The AMAP-ML team has published DreamX-World 1.0, an interactive generative world model that turns text or an image into a controllable video with precise camera control, memory of previously visited scenes, and support for events triggered by text commands. The model works across photorealistic, game-style, and stylized visual domains. The project is fully open: the model weights with 5B parameters are available on Hugging Face, the code is on GitHub, and generation samples are on the project page. The base model is initialized from Wan2.2-TI2V and fine-tuned in stages: first for camera control, then for long-term scene memory, event control, and autoregressive generation of long videos. On eight RTX 5090 GPUs the model runs at up to 16 FPS in streaming mode.
World models are already finding use in several areas. In gaming and simulation, they generate environments on the fly without manually building geometry in an engine — the authors compare their work to GameNGen and GameGen-X, neural networks for real-time game simulation. In robot training, such a model serves as an environment simulator for training agents without contact with the real physical world, where accurate memory of scene geometry is critical. In architectural visualization and virtual tours, the ability to control the camera precisely and keep the scene consistent across repeated passes is in demand. For researchers in generative models, the paper offers several technical insights regardless of application: a way to speed up models with projective camera positional encoding, and an evaluation protocol for memory through repeated location visits that could become a standard for future world models.
What Problems DreamX-World 1.0 Solves: Camera Control, Memory, and Generation Speed
Ordinary diffusion video models produce nice short clips, but they cannot respond to user actions or remember what was in the frame earlier. The authors identify three main technical challenges.
- The first is camera control: the model must translate a given trajectory into a consistent change of viewpoint regardless of scene scale, and the conditioning mechanism must not slow down computation significantly;
- The second is long-term memory: when a previously visited area leaves the context window, the model may render it completely differently upon revisit. Autoregressive generation only makes the problem worse, because small prediction errors accumulate and lead to drift in appearance and color tone;
- The third is speed: continuous interaction requires low latency, while aggressive distillation degrades video quality and controllability.
DreamX-World Dataset: Data From Unreal Engine, Real-World Video, and Games
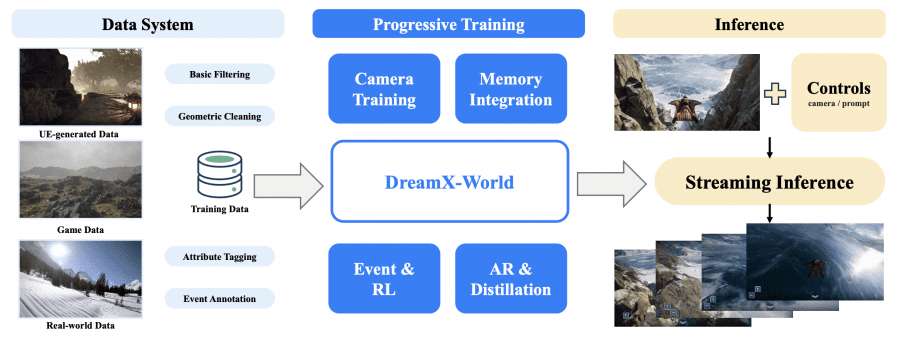
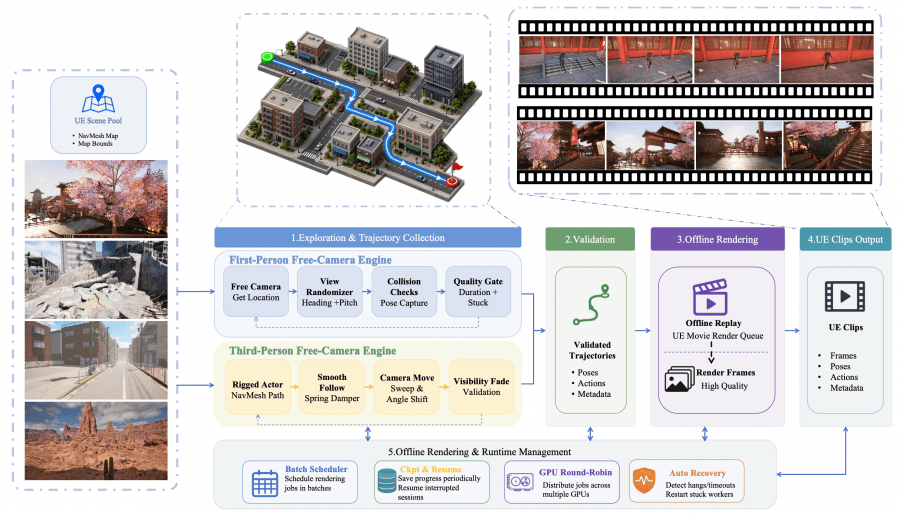
From Unreal Engine 5 they obtained synthetic first-person and third-person videos with precise camera poses, action vectors in the form of keyboard-style signals (WASD for translation, IJKL for rotation), and metadata. For this they built a two-stage pipeline: trajectories are collected and validated in real time via NavMesh, then rendered offline at high quality through the UE Movie Render Queue.
Real-world videos were taken from the SpatialVID, RealEstate10K, Sekai, and DL3DV datasets. Camera poses for them were sparsely recovered via MegaSaM with subsequent interpolation. Game data came from Sekai-Game and OmniWorld-Game, with poses exported directly from the engines.
The entire dataset went through three stages of cleaning:
- basic filtering removed clips with overlaid text, black borders, low fps, and nearly static content;
- geometric cleaning normalized trajectories and removed translation spikes, fast rotations, and vertical jitter;
- attribute tagging added a quality score, motion intensity, scene category, and visual style to each clip. It also separately marked whether a clip contained only camera motion (3D) or object motion as well (4D).
E-PRoPE: Efficient Camera Control for Video Diffusion Models
For camera control the authors adopted the PRoPE (Projective Positional Encoding) method: camera geometry is encoded directly into the transformer’s self-attention mechanism. The positional encoding matrix for each token consists of two blocks — one carries the projective camera geometry (world coordinates projected into the image), the other replicates standard rotary positional embeddings (RoPE).
The problem with the original PRoPE is that it adds extra attention blocks to every layer of the Diffusion Transformer (DiT), almost doubling the computational cost. The authors proposed a lightweight variant — E-PRoPE: first the spatial resolution of the tokens is downsampled, attention is computed on the reduced set, and the result is then upsampled back and added to the original transformer output.
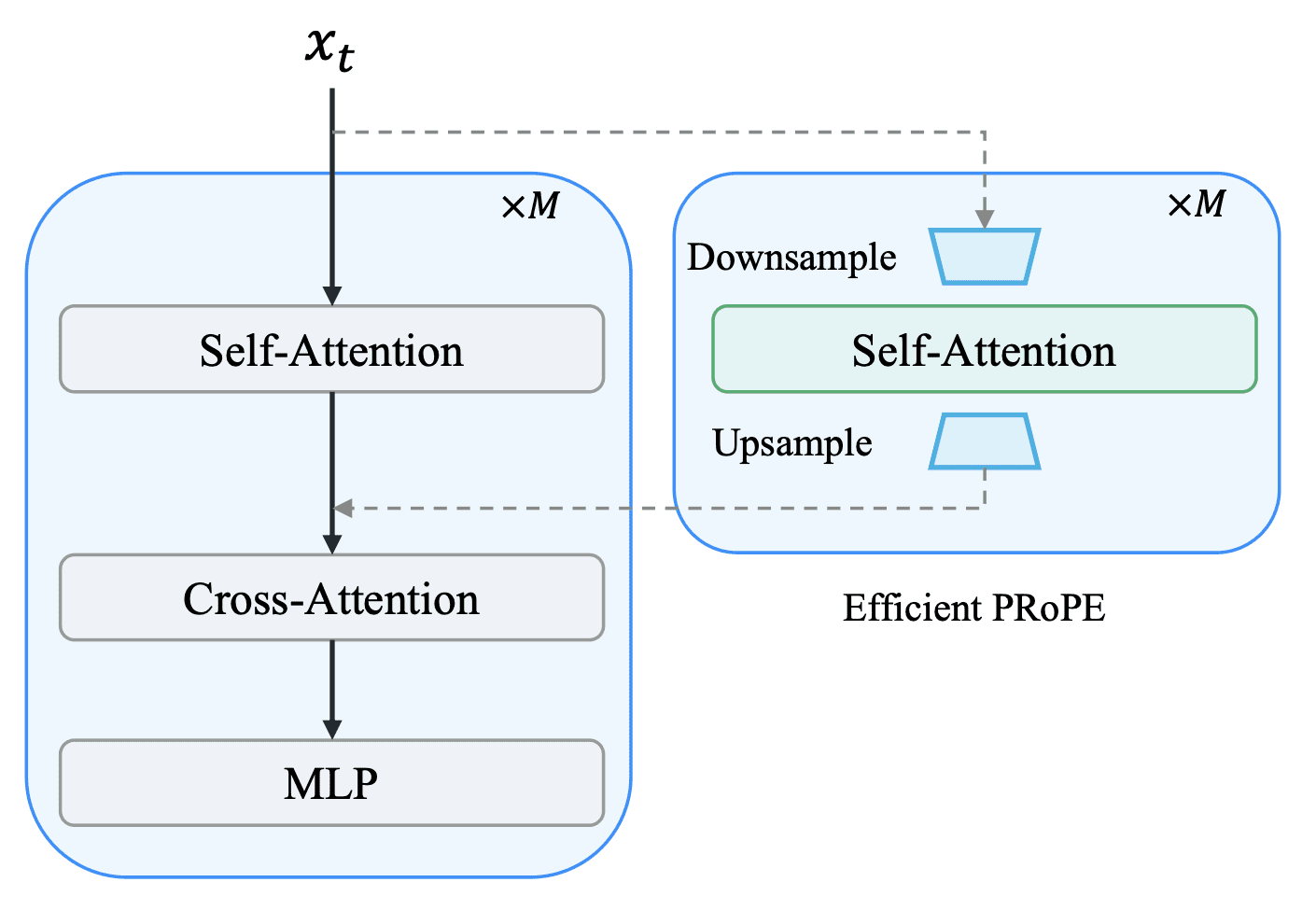
