Anthropic has introduced Claude Sonnet 5, a new model in the Claude family that is also available to users on the free tier. It is designed for agentic tasks, programming, tool use, and enterprise automation. The company calls it the most “agentic” Sonnet model to date: the model is expected to plan actions better, use the browser and terminal, write code, check results, and continue working without constant user supervision.
But cost savings are not guaranteed: Sonnet 5 can perform more intermediate reasoning steps, make more agentic moves, and consume tokens faster. According to test results, for comparable outcomes, one completed task can cost more than with the flagship Opus model, which is available on paid Claude plans.
What is Claude Sonnet 5?
Claude Sonnet 5 is Anthropic’s new model for everyday work, coding, and AI agents. It is available in Claude, Claude Code, Claude Platform API, GitHub Copilot, and Cursor. For Claude Free and Pro users, it became the default model option; it is also available on Max, Team, and Enterprise plans.
For developers, the model is available through the API under the name claude-sonnet-5. Until August 31, 2026, a promotional price applies: $2 per million input tokens and $10 per million output tokens. After that, the price is expected to return to $3/$15 per million tokens.
Anthropic’s main claim is that Sonnet 5 should narrow the gap between the more accessible Sonnet models and the flagship Opus line. The company emphasizes not just answer quality, but the model’s ability to perform multi-step tasks: build a plan, call tools, work with code, check results, and continue the task autonomously.
Why the release matters
Claude Sonnet 5 arrives at a moment when the LLM market is shifting from chatbots to agents. Users no longer need only a model that answers questions well. They need systems that can do actual work: modify a codebase, analyze documents, open a browser, run commands, check errors, and return to the task after a failed attempt.
That is why Sonnet 5 should not be evaluated only by benchmarks. For agentic models, four practical metrics matter:
- the quality of the final result;
- the number of attempts and agentic steps;
- token consumption;
- the cost of one successfully completed task.
And the first tests show that Sonnet 5 has become smarter, but not necessarily cheaper.
Independent tests: stronger than Sonnet 4.6, but noticeably more expensive
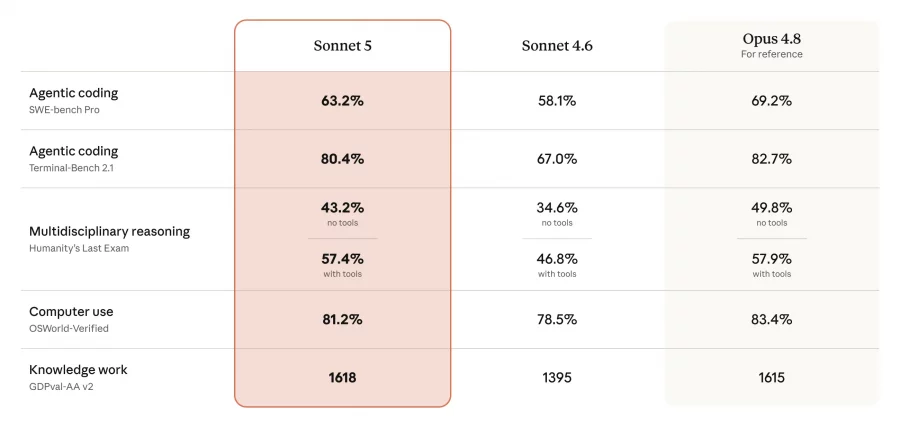
According to Artificial Analysis, Claude Sonnet 5 scored 53 points in the Intelligence Index. This places the model in the top tier of modern LLMs and only a few points below Opus 4.8 and GPT-5.5 at high reasoning settings.
