Researchers from the University of Wisconsin-Madison have introduced a text-to-image diffusion model called PACGen (Personalized and Controllable Text-to-Image Generation) for transferring objects from one image to a new scene generated based on a text prompt. To achieve this, multiple images of the object, a textual prompt describing the new scene, and a designated region for placing the object need to be provided.
PACGen achieves comparable or even higher quality for personalized objects compared to state-of-the-art models. The potential of the model is significant, as advertising designers, for instance, can place their products in any desired location on an advertisement banner.
According to the researchers, the model’s code has not been published yet. However, they have stated that it will become available in the near future on the GitHub repository.
Method
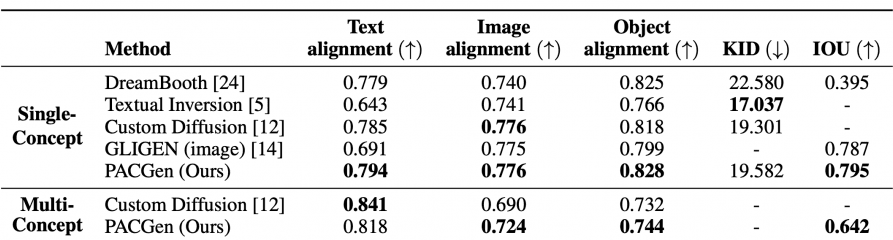
The researchers combined two open-source models built on the Stable Diffusion architecture. The diffusion model DreamBooth successfully transferred the input object to a new scene but struggled with controlling the object’s location and size:

On the other hand, the model GLIGEN excelled at generating objects within specified regions but had difficulty preserving object identity. To address these limitations, the researchers integrated the adapter layers of GLIGEN into DreamBooth, resulting in a new model called PACGen. This integration allowed precise control over the object’s location and size on the new scene. The regionally-guided sampling technique ensured the quality and fidelity of the generated images.
Through the use of data augmentation, which involved random resizing and repositioning of training images, PACGen successfully disentangled object identity from spatial information, enabling the generation of personalized images:
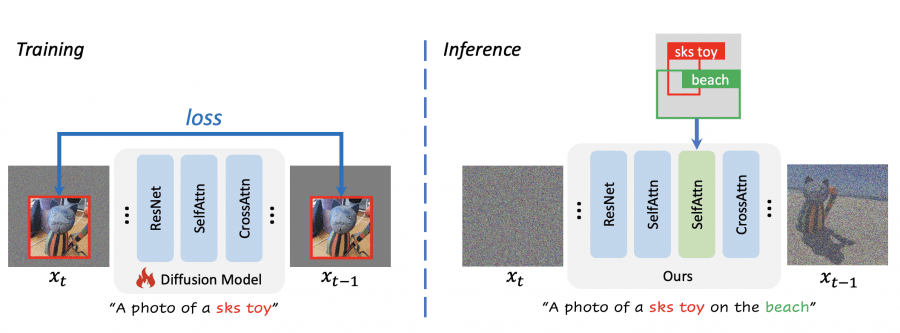
PACGen Results
PACGen offers versatile applications, allowing the generation of objects at specified locations within defined scenes and artistic styles:
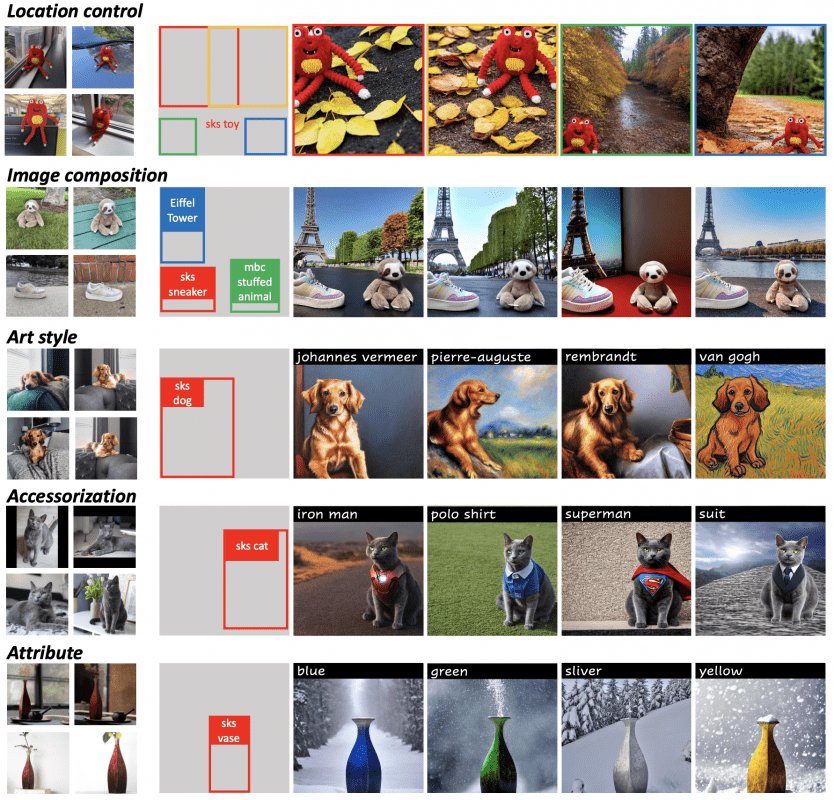
Quantitative comparison with state-of-the-art models: