
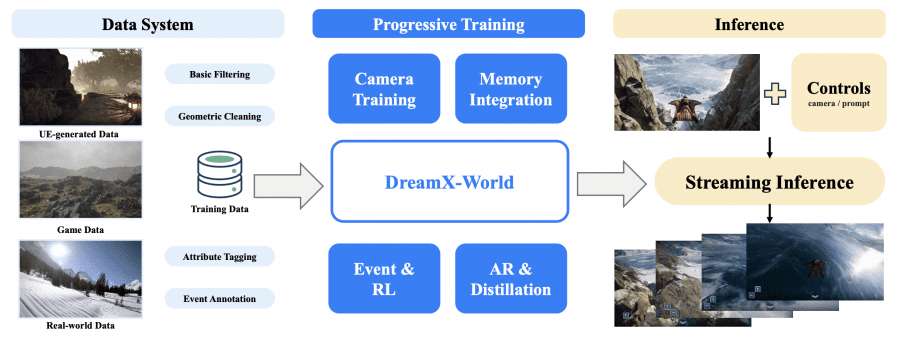
Команда AMAP-ML опубликовала DreamX-World 1.0 — интерактивную генеративную модель мира, которая превращает текст или изображение в управляемое видео с точным контролем камеры, памятью о ранее посещённых сценах и поддержкой событий по текстовым командам. Модель работает в фотореалистичных, игровых и стилизованных визуальных доменах. Проект полностью открытый: веса модели на 5B параметров доступны на Hugging Face, код на GitHub, а примеры генераций на странице проекта. Базовая модель инициализирована из Wan2.2-TI2V и дообучена поэтапно: сначала для управления камерой, затем для долгосрочной памяти сцены, событийного управления и авторегрессивной генерации длинных видео. На восьми GPU RTX 5090 модель работает со скоростью до 16 FPS в потоковом режиме.
Модели мира уже находят применение в нескольких областях. В играх и симуляции они генерируют окружения на лету без ручной прорисовки геометрии — авторы сравнивают свою работу с GameNGen и GameGen-X, нейросетями для симуляции игр в реальном времени. В обучении роботов такая модель служит симулятором среды для тренировки агентов без контакта с реальным физическим миром, где точная память о геометрии сцены критична. В архитектурной визуализации и виртуальных турах востребована способность точно управлять камерой и сохранять консистентность сцены при повторных проходах. Для исследователей генеративных моделей статья даёт несколько технических инсайдов независимо от применения: способ ускорить модели с проективным позиционным кодированием камеры и протокол оценки памяти через повторные посещения локаций, который может стать стандартом для будущих моделей мира.
Какие проблемы решает DreamX-World 1.0: управление камерой, память и скорость генерации
Обычные диффузионные видеомодели делают красивые короткие клипы, но не умеют реагировать на действия пользователя и помнить, что было в кадре раньше. Авторы выделяют три главные технические трудности.
- Первая — управление камерой: модель должна переводить заданную траекторию в согласованное изменение точки зрения вне зависимости от масштаба сцены, причём механизм кондиционирования не должен сильно замедлять вычисления;
- Вторая — долгосрочная память: когда ранее посещённая область выходит из контекстного окна, модель при повторном посещении может отрисовать её совершенно иначе. Авторегрессивная генерация только усугубляет проблему, потому что небольшие ошибки предсказания накапливаются и приводят к дрейфу внешнего вида и цветового тона;
- Третья — скорость: непрерывное взаимодействие требует низкой задержки, агрессивная дистилляция ухудшает качество видео и управляемость.
Датасет DreamX-World: данные из Unreal Engine, реальных видео и игр
Из Unreal Engine 5 получили синтетические видео от первого и третьего лица с точными позами камеры, векторами действий в формате клавиатурных сигналов (WASD для перемещения, IJKL для поворотов) и метаданными. Для этого разработали двухэтапный пайплайн: сначала в реальном времени собирают и валидируют траектории через NavMesh, потом рендерят офлайн с высоким качеством через UE Movie Render Queue.
Реальные видео взяли из датасетов SpatialVID, RealEstate10K, Sekai и DL3DV. Позы камеры для них восстанавливали разреженно через MegaSaM с последующей интерполяцией. Игровые данные получили из Sekai-Game и OmniWorld-Game с позами, экспортированными прямо из движков.
