
Команда Sina Weibo AI опубликовала VibeThinker-3B — компактную языковую модель всего с 3 миллиардами параметров, которая на задачах верифицируемых рассуждений (математика, программирование, STEM) вплотную приближается к результатам флагманских моделей DeepSeek V3.2 (671B), GLM-5 (744B) и Gemini 3 Pro. Главный вопрос, который исследователи ставили перед собой: насколько далеко можно продвинуть верифицируемые рассуждения в рамках строго малой модели? Ответ оказался неожиданным даже для самих авторов. Проект полностью открытый: веса модели доступны на Hugging Face, код обучения и инструменты опубликованы на GitHub.
Что такое верифицируемые рассуждения и почему это важно
Прежде чем разбирать архитектуру, стоит понять, чем верифицируемые рассуждения (verifiable reasoning) отличаются от обычных задач. Это задачи, где правильность ответа можно проверить объективно: решить уравнение, написать код, который проходит тесты, ответить на вопрос по физике с конкретным числом. В отличие от генерации текста или ответов на открытые вопросы, здесь есть чёткий критерий правильности, а значит, можно использовать reward-модели на основе правил, а не субъективных оценщиков.
Большинство исследователей считало, что для хорошего решения таких задач нужны десятки или сотни миллиардов параметров. VibeThinker-3B ставит этот тезис под сомнение.
Результаты: цифры говорят сами за себя
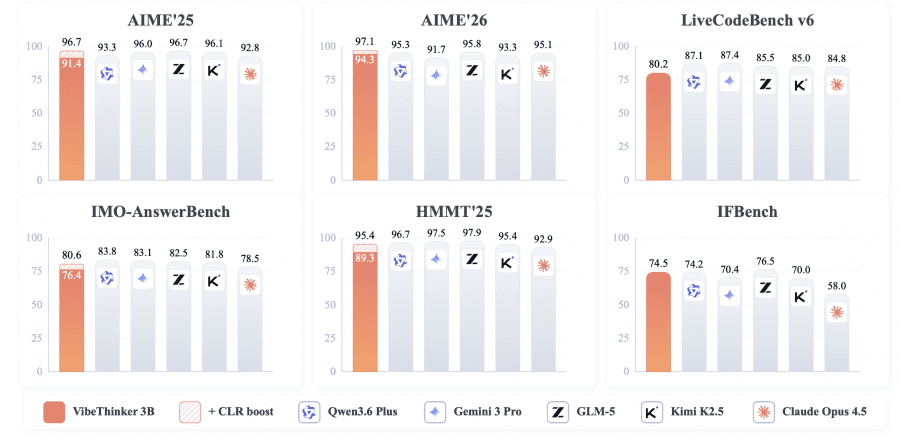
На AIME26 (один из самых сложных школьных математических олимпиадных бенчмарков) VibeThinker-3B набирает 94.3 балла без дополнительных техник. Это ровно столько же, сколько DeepSeek V3.2 с его 671 миллиардом параметров, то есть модель в 223 раза меньше показывает одинаковый результат. На LiveCodeBench v6 (соревновательное программирование) — 80.2 по метрике Pass@1, что превосходит все модели меньше 120B из таблицы сравнения.
На IFBench (следование сложным инструкциям пользователя) VibeThinker-3B набирает 74.5 — это выше, чем у большинства проприетарных флагманов: Claude Opus 4.5 даёт 58.0, Kimi K2.5 — 70.0. Это важно, потому что обычно agressive оптимизация под задачи рассуждения ухудшает способность следовать инструкциям. Здесь этого не произошло.
Гипотеза о параметрическом сжатии
На основе полученных результатов авторы сформулировали гипотезу о параметрическом сжатии и покрытии. Суть в том, что разные типы способностей модели требуют принципиально разного устройства параметрического пространства. Так верифицируемые рассуждения относятся к parameter-dense capabilities: алгоритм решения задачи универсален и повторяем, поэтому его можно плотно закодировать в небольшом числе параметров. Это принципиально отличается от хранения знаний, где каждый новый факт требует отдельного «места» в модели. Энциклопедические знания и задачи общего назначения требуют широкого покрытия фактов, понятий и редких сценариев, то есть это parameter-expansive capabilities, которые действительно масштабируются с ростом числа параметров.
Это хорошо видно на IMO-AnswerBench — бенчмарке из 400 задач олимпийского уровня по математике. VibeThinker-3B набирает 76.4 балла, а с CLR — 80.6, попадая в один диапазон с DeepSeek V3.2 (78.3, 671B) и GLM-5 (82.5, 744B). Ближайший конкурент сопоставимого размера, Qwen3.5-4B, останавливается на 48.7.
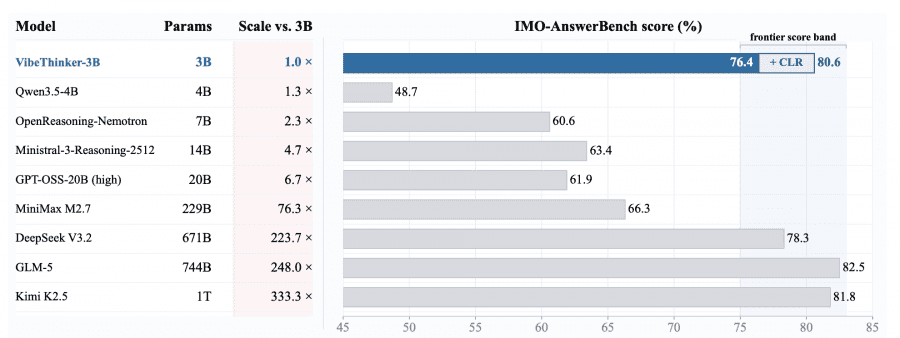
Это объясняет, почему на GPQA-Diamond (бенчмарк на знания докторского уровня) VibeThinker-3B заметно отстаёт от крупных моделей: там нужно вспомнить конкретный факт из узкой области, а не провести логический поиск.
Как обучали модель: четырёхэтапный пайплайн
VibeThinker-3B построена поверх Qwen2.5-Coder-3B и обучена по методологии Spectrum-to-Signal Principle (SSP), которую авторы разработали ещё в предыдущей работе VibeThinker-1.5B. Идея в том, что SFT-этап отвечает за построение широкого пространства решений («спектр»), а RL-этап усиливает правильные сигналы внутри него («сигнал»).
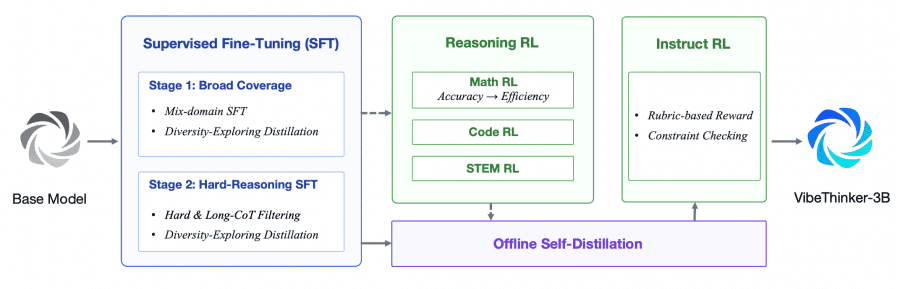
Этап 1 и 2. Supervised Fine-Tuning (SFT) проходит в две стадии. Сначала модель обучается на широком наборе задач (математика, код, STEM, диалог, следование инструкциям), чтобы охватить разные паттерны рассуждений. Затем распределение данных сдвигается в сторону длинных и трудных примеров: отбрасываются цепочки рассуждений (CoT) короче 5K токенов, а задачи с точностью выше 75% по 8 роллаутам считаются слишком лёгкими и убираются. Для снижения интерференции между доменами применяется Diversity-Exploring дистилляция: на каждом домене сохраняются промежуточные чекпоинты, а выбирается тот, что даёт наибольшее Pass@K. Затем все доменные модели сливаются на уровне весов.
Этап 3. Multi-domain Reasoning RL — обучение с подкреплением последовательно по трём доменам: сначала Math RL, затем Code RL, затем STEM RL. В качестве базового алгоритма используется MGPO (MaxEnt-Guided Policy Optimization) — модификация GRPO, которая назначает высокие веса запросам, где модель отвечает правильно примерно в половине случаев. Такие запросы находятся на текущей границе возможностей модели и дают наиболее полезный градиентный сигнал. Обучение ведётся с окном контекста 64K токенов без постепенного расширения: авторы обнаружили, что у более сильного SFT-чекпоинта раннее ограничение длины разрушает уже сложившиеся паттерны длинных рассуждений, восстановить их потом не удаётся.