For a 5-second video at 720p, the variational autoencoder (VAE) of the Wan2.2 5B model encodes it into 18,480 tokens, while E-PRoPE works with only 4,096 of them — a more than 4.5x reduction. Training time drops by about 50%, generation time by 30%, and camera control quality remains comparable to full PRoPE.

Memory-Conditioned Scene Persistence: How the Model Remembers Visited Locations
When a user leaves a room and comes back, the model might paint an entirely different room — the earlier frames have already left the context window. To address this, the authors added a Memory-Conditioned Scene Persistence stage. Alongside recent frames, the DiT is also fed memory frames — earlier key frames relevant to the current viewpoint. The model’s input sequence is a concatenation of memory frames, recent history, and target noisy frames.
The key point is how memory frames are selected. The authors use camera geometry: for each target frame, they search the history for frames with the maximum view overlap, i.e., frames where the camera was looking at roughly the same place. This is fundamentally better than simply taking the nearest frames in time, because when returning to a previously visited area, the relevant frames may be far in the past. Each memory frame, when packed in, receives a RoPE embedding corresponding to its original temporal position in the video — this prevents confusion about how “long ago” that frame was.
Another problem is called exposure bias: during training the model sees clean frames from the dataset, while during inference it receives its own generated frames with accumulated errors. To address this, the authors apply the approach from Stable Video Infinity: during training, the conditioning frames are deliberately corrupted with a small amount of noise, so the model learns to work with imperfect context instead of trusting it unconditionally.