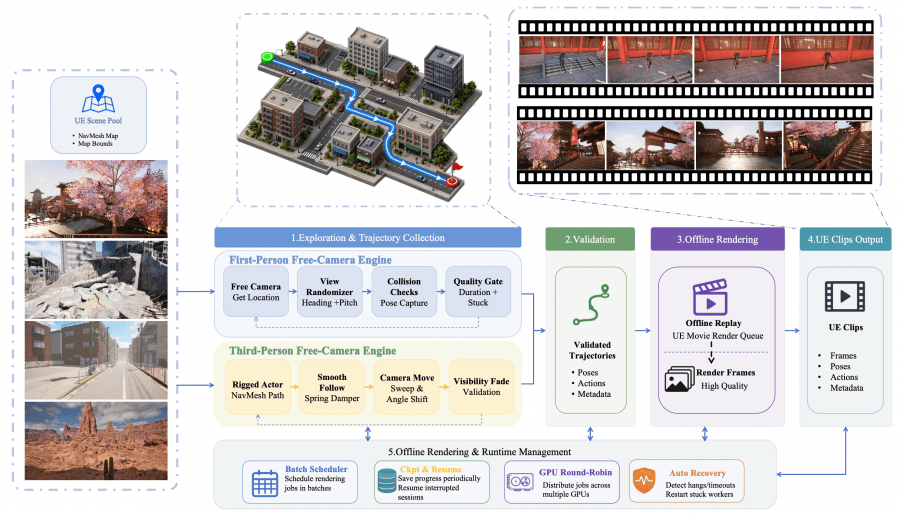
Весь датасет прошёл трёхэтапную очистку:
- базовая фильтрация убирала клипы с наложенным текстом, чёрными рамками, низким fps и почти статичным содержимым;
- геометрическая чистка нормализовала траектории и убирала скачки в трансляции, быстрые вращения и рывки по вертикали;
- атрибутная разметка добавляла к каждому клипу оценку качества, интенсивности движения, категорию сцены и визуальный стиль. Отдельно отмечали, есть ли в клипе только движение камеры (3D) или и движение объектов тоже (4D).
E-PRoPE: эффективное управление камерой в видеодиффузии
Для управления камерой авторы взяли метод PRoPE (Projective Positional Encoding): геометрию камеры кодируют прямо в механизм self-attention трансформера. Матрица позиционного кодирования для каждого токена состоит из двух блоков — один несёт проективную геометрию камеры (мировые координаты, спроецированные в изображение), второй — стандартные вращательные позиционные эмбеддинги RoPE.
Проблема исходного метода PRoPE в том, что он добавляет дополнительные блоки внимания к каждому слою диффузионного трансформера (DiT), почти вдвое увеличивая вычислительную стоимость. Авторы предложили облегчённый