
Sina Weibo AI published VibeThinker-3B — a compact language model with just 3 billion parameters that matches flagship models DeepSeek V3.2 (671B), GLM-5 (744B), and Gemini 3 Pro on verifiable reasoning tasks including mathematics, coding, and STEM. The researchers set out to answer a single question: how far can verifiable reasoning be pushed within a strictly small-model regime? The answer surprised even the authors themselves. The project is fully open: model weights are available on Hugging Face, training code and tools are published on GitHub.
What is verifiable reasoning and why it matters
Before diving into the architecture, it helps to understand what makes verifiable reasoning different from other tasks. These are problems where correctness can be checked objectively: solving an equation, writing code that passes tests, answering a physics question with a specific number. Unlike open-ended text generation, there is a clear criterion for correctness, which means rule-based reward models can be used instead of subjective human evaluators.
Most researchers assumed that tackling such tasks well required tens or hundreds of billions of parameters. VibeThinker-3B challenges that assumption.
Results: the numbers speak for themselves
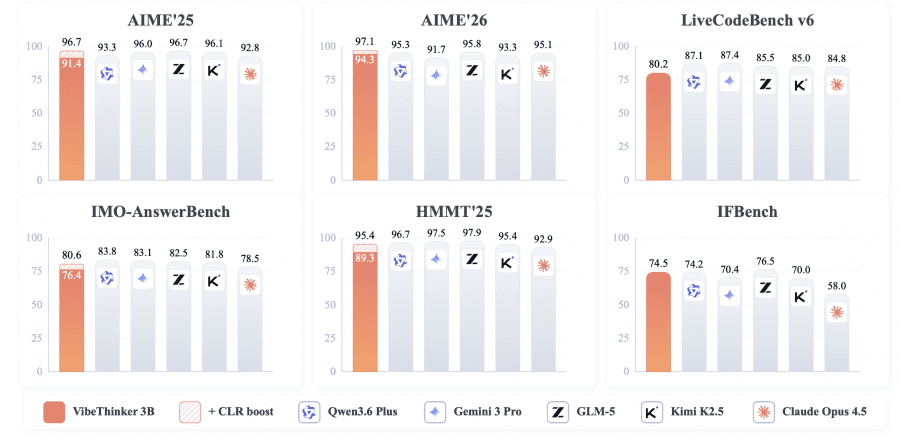
On AIME 2026, one of the most demanding olympiad-style mathematics benchmarks, VibeThinker-3B scores 94.3 without any additional techniques. That is exactly the same as DeepSeek V3.2 with its 671 billion parameters — a model 223 times larger achieving the same result. On LiveCodeBench v6 (competitive programming), it reaches 80.2 Pass@1, outperforming all models under 120B in the comparison table.
On IFBench, which measures instruction following under complex constraints, VibeThinker-3B scores 74.5 — higher than most proprietary flagships: Claude Opus 4.5 scores 58.0, Kimi K2.5 scores 70.0. This matters because aggressive optimization for reasoning typically degrades instruction-following ability. That did not happen here.
The Parametric Compression-Coverage Hypothesis
Based on their findings, the authors formulate the Parametric Compression-Coverage Hypothesis. Different types of model capabilities require fundamentally different structures in parameter space. Verifiable reasoning belongs to parameter-dense capabilities: the solution algorithm is universal and repeatable, so it can be densely encoded in a small number of parameters. This is fundamentally different from knowledge storage, where each new fact requires its own dedicated space. Open-domain knowledge and general-purpose tasks require broad coverage of facts, concepts, and long-tail scenarios — these are parameter-expansive capabilities that genuinely scale with model size.
This is clearly illustrated by IMO-AnswerBench, a benchmark of 400 olympiad-level mathematics problems. VibeThinker-3B scores 76.4, and 80.6 with CLR, placing it in the same range as DeepSeek V3.2 (78.3, 671B) and GLM-5 (82.5, 744B). The nearest competitor of comparable size, Qwen3.5-4B, stops at 48.7.
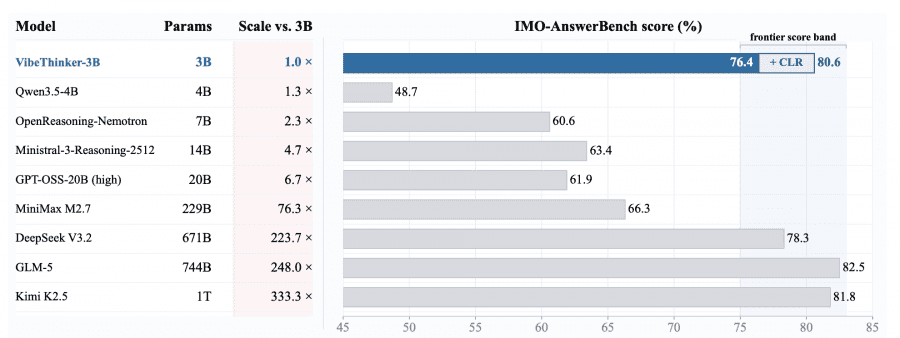
This also explains why VibeThinker-3B trails larger models on GPQA-Diamond, a graduate-level knowledge benchmark: those tasks require recalling specific facts from narrow domains rather than performing logical search.
Training pipeline: four stages
VibeThinker-3B is built on top of Qwen2.5-Coder-3B and trained using the Spectrum-to-Signal Principle (SSP), developed in the earlier VibeThinker-1.5B work. The idea is that the SFT stage builds a broad solution space (the “spectrum”), while the RL stage amplifies correct signals within it (the “signal”).
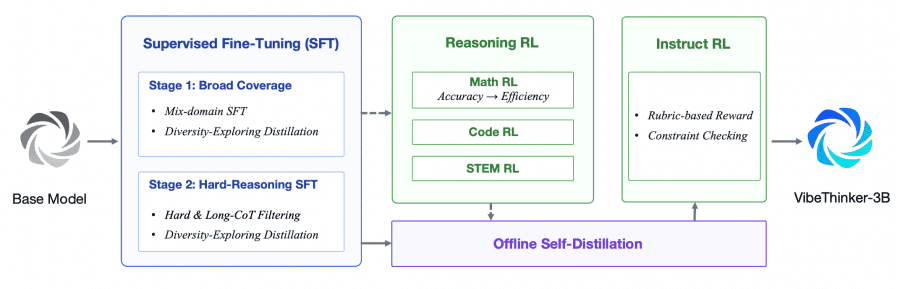
Stages 1 and 2. Supervised Fine-Tuning (SFT) runs in two phases. First, the model trains on a broad mix of tasks (mathematics, code, STEM, dialogue, instruction following) to cover diverse reasoning patterns. Then the data distribution shifts toward long and difficult examples: reasoning chains (CoT) shorter than 5K tokens are discarded, and problems where the model already achieves over 75% accuracy across 8 rollouts are considered too easy and removed. To reduce cross-domain interference, Diversity-Exploring Distillation is applied: intermediate checkpoints are saved per domain, the one with the highest Pass@K is selected, and all domain-specific models are then merged at the parameter level.
Stage 3. Multi-domain Reasoning RL applies reinforcement learning sequentially across three domains: Math RL, then Code RL, then STEM RL. The core algorithm is MGPO (MaxEnt-Guided Policy Optimization), a modification of GRPO that assigns higher weights to prompts where the model answers correctly roughly half the time. These prompts sit at the current capability boundary and provide the most useful gradient signal. Training uses a 64K token context window without gradual expansion: the authors found that early length restrictions damage already-formed long-horizon reasoning patterns in stronger SFT checkpoints, and those patterns do not recover once the context window is later expanded.
Within Math RL, a Long2Short phase is added: after standard accuracy optimization, shorter correct responses within a group receive a slightly higher reward. The reward shifts sum to zero, so overall accuracy is preserved, but the model learns to reason more concisely.