В этапе Math RL дополнительно применяется Long2Short: после стандартной оптимизации точности добавляется фаза, где среди правильных ответов группы те, что короче, получают чуть более высокую награду. Сдвиги наград в сумме дают ноль, так что базовый уровень точности не снижается, но модель учится рассуждать лаконичнее.
Этап 4: Offline Self-Distillation и Instruct RL. После RL собираются лучшие рассуждения с чекпоинтов всех трёх доменов и дистиллируются обратно в единую модель через SFT. Для отбора траекторий используется Learning Potential Score — насколько плохо студент-модель предсказывает токены учительской траектории: чем хуже, тем больше потенциала для обучения. Финальный Instruct RL настраивает модель на следование сложным инструкциям с формальными ограничениями.
Масштабирование на этапе inference: CLR
Авторы предлагают Claim-Level Reliability Assessment (CLR) — стратегию масштабирования на этапе инференса без обновления весов. Вместо того чтобы агрегировать целые цепочки рассуждений (как делает обычный majority voting), CLR работает на уровне ключевых утверждений внутри рассуждения.
Для каждого запроса генерируется 32 кандидатных траектории. Из каждой извлекаются 5 ключевых утверждений, влияющих на финальный ответ. Затем модель сама пытается опровергнуть или подтвердить каждое утверждение, получая бинарную оценку. Надёжность траектории считается как среднее по 5 оценкам, возведённое в 5-ю степень: даже одна ошибка в ключевом утверждении резко снижает итоговый вес. Финальный ответ выбирается как тот, у которого сумма надёжностей всех поддерживающих его траекторий максимальна.
CLR поднимает результат на AIME26 с 94.3 до 97.1, на HMMT25 с 89.3 до 95.4, а на BruMO25 до 99.2.
Результаты VibeThinker-3B
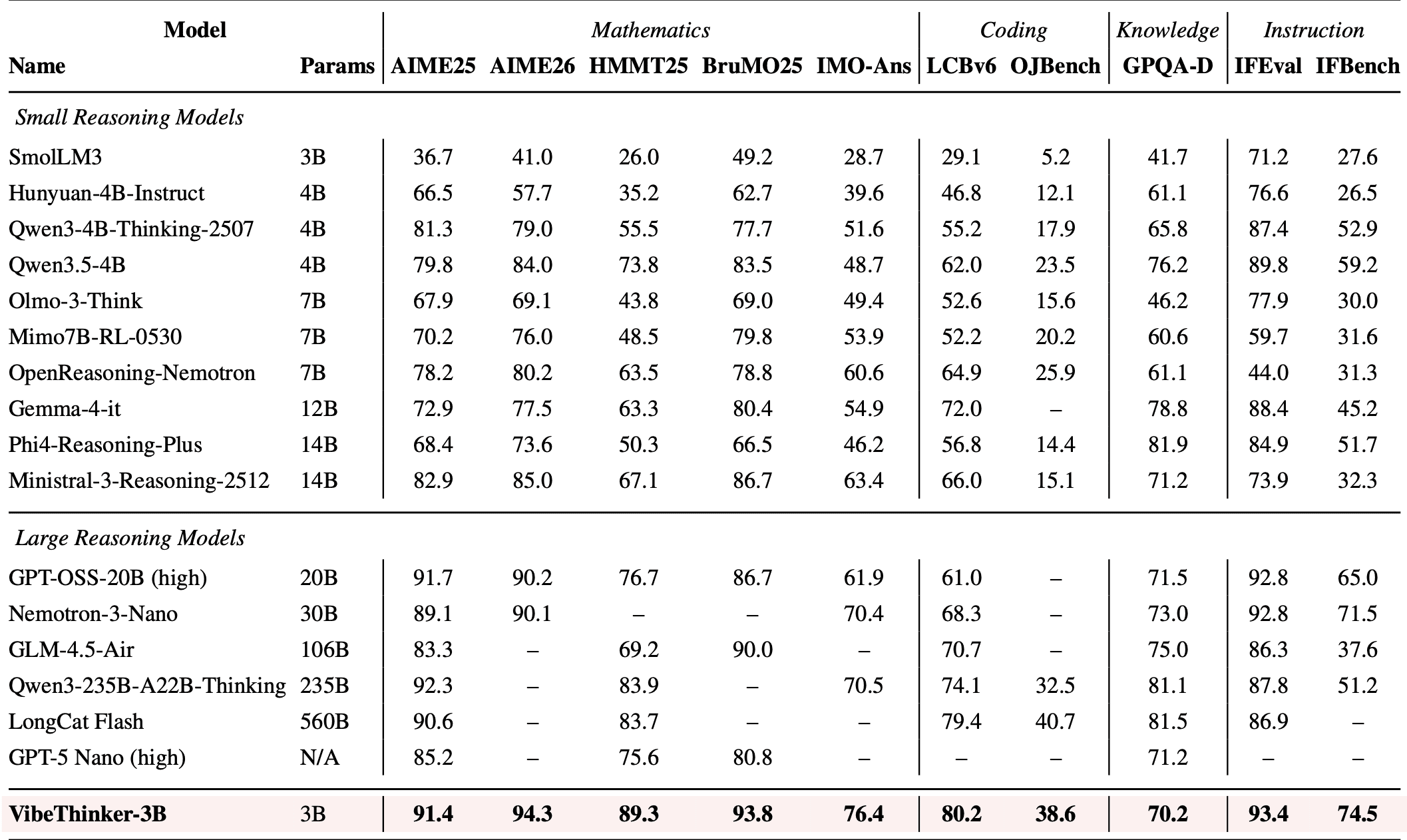
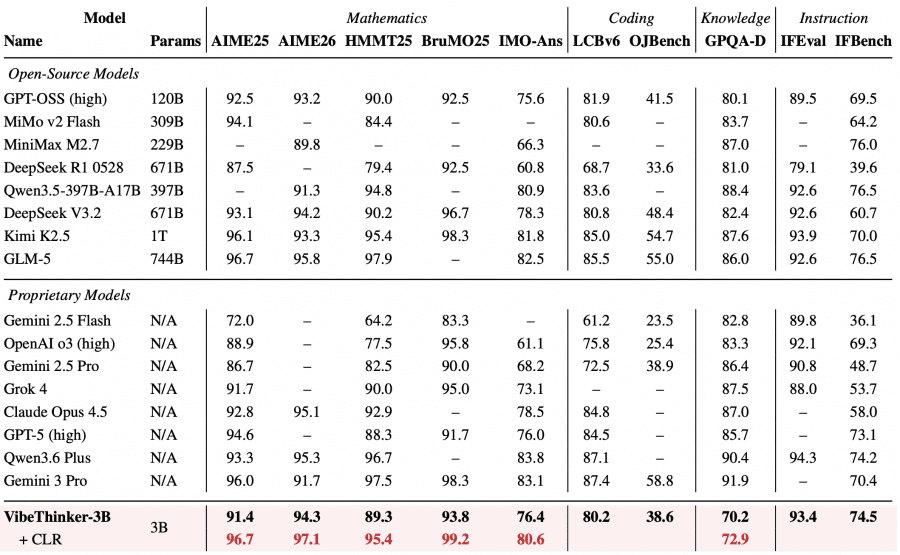
Что бросается в глаза при взгляде на таблицы: GPQA-Diamond у VibeThinker-3B — 70.2, тогда как у крупных моделей типа Qwen3.6 Plus это 90.4. Авторы трактуют это не как слабость, а как подтверждение гипотезы: там, где нужно вспомнить факт из конкретной узкой области, параметры действительно нужны в большом количестве. На задачах с формальной проверкой ответа маленькая модель с хорошим обучением не уступает гигантам.
