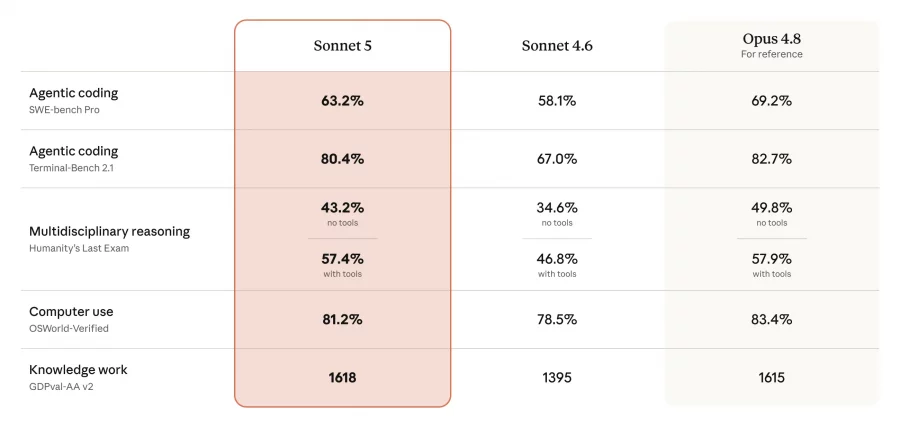
Anthropic представила Claude Sonnet 5 — новую модель из линейки Claude, доступную в том числе пользователям бесплатного тарифа. Она ориентирована на агентные задачи, программирование, работу с инструментами и корпоративную автоматизацию. Компания называет ее самым «агентным» Sonnet на сегодня: модель должна лучше планировать действия, использовать браузер и терминал, писать код, проверять результат и продолжать работу без постоянного контроля со стороны пользователя.
Но экономия не гарантирована: Sonnet 5 может выполнять больше промежуточных рассуждений, делать больше агентных шагов и быстрее расходовать токены. По результатам тестов при сопоставимом результате одна завершенная задача обходиться дороже, чем у флагманской Opus, доступной в платной подписке Claude.
Что такое Claude Sonnet 5
Claude Sonnet 5 — новая модель Anthropic для повседневной работы, кодинга и AI-агентов. Она доступна в Claude, Claude Code, Claude Platform API, GitHub Copilot и Cursor. Для пользователей Claude Free и Pro модель стала вариантом по умолчанию, также она доступна в тарифах Max, Team и Enterprise.
Для разработчиков модель доступна через API под названием claude-sonnet-5. До 31 августа 2026 года действует промо-цена: $2 за миллион входных токенов и $10 за миллион выходных. После этого цена должна стать $3/$15 за миллион токенов.
Главный тезис Anthropic: Sonnet 5 должна сократить разрыв между более доступными Sonnet-моделями и флагманской линейкой Opus. Компания делает акцент не просто на качестве ответов, а на способности модели выполнять многошаговые задачи: строить план, вызывать инструменты, работать с кодом, проверять результат и продолжать задачу автономно.
Почему релиз важен
Claude Sonnet 5 выходит в момент, когда рынок LLM смещается от чат-ботов к агентам. Пользователям уже недостаточно модели, которая хорошо отвечает на вопросы. Нужны системы, которые могут выполнять работу: менять кодовую базу, анализировать документы, открывать браузер, запускать команды, проверять ошибки и возвращаться к задаче после неудачной попытки.
Именно поэтому Sonnet 5 стоит оценивать не только по бенчмаркам. Для агентных моделей важны четыре практических показателя:
- качество финального результата;
- количество попыток и агентных шагов;
- расход токенов;
- стоимость одной успешно выполненной задачи.
И здесь первые тесты показывают: Sonnet 5 стала умнее, но не обязательно дешевле.
Независимые тесты: сильнее Sonnet 4.6, но стоимость заметно выше
По данным Artificial Analysis, Claude Sonnet 5 набрала 53 балла в Intelligence Index. Это ставит модель в верхнюю группу современных LLM и всего на несколько пунктов ниже Opus 4.8 и GPT-5.5 на высоких reasoning-настройках.