вариант — E-PRoPE: сначала понижают пространственное разрешение токенов, считают внимание на уменьшенном наборе, а затем повышают разрешение обратно и прибавляют результат к исходному выходу трансформера.
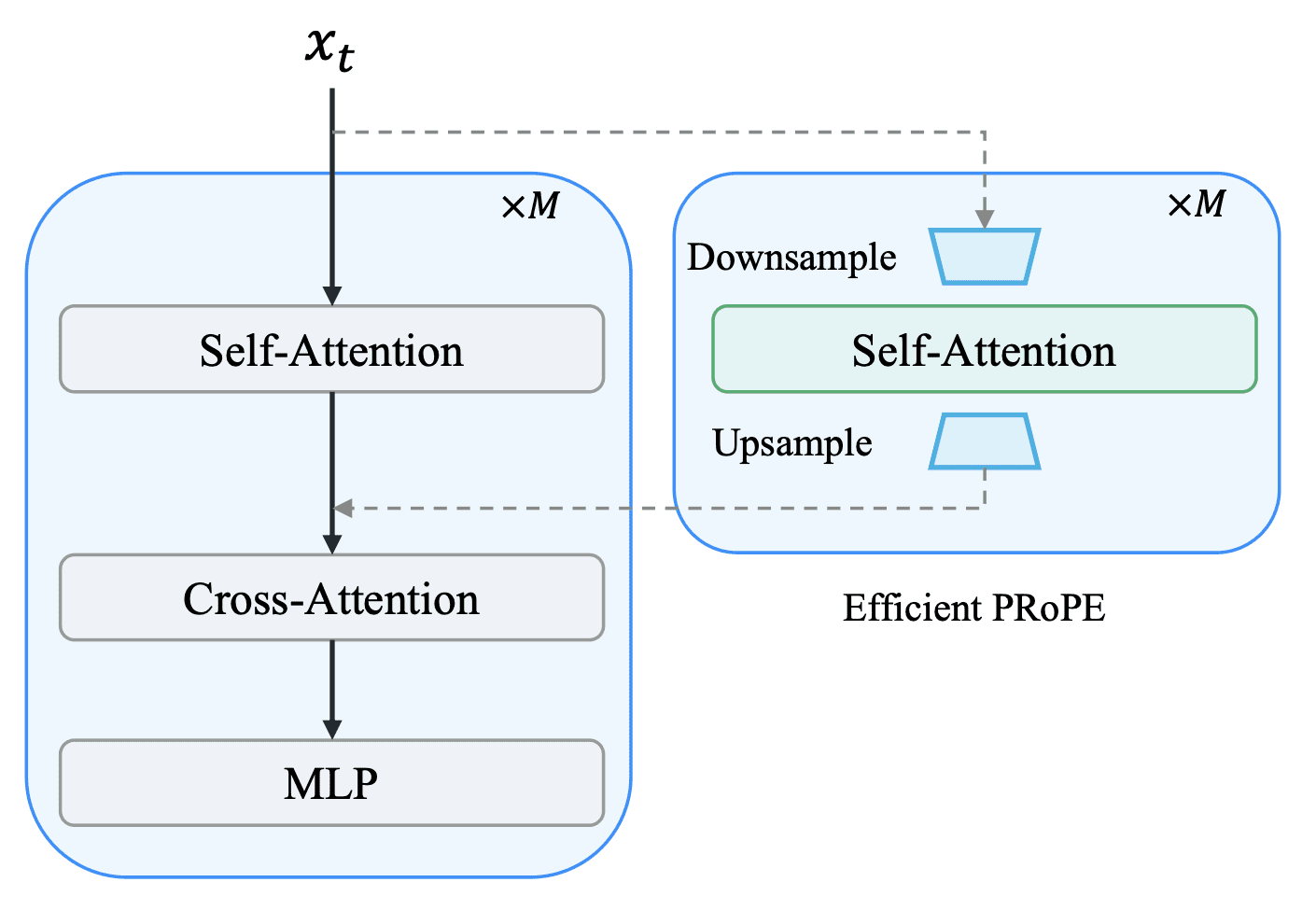
Для 5-секундного видео в разрешении 720p вариационный автокодировщик (VAE) модели Wan2.2 5B кодирует его в 18 480 токенов, а E-PRoPE работает только с 4096 из них — это более чем 4.5-кратное прореживание. Время обучения сокращается примерно на 50%, время генерации — на 30%, а качество управления камерой остаётся сопоставимым с полным PRoPE.

Memory-Conditioned Scene Persistence: как модель запоминает посещённые локации
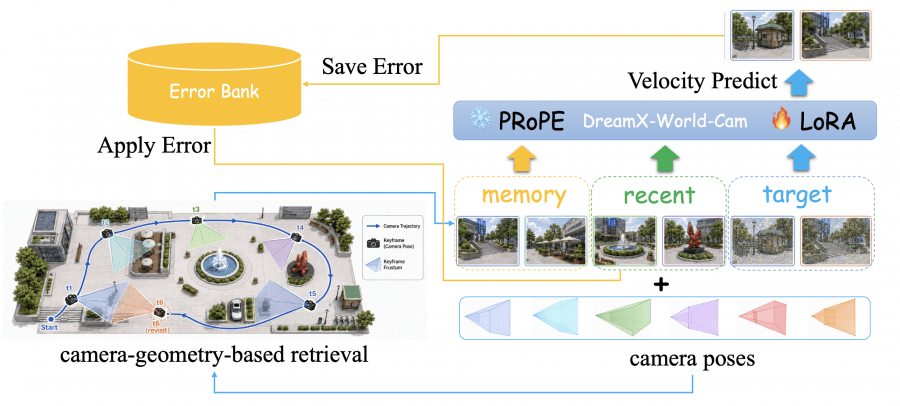
Когда пользователь уходит из комнаты и возвращается, модель может нарисовать совершенно другую комнату — прежние кадры уже вышли из контекстного окна. Для решения этой проблемы авторы добавили этап Memory-Conditioned Scene Persistence. Вместе с недавними кадрами в DiT подают ещё и кадры из памяти — более ранние ключевые кадры, релевантные текущей точке зрения. Входная последовательность для модели выглядит как конкатенация кадров памяти, недавней истории и целевых зашумлённых кадров.
