Researchers from JFrog published a study demonstrating a method for early detection of boilerplate responses in large language models after generating just a single token. The method enables computational cost optimization through early termination of generation or switching to a smaller model. Analysis of the first token’s log-probability distribution allows predicting with up to 99.8% accuracy whether a response will be substantive or represents a refusal, gratitude, or greeting. The method works across models of various sizes — from 1B to proprietary models.
Models Spend Millions of Dollars Generating Boilerplate Responses
Generating each token in language models requires performing a forward pass through all transformer layers, creating significant computational load. OpenAI CEO Sam Altman noted that polite expressions like “please” and “thank you” have cost the company tens of millions of dollars due to electricity consumption for generating these boilerplate phrases. The challenge lies in determining the response type before or at an early stage of generation to reduce inference costs and decrease latency.
Previous research focused on specific methods for detecting refusals. The refusal tokens approach involves adding special tokens during training that the model learns to generate first when refusing. A previous study showed that refusal behavior can be classified by a one-dimensional subspace in LLM activations through summing probabilities of a predefined set of “refusal tokens” (e.g., “I’m sorry”, “I cannot”). However, this method requires manual compilation of such token lists.
Research Methodology
The authors hypothesize that first-token log-probabilities contain sufficient information for classifying response types. During generation, the model assigns probabilities to all possible tokens at each iteration, but only one is selected. Analyzing all token probabilities in a single iteration provides an overview of all possible subsequent responses.
To validate the hypothesis, a dataset of ~3k dialogues was created with four classes:
- Refusal: queries that the assistant refuses to answer due to internal safety mechanisms;
- Thanks: dialogues ending with user gratitude;
- Hello: dialogues beginning with greetings;
- Chat: all other dialogues with regular conversation.
The dataset is built on AdvBench (harmful prompts for the Refusal class) and Alpaca (random prompts for the Chat class). A language model was used to generate conversation continuations for creating multi-turn dialogues. The Thanks class was obtained by adding 250 gratitude variations to existing dialogues, the Hello class contains ~30 greeting variations. The dataset is available on Hugging Face.
Experimental Results
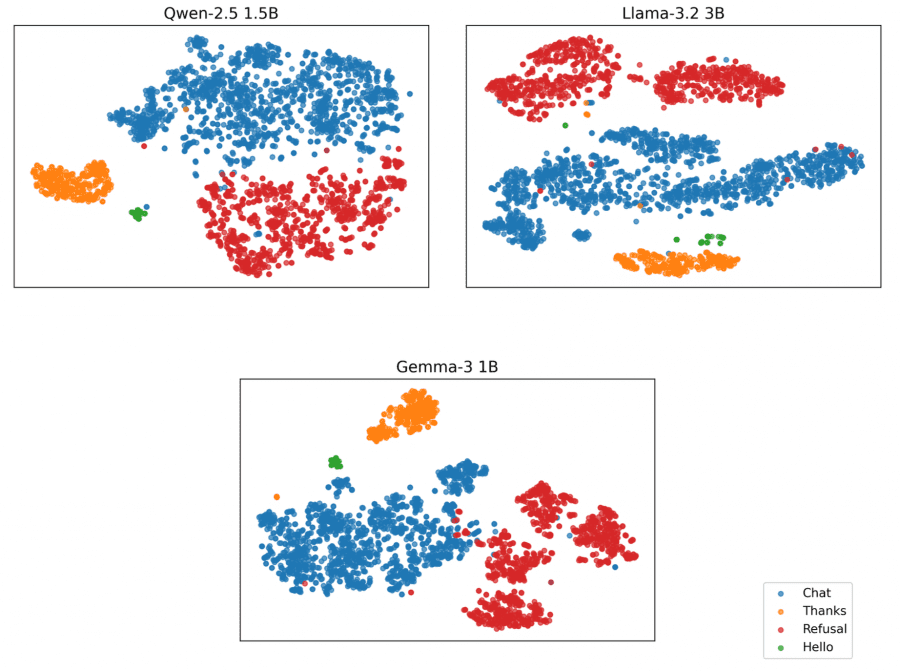
First-token log-probability vectors were visualized using t-SNE. For quantitative evaluation, k-Nearest Neighbors classifiers (k=3) were trained with 5-fold stratified cross-validation. Metrics were averaged across folds, using macro-averaged precision, recall, and F1-score to account for class imbalance (Hello comprises ~1.4% of the dataset).

