Google has announced that they implemented an on-device neural network-based speech recognizer in Google Pixel’s virtual keyboard – Gboard.
The new speech recognizer is a significant improvement on Google’s cross-platform virtual keyboard. Based on a new model called RNN transducer (RNN-T), the speech recognizer can now reside on a phone and help to overcome problems with network latency, spottiness, and availability.
The model works at a character level, providing seamless speech-to-text experience for the users of Gboard.
“The model works at the character level, so that as you speak, it outputs words character-by-character, just as if someone was typing out what you say in real-time, and exactly as you’d expect from a keyboard dictation system.”, says Johan Schalkwyk, a fellow in Google’s Speech Team.
Moreover, the new offline speech recognizer offers a speedup of over four times at runtime and engineers at Google managed to compress the model so that it uses only 80MB of memory.
Speech-to-text systems are actually quite complex systems involving several different components such as acoustic models, language models etc. The main challenge recently was not the system’s ability to transcribe or state-of-the-art accuracy but mostly architectural constraints to be able to support real-time voice transcription.
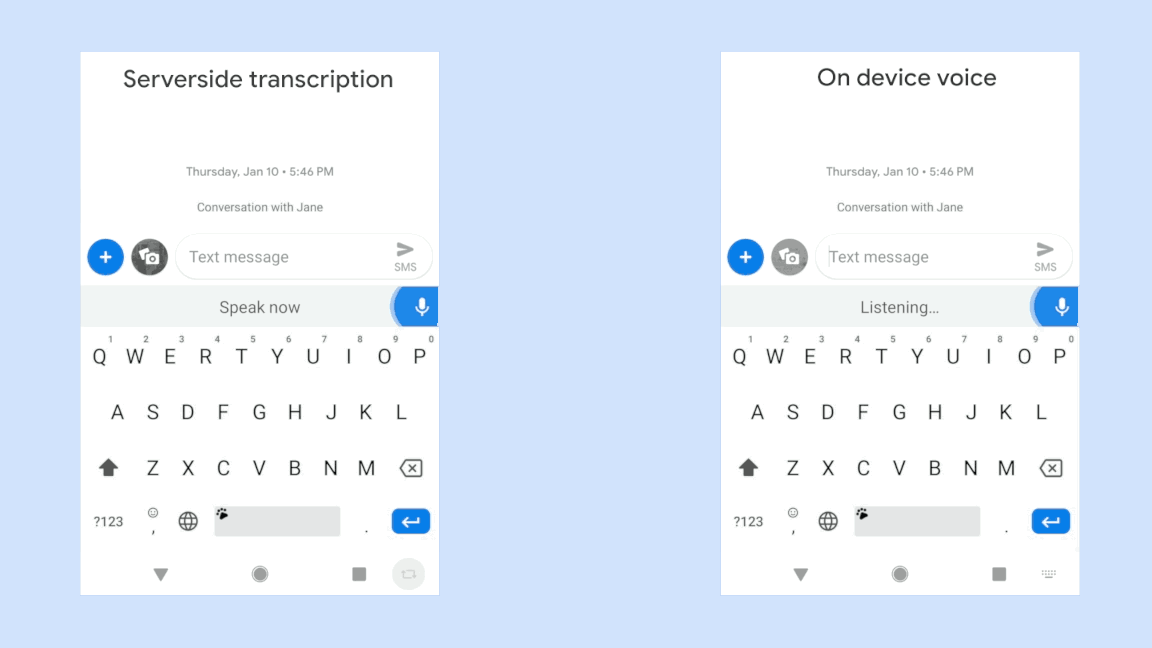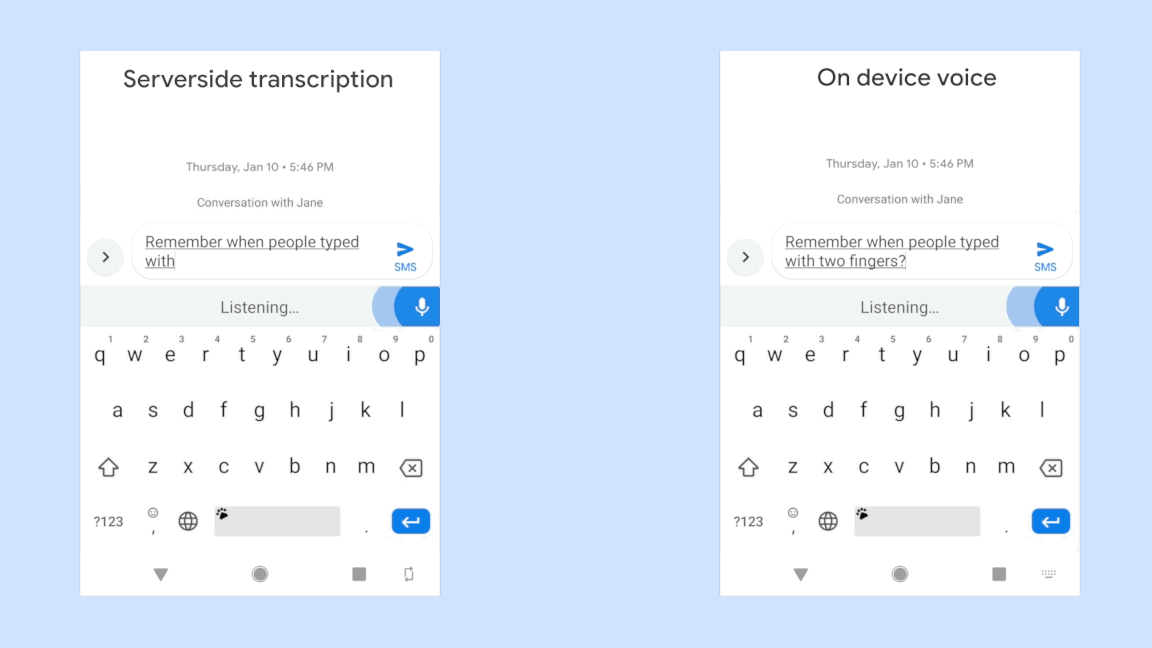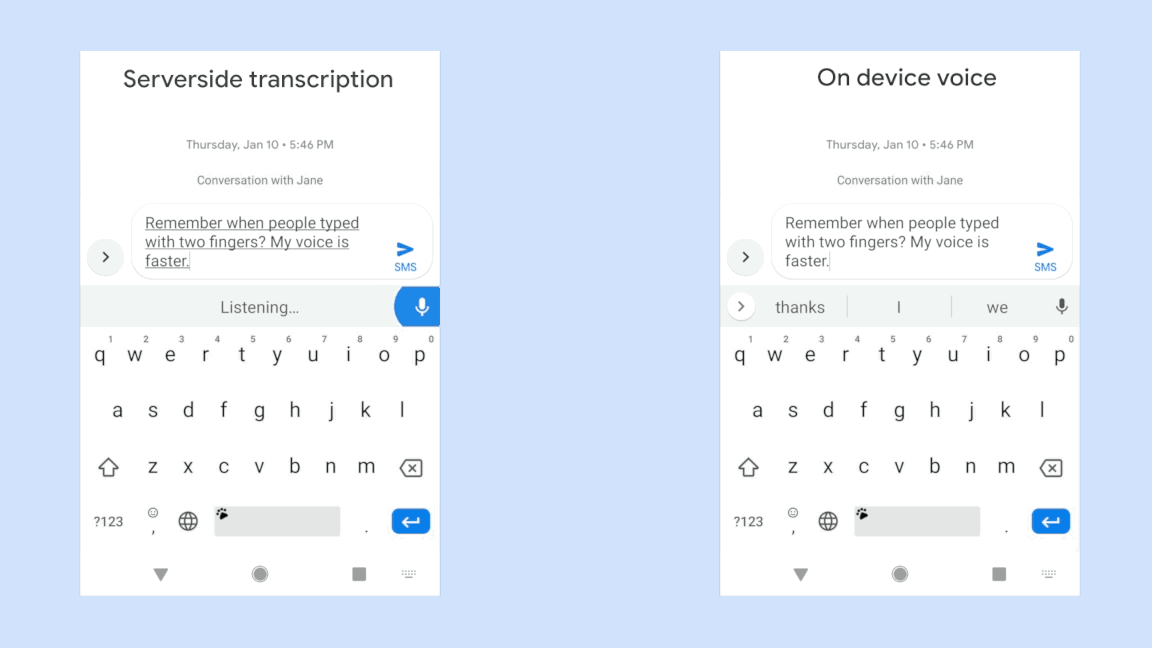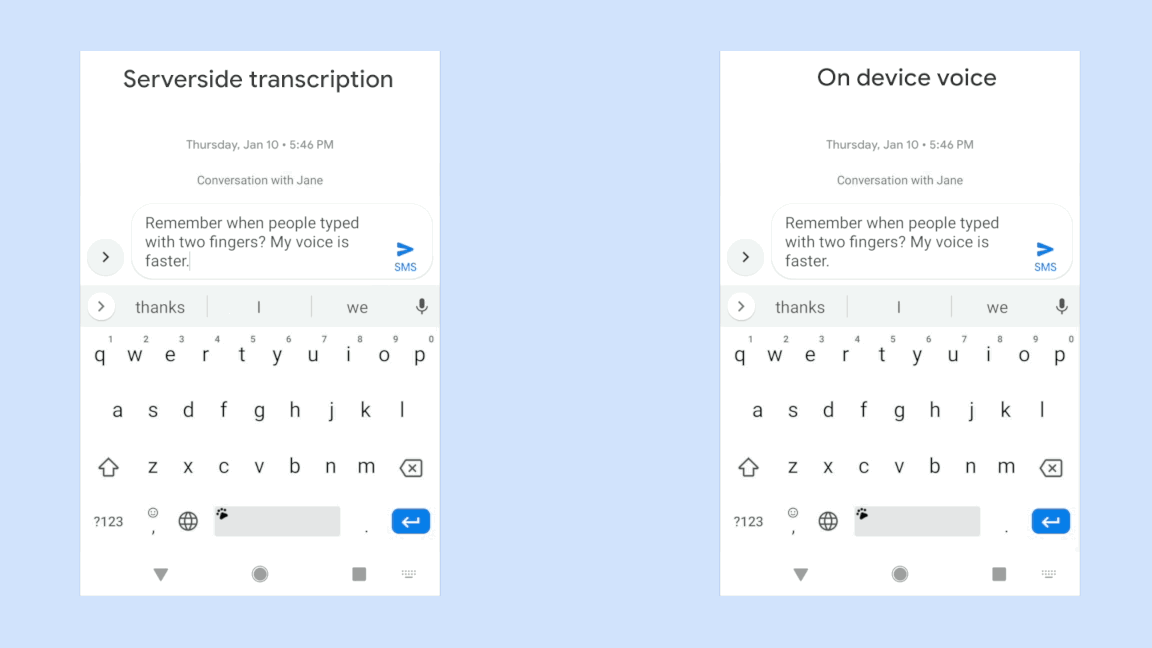
With the RNN-T model, it was made possible to deploy and seamlessly use such a system on a portable device like a smartphone.
For the moment, the on-device speech recognition feature is available only on Google’s Pixel phones. The used recurrent neural network model was presented recently in the paper “Streaming End-to-End Speech Recognition for Mobile Devices”. More about Google’s new speech recognizer can be read at Google’s AI blog.