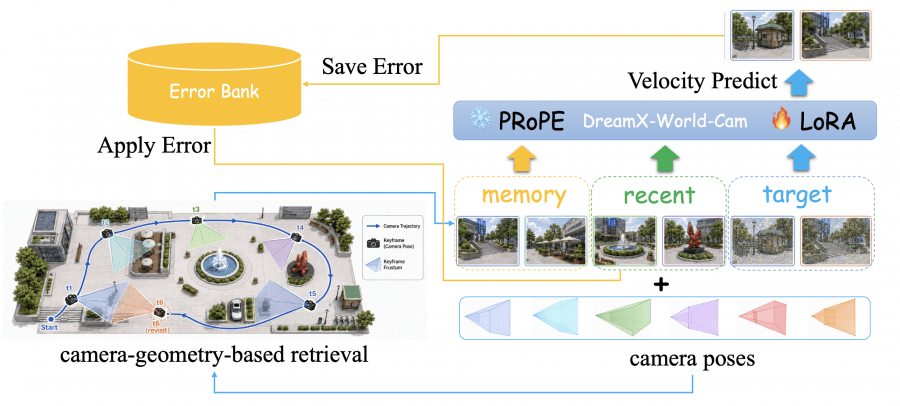
Event Instruction Tuning: Controlling Multiple Objects in a Scene by Text
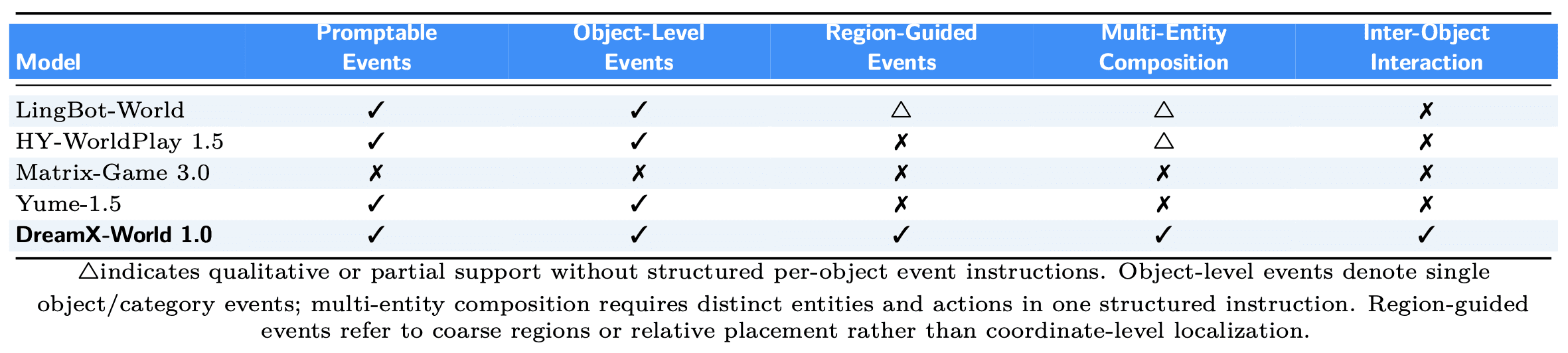
Existing interactive world models can respond to text prompts, but they handle events either only at the level of the whole scene, or with one object at a time. DreamX-World 1.0 introduces Event Instruction Tuning — fine-tuning on structured annotations that describe several objects with distinct actions and interactions between them within a single instruction. The annotations are organized hierarchically: a global description summarizes the scene as a whole, while at the level of individual entities, each record specifies exactly what is happening, where in the frame, and during which time interval.
DreamX-World 1.0 is the only publicly available model supporting all five levels of event control: reacting to text prompts, object-level events, region-guided event placement, combining multiple entities in a single instruction, and interaction between objects. Competitors partially cover the first two or three levels but do not provide full control over several interacting objects at once.
Comparison of event control: DreamX-World is the only model with full support for all five levels, including composable events:
DMD Distillation and RL: How DreamX-World Generates Video in Real Time
The base diffusion model is bidirectional: for streaming generation it needs to be turned into an autoregressive one, where each new piece of video is generated from the already-produced previous pieces. The authors do this through causal forcing: the model is trained to generate each chunk from the previous ones while staying close to the original distribution of the bidirectional model. It is additionally fine-tuned on long sequences with Infinity-RoPE to reduce problems with identity drift and random background changes.