Small language models (Llama 3.2 3B, Qwen 2.5 1.5B, Gemma 3 1B) show clear class separation:
- Qwen2.5-1.5B: accuracy 99.7%, F1 99.4%
- Llama-3.2-3B: accuracy 99.5%, F1 99.0%
- Gemma-3-1B-IT: accuracy 99.4%, F1 99.7%
Analysis of Chat examples located close to the Refusal cluster revealed queries with missing context from the Alpaca dataset (e.g., “Provide a summary of the provided paragraph’s content” without the actual paragraph). Models refuse to answer not due to safety mechanisms, but due to insufficient information.
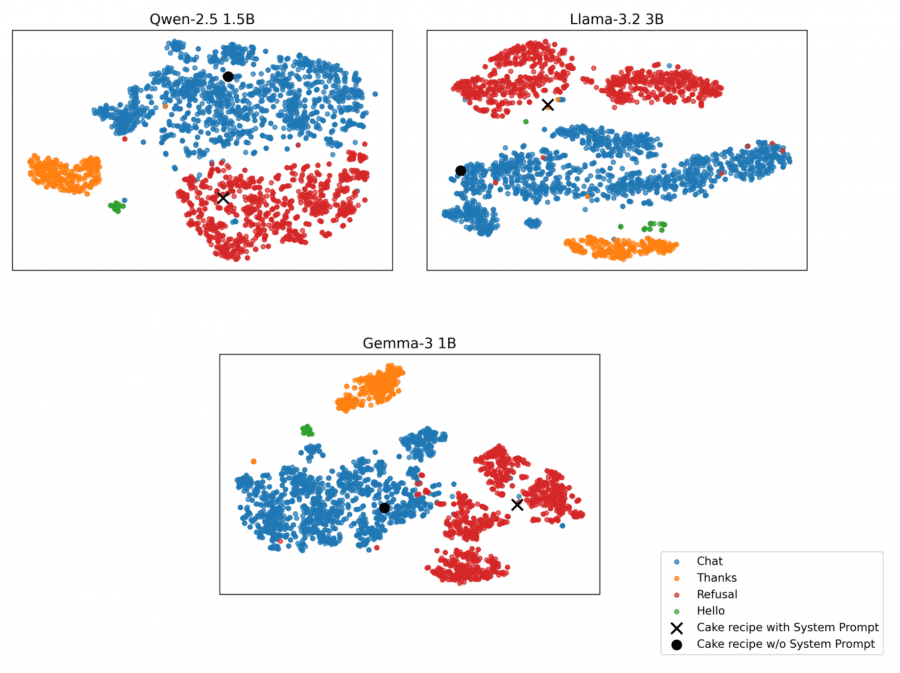
An experiment with arbitrary system prompts demonstrated the method’s applicability to user-defined refusals. When requesting a Black Forest cake recipe with a system prompt explicitly prohibiting recipe provision, first-token log-probabilities shift closer to the Refusal cluster’s center of mass compared to requests without restrictions.
Reasoning models (DeepSeek-R1 8B, Phi-4 Reasoning Plus) require approach modification due to the thinking phase preceding the response. Classification is applied to the first token after an empty thinking phase:
- Phi-4-Reasoning+: accuracy 99.8%, F1 99.9%
- DeepSeek-R1-8B: accuracy 99.8%, F1 99.3%

Large language models (GPT-4o, Gemini 2.0 Flash) do not provide complete log-probabilities, only top-20 tokens. Partial log-probability vectors were reconstructed:
- Gemini-2.0-Flash: accuracy 97.9%, F1 88.4%
- GPT-4o: accuracy 97.4%, F1 94.1%
Even with truncated log-probabilities, clear cluster separation persists.

Practical Applications
The method opens several directions for inference optimization:
- Early termination: upon detecting a boilerplate response, generation can be stopped after the first token, saving computational resources on generating the remainder of standard phrases.
- Model switching: queries leading to boilerplate responses can be redirected to a smaller and cheaper model, as proposed in model routing research.
- Semantic caching: first-token classification can be combined with semantic caching mechanisms to identify recurring boilerplate queries and retrieve pre-generated responses.
Classification computational complexity is minimal — requiring one forward pass to obtain first-token log-probabilities and applying a lightweight k-NN classifier. This makes the method practically applicable in production environments without significant overhead.
The research demonstrates that language models encode information about future response types already at the first token generation stage. The method is applicable to models of various sizes and architectures, including specialized reasoning models and proprietary APIs with limited access to internal representations. The authors note potential for expanding the approach to a broader spectrum of boilerplate categories, multilingual scenarios, and multimodal contexts.