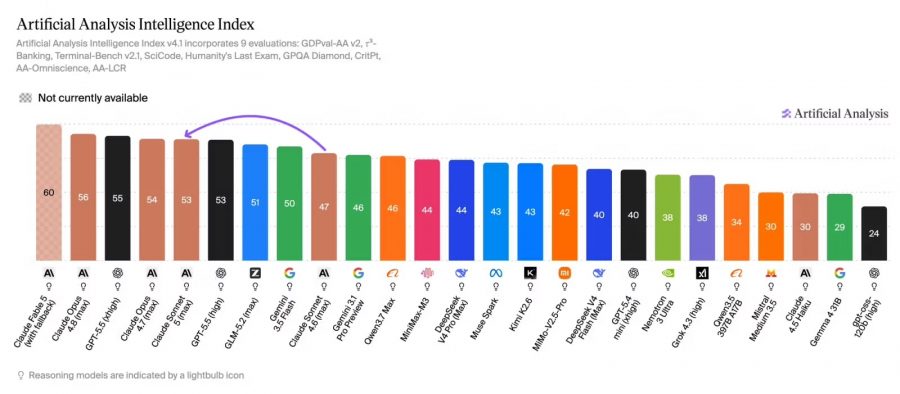
Главный вывод Artificial Analysis связан не столько с качеством модели, сколько с ее реальной стоимостью в работе. В режиме максимальной глубины рассуждения Sonnet 5 генерирует примерно на 40% больше текста, измеряемого в выходных токенах, чем Sonnet 4.6. А в тестах на сложные рабочие задачи — например, поиск информации, анализ документов и подготовку решений — модель делает до трех раз больше промежуточных шагов как AI-агент.
Из-за этого без промо-цены Sonnet 5 может стоить дороже на уровне одной задачи, чем кажется по прайс-листу. Формально цена за миллион токенов ниже, чем у Opus 4.8. Но если модель генерирует больше токенов и дольше выполняет задачу, итоговая стоимость может приблизиться к Opus или даже превысить ее в отдельных сценариях.
Новый токенизатор тоже влияет на стоимость
Разработчик и исследователь Simon Willison отдельно проверил новый токенизатор Claude Sonnet 5. В его тестах один и тот же английский текст превращался примерно в 1.4 раза больше токенов, испанский — в 1.33 раза больше, Python-код — примерно в 1.28 раза больше. Для упрощенного китайского текста разницы почти не было.
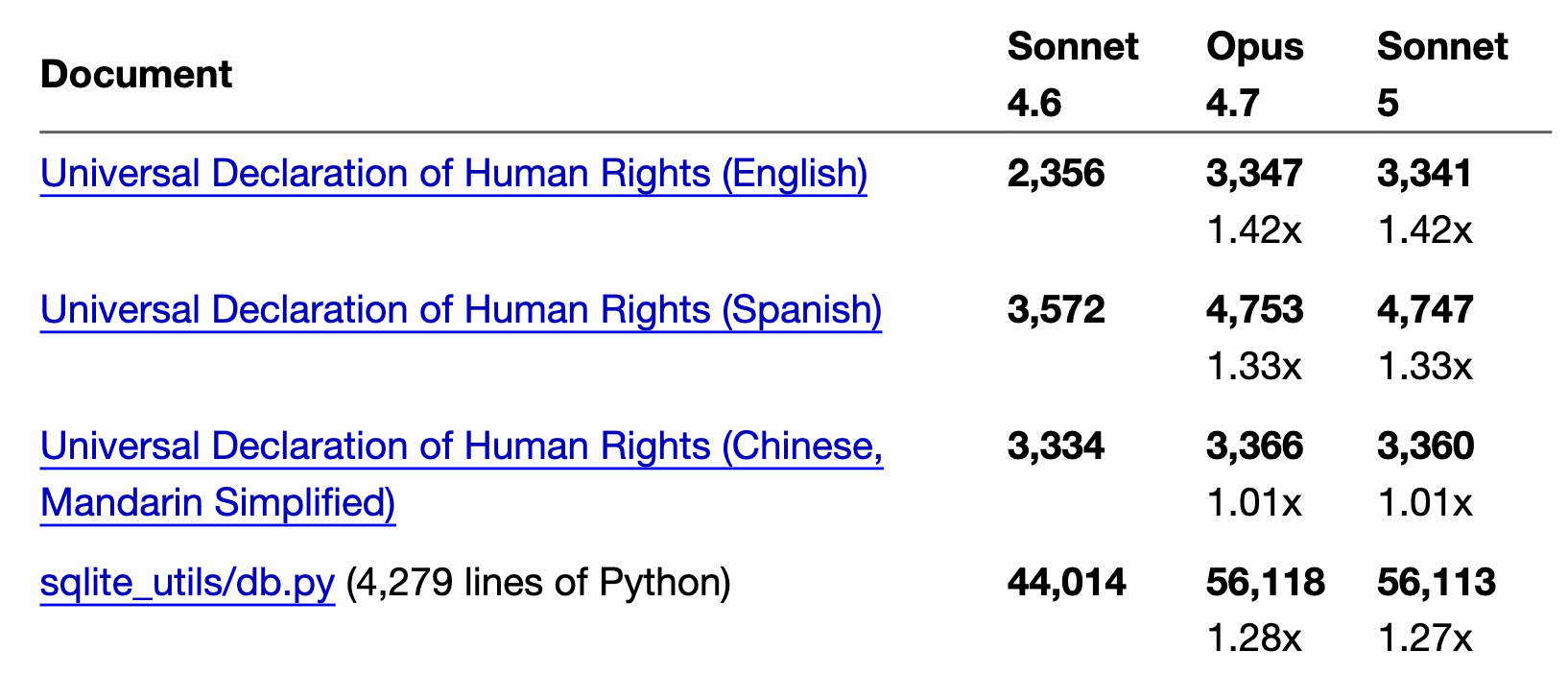
Anthropic тоже признает этот эффект в официальном релизе: один и тот же ввод может занимать примерно от 1.0× до 1.35× больше токенов в зависимости от типа контента. Компания объясняет, что временная промо-цена должна сделать переход на Sonnet 5 примерно нейтральным по стоимости.
