умолчанию для моделей используется значение logloss для классификации и абсолютное отклонение для регрессии.
- sort_metric: Параметр для сортировки моделей списка лидеров. По умолчанию используется метрика AUC для бинарной классификации, mean_per_class_error для многоклассовой классификации и абсолютное отклонение для регрессии.
После запуска моделей вы можете посмотреть, какие модели работают лучше всего, и рассмотреть их для дальнейшего изучения.
lb = aml.leaderboard lb.head()

Чтобы убедиться, что модель не была переобучена, мы теперь запускаем ее на тестовых данных:
preds = aml.predict(test)
Результаты
AutoML выдал значения accuracy и F1-score — 1,0 на тестовых данных, что означает, что модель не была переобучена.
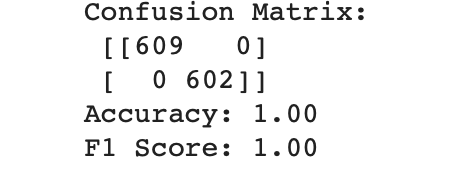
Очевидно, что это исключительный случай для AutoML, поскольку мы не можем улучшить accuracy до 100% на нашем тестовом датасете без тестирования большего количества данных. Глядя на многие из кернелов, представленных на Kaggle для этого датасета, похоже, что многие люди (и даже бот Kaggle Kernel) также смогли получить тот же результат, используя традиционные методы машинного обучения.
Последующая работа
Следующим шагом будет сохранение обученной модели. Существует два способа сохранить модель лидера — бинарный формат и формат MOJO. Если вы используете свою модель в production, то рекомендуется использовать формат MOJO, так как она оптимизирована для использования в производстве.
Теперь, когда вы нашли лучшую модель для данных, можно провести дальнейшее исследование по шагам, которые повысят производительность модели. Возможно, лучшая модель на тренировочных данных переобучена, и для тестовых данных предпочтительнее другая топ-модель. Возможно, для некоторых моделей данные лучше подготовить или отобрать только наиболее важные признаки. Многие из лучших моделей в H2O AutoML используют ансамблевые методы, и, возможно, модели, используемые в ансамблях, могут быть доработаны.
Хотя AutoML сам по себе не принесет вам первенство в соревнованиях по машинному обучению, его определенно стоит рассмотреть как дополнение к вашим смешанным и сложенным моделям.
AutoML может работать с различными типами датасетов, включая бинарную классификацию (как показано здесь), многоклассовую классификацию, а также работать с задачами регрессии.
Выводы

AutoML — отличный инструмент, который помогает (а не заменяет) работу, выполняемую учеными в области данных. Я с нетерпением ожидаю увидеть достижения, которые могут быть сделаны в средах AutoML, и как они могут принести пользу всем нам как ученым, а также организациям, которые они обслуживают. Конечно, одно автоматизированное решение не может превзойти творческий потенциал человека, например, когда дело доходит до инженерии признаков, но AutoML — это инструмент, который стоит изучить в вашем следующем проекте с анализом данных.