Stage 4. Offline Self-Distillation and Instruct RL. After RL, the best reasoning traces from checkpoints across all three domains are collected and distilled back into a unified model via SFT. Traces are selected using a Learning Potential Score — how poorly the student model predicts tokens in the teacher trajectory: the worse the prediction, the higher the distillation value. A final Instruct RL stage then tunes the model to follow complex instructions with formal constraints.
Test-time scaling: CLR
The authors propose Claim-Level Reliability Assessment (CLR), a test-time scaling strategy that requires no weight updates. Rather than aggregating full reasoning traces as in standard majority voting, CLR operates at the level of individual claims within a reasoning chain.
For each query, 32 candidate trajectories are generated. From each, 5 key claims affecting the final answer are extracted. The model then attempts to verify or falsify each claim, producing a binary verdict. Trajectory reliability is computed as the mean of the 5 verdicts raised to the power of 5: even a single flawed claim sharply reduces the trajectory’s weight. The final answer is the one whose supporting trajectories have the highest combined reliability score.
CLR raises the AIME 2026 score from 94.3 to 97.1, HMMT25 from 89.3 to 95.4, and BruMO25 to 99.2.
Benchmark results
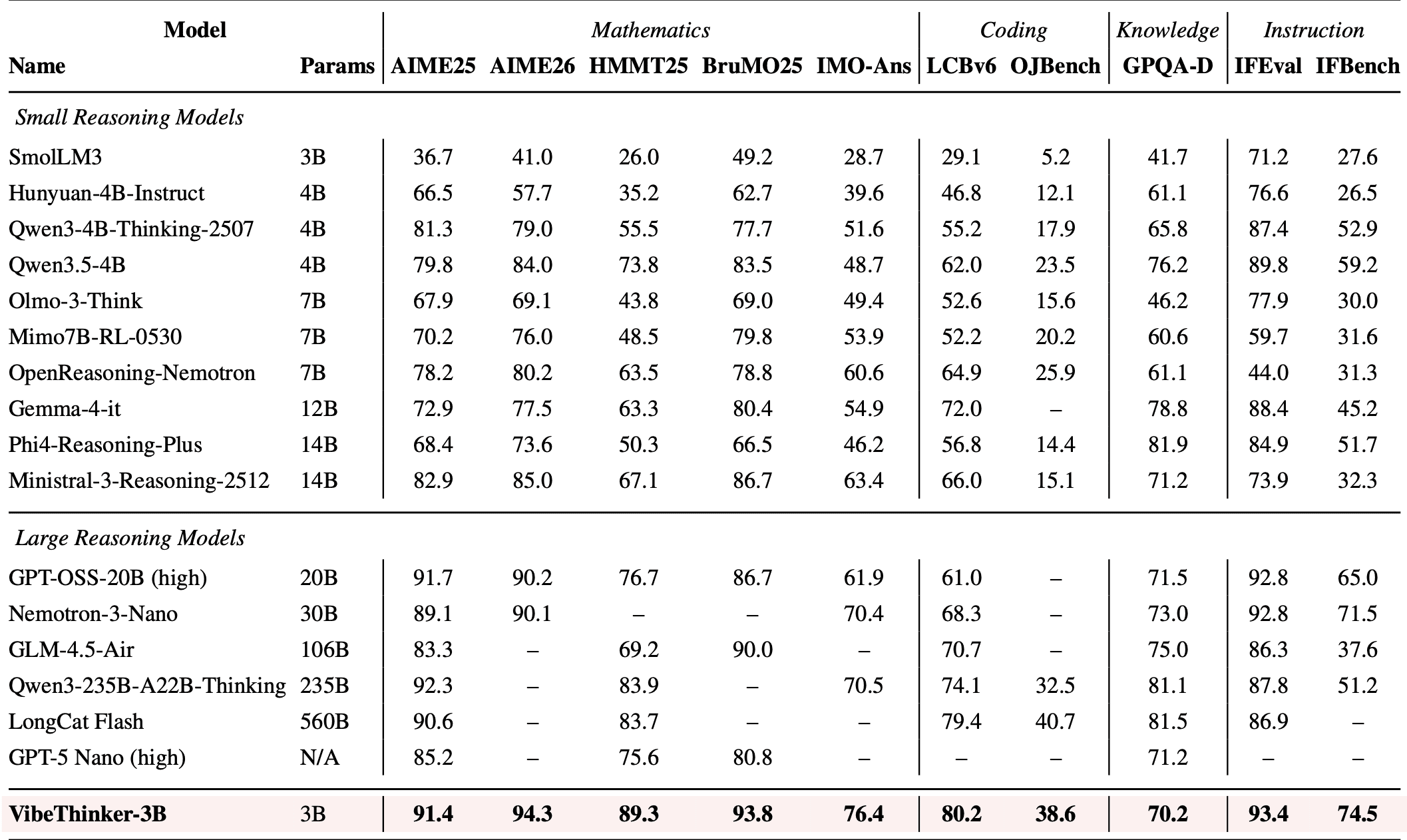
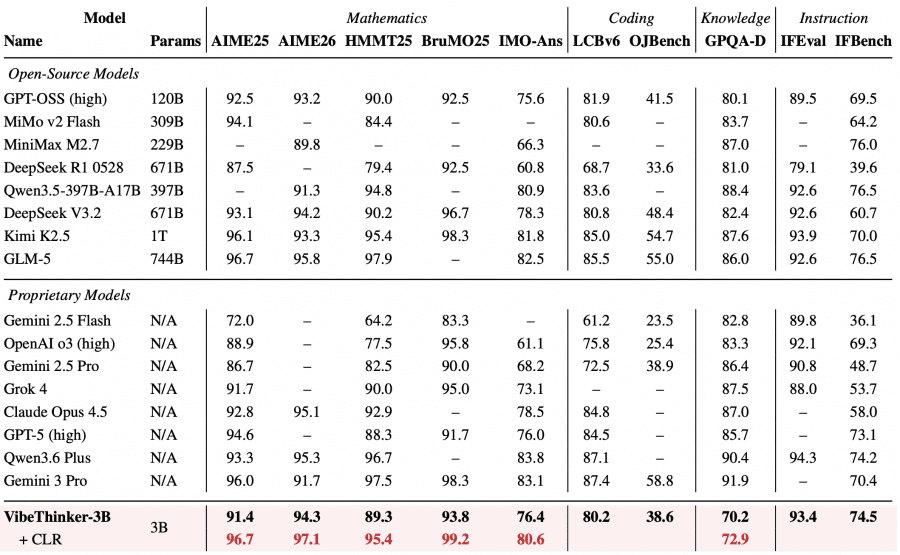
The most notable gap in the tables is GPQA-Diamond: 70.2 for VibeThinker-3B versus 90+ for large models like Qwen3.6 Plus. The authors interpret this not as a weakness but as confirmation of the hypothesis: where broad factual recall is required, scale still matters. On tasks with a formal correctness criterion, a well-trained small model holds its own against the giants.