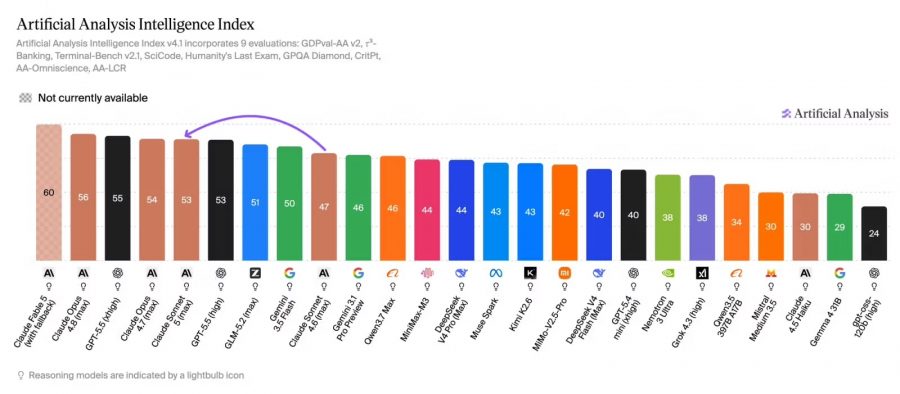
The main conclusion from Artificial Analysis is not so much about model quality as about its real cost in use. At maximum reasoning depth, Sonnet 5 generates about 40% more text, measured in output tokens, than Sonnet 4.6. And in tests of complex work tasks — for example, information retrieval, document analysis, and decision preparation — the model makes up to three times more intermediate steps as an AI agent.
Because of this, without the promotional price, Sonnet 5 can cost more per task than it looks from the pricing page. Formally, its price per million tokens is lower than Opus 4.8. But if the model generates more tokens and spends longer completing a task, the final cost can approach Opus or even exceed it in some scenarios.
The new tokenizer also affects cost
Developer and researcher Simon Willison separately tested the new Claude Sonnet 5 tokenizer. In his tests, the same English text became about 1.4 times larger in tokens, Spanish text — 1.33 times larger, and Python code — about 1.28 times larger. For simplified Chinese text, there was almost no difference.
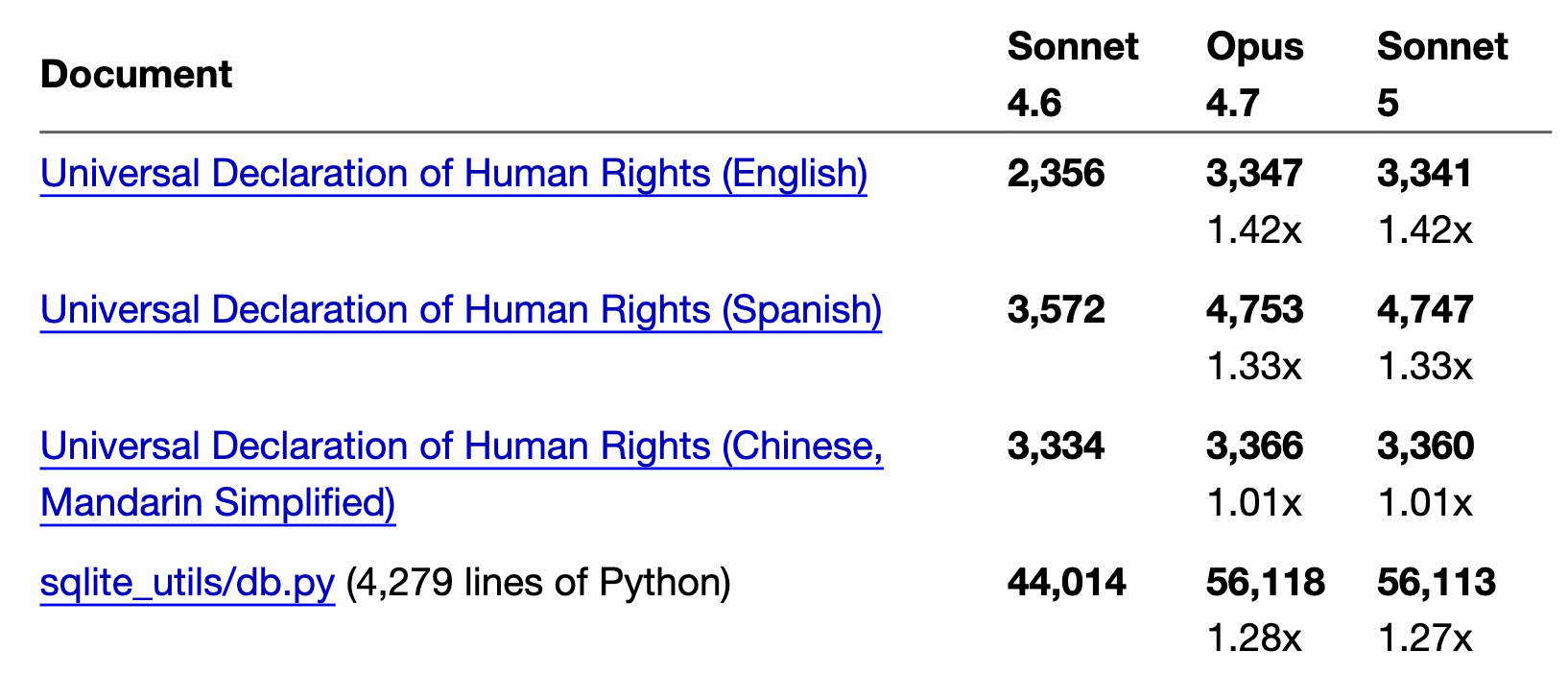
