
Исследователи из Google AI измерили гендерные корреляции в NLP моделях. Они протестировали BERT и его аналог ALBERT на наличие корреляций, связанных с гендером. Исследователи опубликовали набор рекомендаций по тестированию языковых моделей на наличие гендерных смещений. Исследователи планируют опубликовать набор весов для NLP-архитектур, которые сохраняют state-of-the-art точность и при этом сокращают количество содержащихся в них гендерных корреляций.
Описание проблемы
Нейросетевые языковые модели являются state-of-the-art архитектурами для задач обработки естественного языка. Широкое применение таких моделей накладывает на исследователей обязательства по тестированию моделей на наличие закодированных в модели стереотипов из реального мира. Это связано с тем, что информация из предобученной модели повлияет на результаты модели на целевой задаче.
Измерение корреляций
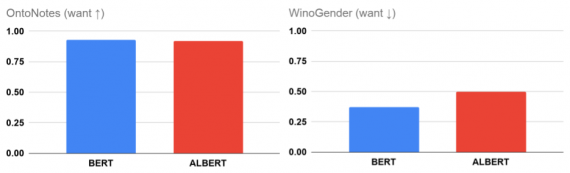
Исследователи обучили BERT и его аналог ALBERT на задаче разрешения кореференции. А затем измерили качество моделей на датасете OntoNotes. Обе модели выдают близкую к 100% F1-меру. После этого они проверили модели на наличие в них гендерных стереотипов касательно профессий на датасете WinoGender. Оказалось, что обе модели на ~20% содержат в себе гендерные смещения. Это является нежелательным, что бы модель выдавала предсказания, опираясь на априорные корреляции, которые она выучила из обучающих данных, а не извлекла из тестовых.
Рекомендации по обучению устойчивых моделей
Исследователи рекомендуют следующие действия для повышения устойчивости NLP моделей к смещениям:
- Оценивать нежелательные корреляции;
- Осторожно менять конфигурацию моделей. Например, повышение уровня дропаута привело к значительному снижению количества гендерных корреляций в данных;
- Напрямую использовать стратегии для снижения нежелательных корреляций. Например, аугментация данных или регуляризация сети