Это важная деталь для разработчиков. Если продукт активно использует длинный контекст, документы, кодовые базы или агентные циклы, реальную экономику Sonnet 5 нужно проверять на собственных задачах, а не только по цене API.
Кодинг: заметный апгрейд в Cursor
В программировании первые результаты выглядят сильнее. Cursor сообщил, что Claude Sonnet 5 набрала 57% на CursorBench против 49% у Sonnet 4.6. CursorBench — это тест Cursor на реальных задачах программирования: модель должна понять запрос пользователя, разобраться в кодовой базе и внести изменения в несколько файлов.
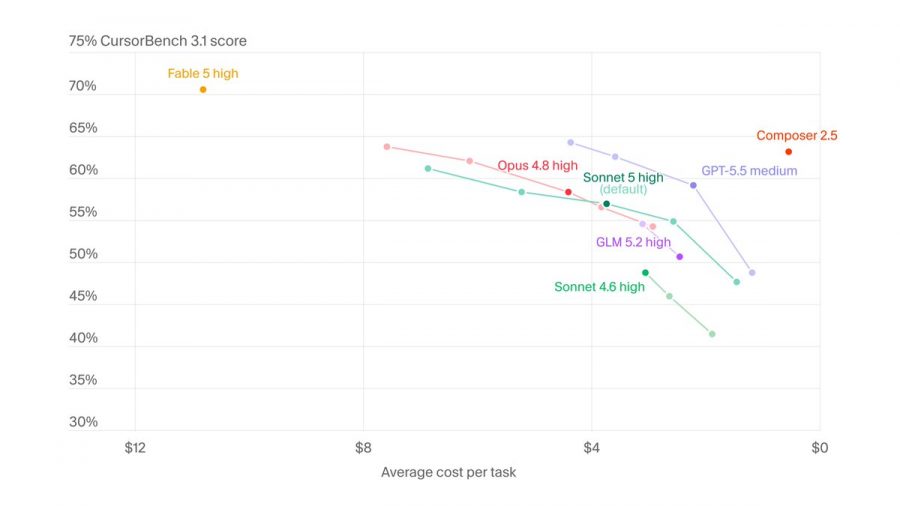
Это важнее, чем обычные синтетические тесты. В реальном AI-кодинге модель должна не просто написать фрагмент функции, а понять структуру проекта, внести изменения в несколько файлов, не сломать существующую логику и проверить результат. Судя по данным Cursor, Sonnet 5 стала лучше именно в таких задачах.
GitHub также добавил Claude Sonnet 5 в GitHub Copilot. Это показывает, что модель быстро становится частью основных инструментов для разработчиков, а не остается экспериментом внутри Claude.
CodeRabbit: лучше пишет код, но ревьюит код хуже
Практический обзор CodeRabbit дает более осторожную оценку. По их данным, Sonnet 5 — самая сильная модель своего класса для написания и сборки кода. Она терпеливее, дольше проверяет решение, чаще пишет тесты и лучше подходит для длинных агентных задач.