Anthropic also acknowledges this effect in the official release: the same input can take roughly 1.0× to 1.35× more tokens depending on the type of content. The company explains that the temporary promotional price should make the transition to Sonnet 5 roughly cost-neutral.
This is an important detail for developers. If a product actively uses long context, documents, codebases, or agentic loops, the real economics of Sonnet 5 need to be tested on the product’s own tasks, not just against the API price.
Coding: a noticeable upgrade in Cursor
In programming, the first results look stronger. Cursor reported that Claude Sonnet 5 scored 57% on CursorBench versus 49% for Sonnet 4.6. CursorBench is Cursor’s benchmark for real programming tasks: the model has to understand the user’s request, make sense of the codebase, and change several files.
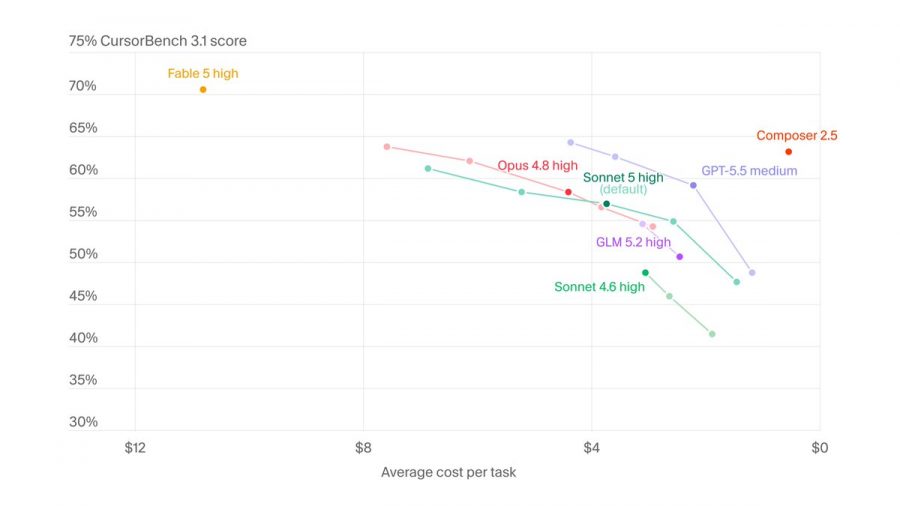
This matters more than ordinary synthetic tests. In real AI coding, a model should not simply write a small function. It needs to understand the project structure, modify several files, avoid breaking existing logic, and check the result. Based on Cursor’s data, Sonnet 5 has improved specifically in these kinds of tasks.