Out-of-distribution test: LeetCode contests
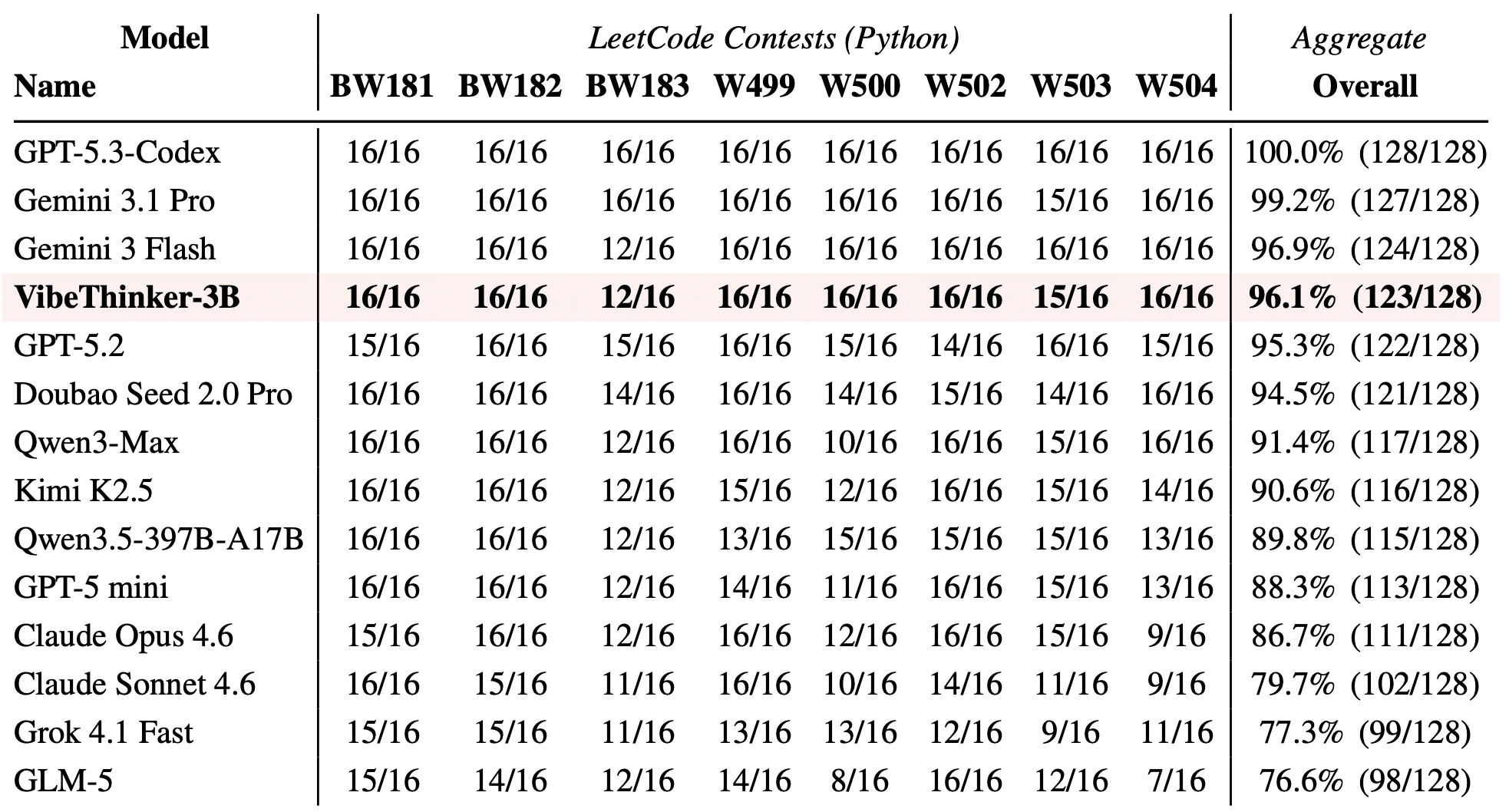
One of the most informative tests is the LeetCode weekly and biweekly contests from April through May 2026 — problems that were certainly not in the training data. The metric is simple: the solution either passes all hidden tests on the first attempt or it does not. VibeThinker-3B passes 123 out of 128 attempts (96.1%), outperforming GPT-5.2 (95.3%), Kimi K2.5 (90.6%), and the entire Claude 4.6 lineup. This is a strong signal that the model has not simply memorized benchmarks but has learned to solve problems.
What this means for the field
VibeThinker-3B provides a concrete empirical answer to a question that was previously open: how many parameters are needed to reach the first tier in verifiable reasoning? Based on these results, 3 billion is enough — provided the training pipeline combines diverse solution exploration, multi-domain RL, and self-distillation.
The authors argue that small language models should no longer be viewed purely as a cost-saving compromise. Verifiable reasoning is compressible into a compact core. Encyclopedic knowledge is not. This distinction opens a path toward specialized compact models that match giants on specific task types while costing orders of magnitude less in money and energy at inference time.