To reduce the number of diffusion steps, they apply DMD distillation (Distribution Matching Distillation): an autoregressive student model is trained to mimic the outputs of the bidirectional teacher model over local temporal windows from long videos. After distillation, video quality and camera following degrade, so a reinforcement learning stage is added: two reward models evaluate camera control accuracy and the visual quality of short clips, while KL regularization keeps the model close to the distilled state and prevents diversity collapse.
Inference Optimization: SageAttention, ParaVAE, and 16 FPS on Eight GPUs
The video is generated in chunks: each chunk starts from noise, is denoised using the text prompt, the chunk-relative camera trajectory, and the accumulated KV cache, and then writes its tokens into the cache for subsequent chunks. The camera position is recalculated anew for each video segment: the first segment uses its own first frame as the reference point, and each subsequent one uses the last frame of the previous segment. This keeps the camera control signal from gradually weakening over long videos.
Denoising in the DiT is accelerated through several methods at once: attention layers are converted to 8-bit precision via SageAttention, fully connected layers to the 8-bit FP8 format via AngelSlim, long token sequences are distributed across multiple GPUs via sequence parallelism, and at stable timesteps already-computed intermediate results are reused via the TeaCache method instead of being recalculated. The VAE decoder from Matrix-Game 3.0 is pruned by 75% in parameter count, so decoding a single video segment takes about 0.25 seconds, and the ParaVAE method additionally distributes decoding across frame patches between GPUs. An asynchronous pipeline overlaps the decoding of segment k with the denoising of the next segment k+1, so the VAE latency is barely noticeable against the diffusion computation. As a result, on eight RTX 5090 GPUs the model delivers up to 16 frames per second.
DreamX-World 1.0 vs. HY-WorldPlay 1.5 and LingBot-World: Benchmark Results
DreamX-World-1.0-5B was compared against HY-WorldPlay 1.5 (8B parameters) and LingBot-World (14B parameters) across three benchmarks.
On the basic evaluation of 5-second rollouts, DreamX-World scores 73.75 on camera control and 84.76 on the overall score, versus 80.79 and 80.45 for the competitors. This is despite the model having the fewest parameters of the three. On long rollouts of about 30 seconds, the advantage holds: the artifact score for the competitors drops from ~65–70 to 12–14, while for DreamX-World it drops from 73.75 to 17, and the overall score stands at 70.41 versus 68.85 and 67.43.

To test memory, the authors build trajectories with explicit repeated visits to previously shown points in space and compare frames from the first and second visit across five levels of metrics: pixel-level (PSNR, SSIM), perceptual (LPIPS), semantic (DINO-Sim), place recognition (VPR-Sim), and geometric (SP-Match). All metrics are computed as a gain over pairs of frames without a repeated visit and with a similar time gap, so as not to inflate the score for models with slowly moving cameras. DreamX-World wins on four out of five metrics: the pixel-level PSNR gain is 3.92 versus 3.19 for HY-WorldPlay and 0.61 for LingBot-World, and the DINO-Sim gain is 0.246 versus 0.200 and 0.090 respectively.

In a blind pairwise study, DreamX-World wins against HY-WorldPlay in 57.5% of cases and against LingBot-World in 61.9% on overall preference. On visual quality — 57.5% and 61.3%, on artifacts — 59.4% and 56.2%. The only area with the smallest advantage is camera control, where there are many ties: the perceived quality of control is roughly the same across all three.

The main conclusion of the paper: a model with 5B parameters outperforms competitors with 8B and 14B parameters on all key metrics while running in real time. The authors explicitly state that world modeling is a complex problem: data preparation, staged training, evaluation, and inference optimization must all be designed together rather than separately. If only the architectural part is solved while inference remains slow, the model stays a laboratory prototype unfit for interactive use. If the focus is only on speed and scene memory is neglected, the user will see the environment change with every repeated pass, and the sense of a “real world” disappears. It is precisely the combined work across all components — data from three different sources, distillation for speed, geometric memory for consistency, and RL for restoring quality after distillation — that produces a model that can actually be used in real time, rather than just demonstrated on static screenshots.