GitHub has also added Claude Sonnet 5 to GitHub Copilot. This shows that the model is quickly becoming part of mainstream developer tools, rather than remaining an experiment inside Claude.
CodeRabbit: better at writing code, weaker at code review
A practical review from CodeRabbit gives a more cautious assessment. According to their data, Sonnet 5 is the strongest model in its class for writing and building code. It is more patient, checks solutions for longer, writes tests more often, and is better suited for long agentic tasks.
But the conclusion for code review is less clear. CodeRabbit writes that Sonnet 5’s comments became cleaner and more precise: precision increased from about 29% for Sonnet 4.6 to 38–40%. However, by the stricter metric of bug detection, Sonnet 5 caught fewer errors: about 50–51% versus 63% for Sonnet 4.6 in their test harness.
There is another nuance: making the model “think deeper” barely improved code review quality, while roughly doubling the cost. So Sonnet 5 is strong for writing code and complex agentic development, but it is not necessarily the best model for code review.
Community reaction: not a failure, but not excitement either
The developer reaction has been restrained. On Reddit’s r/ClaudeAI, some users saw the release as a useful upgrade: Sonnet 5 can become the working model for everyday tasks, while Opus can remain reserved for complex planning and critical decisions.
But a significant part of the discussion was skeptical. Users argued about price, token consumption, and comparison with Opus 4.8. The typical question was: if Sonnet 5 in deep reasoning mode can cost more per task, why use it instead of Opus?
On Hacker News, developers also discussed not only the model’s quality, but its behavior as a coding assistant. Sonnet 5 can sometimes act too independently. For example, instead of making a small change in one place, it may start modifying several files, rewriting nearby logic, or proposing a broader refactor. This is useful for an autonomous AI agent, but can get in the way during ordinary IDE work: developers often need a quick, targeted answer, not extra project changes that also consume tokens.
Claude Sonnet 5 vs Sonnet 4.6 vs Opus 4.8
| Model | Strengths | Limitations | When to use |
|---|---|---|---|
| Claude Sonnet 4.6 | More predictable cost, good balance for coding and code review | Weaker in agentic tasks and multi-step reasoning | Quick edits, code review, tasks with a controlled budget |
| Claude Sonnet 5 | Better in agentic pipelines, coding, planning, and tool use | Can consume more tokens and cost more per task | AI agents, complex codebase changes, automation, workplace assistants |
| Claude Opus 4.8 | Stronger for deep reasoning and complex planning | Higher price per million tokens | Critical tasks, complex architecture, final review, deep reasoning |
Safety and cyber risk
Anthropic separately emphasizes that Sonnet 5 was not specifically trained for cybersecurity. In tests of potentially dangerous cyber capabilities, the model trails the more powerful Opus 4.8 and Mythos 5. At the same time, because of its general capability improvements, Sonnet 5 is launching with cyber safeguards — protective mechanisms designed to block dangerous use in real time.
Axios also describes Sonnet 5 as Anthropic’s attempt to give users more agentic capabilities without the same level of cyber risk associated with more powerful models such as Opus and Mythos.
What this means for developers
Claude Sonnet 5 is neither a revolution nor an empty marketing release. It is a pragmatic release for agentic AI. The model has become stronger in coding, handles long tasks better, and comes closer to the Opus class in some scenarios. But the main question is no longer “how smart is it?” — it is “how much does a successful result cost?”
For developers, Sonnet 5 looks like a candidate for the default model in agentic pipelines: codebase changes, automation, document analysis, CRM work, pull request preparation, and other multi-step tasks. Opus remains the logical choice for deep reasoning, complex planning, and cases where an error costs more than the savings on tokens.
The practical takeaway is simple: Claude Sonnet 5 should be tested not in chat and not on a single prompt, but on real product tasks. Developers need to look not only at answer quality, but also at token count, number of iterations, response speed, refusal rate, and the cost of a completed task. This is what will determine whether Sonnet 5 becomes a working model for AI agents or remains an intermediate upgrade between Sonnet 4.6 and Opus.