Тест на обобщение: задачи LeetCode вне обучающей выборки
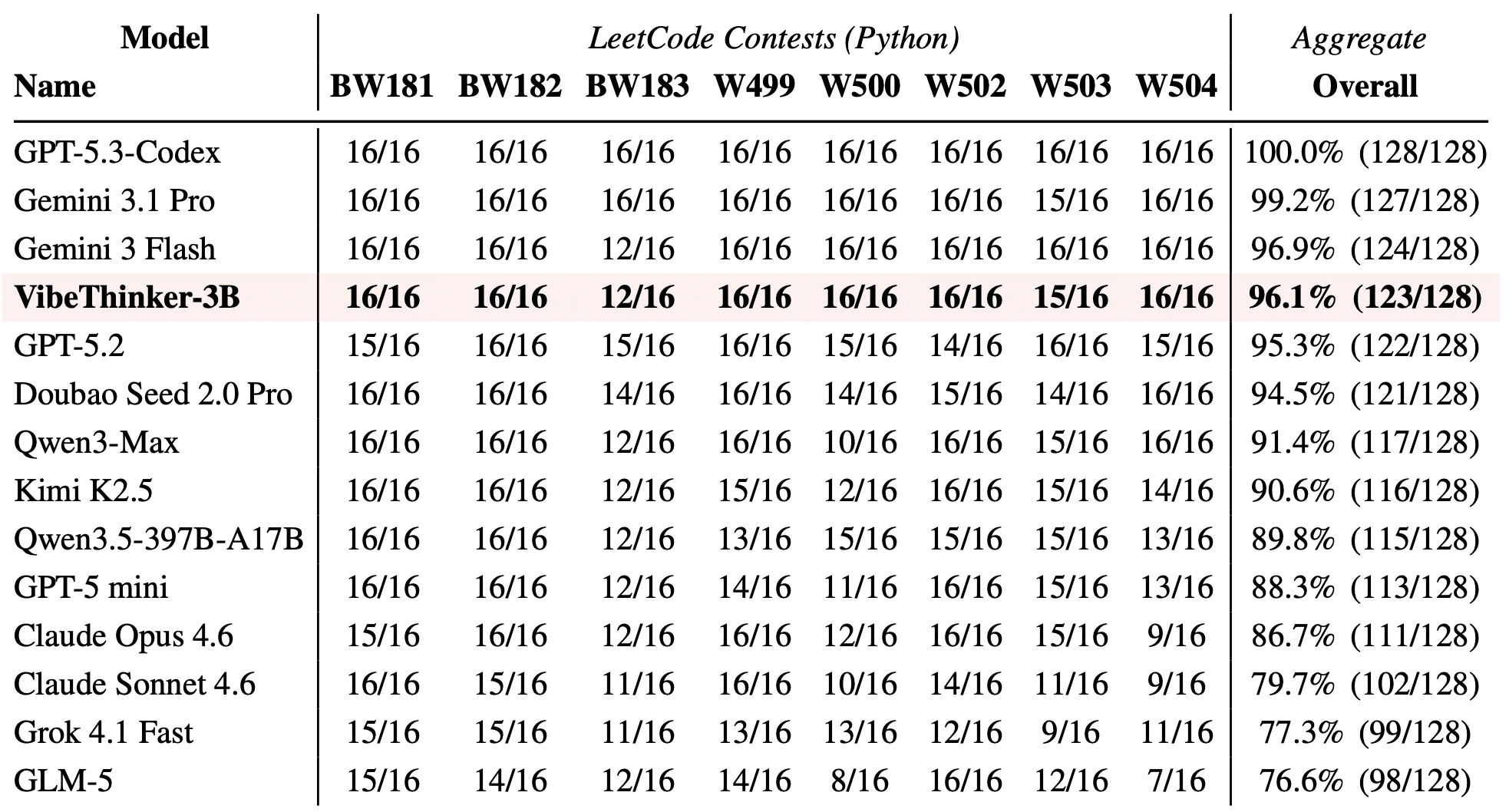
Один из самых показательных тестов — еженедельные контесты LeetCode с апреля по май 2026 года. Это задачи, которых точно не было в обучающих данных. Метрика простая: решение либо проходит все скрытые тесты с первой попытки, либо нет. VibeThinker-3B справляется с 123 из 128 попыток (96.1%), обгоняя GPT-5.2 (95.3%), Kimi K2.5 (90.6%) и всю линейку Claude 4.6. Это сильный сигнал того, что модель не просто заучила бенчмарки, а научилась решать задачи.
Что это значит для области
VibeThinker-3B даёт конкретный эмпирический ответ на вопрос, который раньше оставался открытым: сколько параметров нужно, чтобы войти в первый эшелон по верифицируемым рассуждениям? Судя по результатам, 3 миллиарда достаточно, если использовать правильный пайплайн обучения с диверсификацией решений, многодоменным RL и дистилляцией.
Авторы предлагают рассматривать малые модели не как компромисс ради дешёвого инференса, а как отдельное направление исследований, комплементарное традиционному масштабированию. Верифицируемые рассуждения сжимаемы в компактное ядро. Энциклопедические знания — нет. Это разграничение открывает путь к специализированным компактным моделям, которые по конкретным типам задач не уступают гигантам, стоя при этом на порядки меньше в деньгах и энергии на инференс.