Ключевой момент в том, как выбирать кадры из памяти. Авторы используют геометрию камеры: для каждого целевого кадра ищут в истории кадры с максимальным пересечением угла зрения (view overlap), то есть те кадры, где смотрели примерно туда же. Это принципиально лучше, чем просто брать ближайшие по времени кадры, потому что при возвращении в посещённую зону нужные кадры могут быть давно в прошлом. Каждый кадр памяти при упаковке получает RoPE-эмбеддинг, соответствующий его исходному временному положению в видео — это предотвращает путаницу с тем, насколько «давно» был этот кадр.
Ещё одна проблема называется exposure bias: во время обучения модель видит чистые кадры из датасета, а во время инференса получает собственные сгенерированные кадры с накопленными ошибками. Для её решения авторы применяют подход из Stable Video Infinity: во время обучения намеренно искажают кадры условия небольшим шумом, чтобы модель научилась работать с неидеальным контекстом и не доверяла ему безоговорочно.
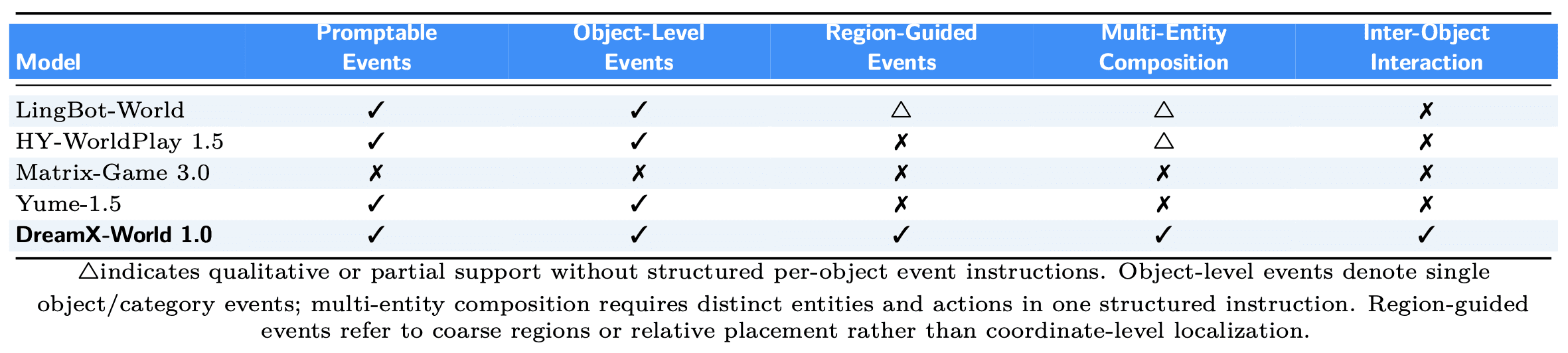
Event Instruction Tuning: управление несколькими объектами в сцене по тексту
Существующие интерактивные модели мира умеют реагировать на текстовые запросы, но работают с событиями либо только на уровне всей сцены, либо с одним объектом за раз. DreamX-World 1.0 вводит Event Instruction Tuning — дообучение на структурированных аннотациях, которые описывают несколько объектов с отдельными действиями и взаимодействиями между ними в рамках одной инструкции. Аннотации составлены иерархически: глобальное описание суммирует сцену в целом, а на уровне отдельных сущностей каждая запись указывает, что именно происходит, где в кадре и в какой временной интервал.
DreamX-World 1.0 — единственная публично доступная модель, поддерживающая все пять уровней событийного управления, включая комбинирование нескольких сущностей и взаимодействие между объектами. Конкуренты частично покрывают первые два-три уровня, но не дают полноценного управления несколькими взаимодействующими объектами одновременно.
Сравнение событийного управления, DreamX-World — единственная модель с полной поддержкой всех пяти уровней, включая составные события:
DMD-дистилляция и RL: как DreamX-World генерирует видео в реальном времени
Базовая диффузионная модель — двунаправленная: для потоковой генерации её нужно превратить в авторегрессивную, где каждый новый кусок видео генерируется из уже готовых предыдущих. Авторы делают это через causal forcing: модель обучается генерировать каждый чанк из предыдущих, оставаясь близкой к исходному распределению двунаправленной модели. Дополнительно дообучают на длинных последовательностях с Infinity-RoPE для снижения проблем с дрейфом идентичности и случайной сменой фона.
Для сокращения числа шагов диффузии применяют DMD-дистилляцию (Distribution Matching Distillation): авторегрессивная модель-студент обучается имитировать выходы двунаправленной модели-учителя на локальных временных окнах из длинных видео. После дистилляции качество видео и следование камере ухудшаются, поэтому добавляют этап обучения с подкреплением: две reward модели оценивают точность управления камерой и визуальное качество коротких клипов, а KL-регуляризация удерживает модель близко к дистиллированному состоянию и предотвращает коллапс разнообразия.