Но для ревью кода вывод не такой однозначный. CodeRabbit пишет, что комментарии Sonnet 5 стали чище и точнее: precision вырос примерно с 29% у Sonnet 4.6 до 38–40%. Однако по строгому показателю нахождения багов Sonnet 5 ловит меньше ошибок: около 50–51% против 63% у Sonnet 4.6 в их тестовом harness.
Есть и другой нюанс: если заставить модель «думать глубже», проверка кода почти не становится лучше, зато стоимость примерно удваивается. Поэтому Sonnet 5 хороша для написания кода и сложной агентной разработки, но не обязательно лучше всех подходит для ревью кода.
Реакция сообщества: не провал, но и не восторг
Реакция разработчиков получилась сдержанной. На Reddit в r/ClaudeAI часть пользователей восприняла релиз как полезный апгрейд: Sonnet 5 может стать рабочей моделью для повседневных задач, а Opus — оставаться для сложного планирования и критичных решений.
Но заметная часть обсуждения была скептической. Пользователи спорили о цене, расходе токенов и сравнении с Opus 4.8. Типичный вопрос: если Sonnet 5 в режиме глубоких рассуждений может быть дороже на задачу, зачем использовать ее вместо Opus?
На Hacker News тоже обсуждали не только качество модели, но и ее поведение в качестве ассистента разработчика. Sonnet 5 иногда ведет себя слишком самостоятельно. Например, вместо небольшой правки в одном месте модель может начать менять несколько файлов, переписывать соседнюю логику или предлагать более широкий рефакторинг. Для автономного AI-агента это полезно, но для обычной работы в IDE может мешать: разработчику часто нужен быстрый точечный ответ, а не лишние изменения в проекте, которые к тому же тратят токены.
Сравнение Claude Sonnet 5 с Sonnet 4.6 и Opus 4.8
| Модель | Сильные стороны | Ограничения | Когда использовать |
|---|---|---|---|
| Claude Sonnet 4.6 | Более предсказуемая стоимость, хороший баланс для кодинга и ревью | Слабее в агентных задачах и многошаговых рассуждениях | Быстрые правки, ревью кода, задачи с контролируемым бюджетом |
| Claude Sonnet 5 | Лучше в агентных пйаплайнах, кодинге, планировании и работе с инструментами | Может тратить больше токенов и быть дороже на задачу | AI-агенты, сложные правки в кодовой базе, автоматизация, рабочие ассистенты |
| Claude Opus 4.8 | Сильнее для глубоких рассуждений и сложного планирования | Выше цена за миллион токенов | Критичные задачи, сложная архитектура, финальная проверка, глубокие рассуждения |
Безопасность и cyber-риск
Anthropic отдельно подчеркивает, что Sonnet 5 не обучали специально под кибербезопасность. В тестах на потенциально опасные хакерские навыки модель уступает более мощным Opus 4.8 и Mythos 5. При этом из-за общего роста возможностей Sonnet 5 запускается с включенными cyber safeguards — защитными механизмами, которые должны блокировать опасное использование в реальном времени.
Axios также описывает Sonnet 5 как попытку Anthropic дать пользователям больше агентных возможностей без такого уровня cyber-риска, который связан с более мощными моделями вроде Opus и Mythos.
Что это значит для разработчиков
Claude Sonnet 5 — не революция и не маркетинговая пустышка. Это прагматичный релиз для агентного ИИ. Модель стала сильнее в кодинге, лучше держит длинные задачи и ближе подходит к Opus-классу в некоторых сценариях. Но главный вопрос теперь не «насколько она умная», а «сколько стоит успешный результат».
Для разработчиков Sonnet 5 выглядит как кандидат на модель по умолчанию для агентных пайплайнах: правки в кодовой базе, автоматизация, анализ документов, работа с CRM, подготовка пул-реквестов и другие многошаговые задачи. Opus при этом остается логичным выбором для глубоких рассуждений, сложного планирования и случаев, где ошибка стоит дороже экономии на токенах.
Практический вывод простой: Claude Sonnet 5 стоит тестировать не в чате и не на одном промпте, а на реальных задачах продукта. Нужно смотреть не только качество ответа, но и количество токенов, число итераций, скорость ответа, частоту отказов и стоимость завершенной задачи. Именно это решит, станет ли Sonnet 5 рабочей моделью для AI-агентов или останется промежуточным апгрейдом между Sonnet 4.6 и Opus.