Оптимизация инференса: SageAttention, ParaVAE и 16 FPS на восьми GPU
Видео генерируется кусками: каждый чанк стартует из шума, денойзируется с учётом текстового промпта, чанк-относительной траектории камеры и накопленного KV-кэша, а потом записывает свои токены в кэш для следующих чанков. Положение камеры пересчитывается заново для каждого отрезка видео: первый отрезок берёт за точку отсчёта свой первый кадр, а каждый следующий — последний кадр предыдущего отрезка. Это не даёт сигналу управления камерой постепенно ослабевать на длинных видео.
Шумоподавление в DiT ускоряют сразу несколькими способами: слои внимания переводят в 8-битную точность через SageAttention, полносвязные слои — в 8-битный формат FP8 через AngelSlim, длинные последовательности токенов распределяют по нескольким GPU через sequence parallelism, а в стабильных временных шагах повторно используют уже посчитанные промежуточные результаты по методу TeaCache, не пересчитывая их заново. Декодер VAE из Matrix-Game 3.0 урезан на 75% по числу параметров, поэтому декодирование одного отрезка видео занимает около 0.25 секунды, а метод ParaVAE дополнительно распределяет декодирование по фрагментам кадра между GPU. Асинхронный конвейер совмещает во времени декодирование отрезка k с шумоподавлением следующего отрезка k+1, так что задержка VAE почти не ощущается на фоне вычислений диффузии. В итоге на восьми GPU RTX 5090 модель выдаёт до 16 кадров в секунду.
DreamX-World 1.0 против HY-WorldPlay 1.5 и LingBot-World: результаты тестов
DreamX-World-1.0-5B сравнивают с HY-WorldPlay 1.5 (8B параметров) и LingBot-World (14B параметров) по трём осям оценки.
На базовой оценке 5-секундных роллаутов DreamX-World набирает 73.75 по управлению камерой и 84.76 по итоговому баллу против 80.79 и 80.45 у конкурентов. Это при том, что модель имеет наименьшее число параметров из трёх. На длинных роллаутах около 30 секунд преимущество сохраняется: оценка за артефакты у конкурентов падает с 71.66 и 58.33 до 14.00 и 12.00, тогда как у DreamX-World — с 73.75 до 17.00, а итоговый балл составляет 70.41 против 68.85 и 67.43.

Для проверки памяти авторы строят траектории с явными повторными посещениями ранее показанных точек пространства и сравнивают кадры первого и повторного посещения по пяти уровням метрик: пиксельный (PSNR, SSIM), перцептивный (LPIPS), семантический (DINO-Sim), распознавание места (VPR-Sim) и геометрический (SP-Match). Все метрики считаются как прирост над парами кадров без повторного посещения с аналогичным временным разрывом, чтобы не завышать оценку у моделей с медленно движущейся камерой. DreamX-World выигрывает по четырём из пяти метрик: пиксельный прирост PSNR составляет 3.92 против 3.19 у HY-WorldPlay и 0.61 у LingBot-World, DINO-Sim прирост — 0.246 против 0.200 и 0.090 соответственно.

В слепом попарном исследовании DreamX-World выигрывает у HY-WorldPlay в 57.5% случаев и у LingBot-World в 61.9% по общему предпочтению. По визуальному качеству — 57.5% и 61.3%, по артефактам — 59.4% и 56.2%. Единственная область с минимальным преимуществом — управление камерой, где много ничьих: воспринимаемое качество управления у всех трёх примерно одинаково.

Главный вывод статьи: модель с 5B параметров обгоняет конкурентов с 8B и 14B по всем ключевым показателям и при этом работает в реальном времени. Авторы прямо указывают, что моделирование мира — это комплексная задача: подготовка данных, поэтапное обучение, оценка и оптимизация инференса должны проектироваться вместе, а не отдельно друг от друга. Если решить только архитектурную часть и оставить медленный инференс, модель останется лабораторным прототипом, не пригодным для интерактивного использования. Если сосредоточиться только на скорости и забыть про память сцены, пользователь будет видеть, как окружение меняется при каждом повторном проходе, и ощущение «настоящего мира» пропадёт. Именно совместная работа над всеми компонентами — данными из трёх разных источников, дистилляцией для скорости, геометрической памятью для согласованности и RL для восстановления качества после дистилляции — позволяет получить модель, которой реально можно пользоваться в реальном времени, а не только демонстрировать на статичных скриншотах.









