Being able to see beyond walls has been considered superhuman power, seen in many sci-fi movies in the past. In 2011, researchers the Massachusetts Institute of Technology announced that they developed a new radar technology that provides real-time video of what is going on behind solid walls. Although successful, this represents complex radar technology intended for specific use-cases.
Seven years later, researchers from the same university — MIT, have proposed a new method for “seeing beyond walls.”
Very much like humans and animals who see via waves of visible light that bounce off objects and then strike the retina in our eyes, we can “see” through walls by sending waves that bounce off (specific) targets and return to the receivers. In the new approach, the researchers leverage the power of the wifi frequencies that traverse walls and reflect off the human body. Utilizing the WiFi signals together with Deep Learning techniques, they demonstrate very accurate human pose estimation through walls and under occlusions.
The Input
The method that they propose, called RF-Pose is using low-power wireless signal (actually 1000 times lower than WiFi). It is using the radio reflections and deep neural network to provide accurate pose estimation even under occlusion and behind walls. Walls, by definition, are solid objects made of concrete and they can block signals or at least weaken them. However, there are signals (or at least frequencies of signals) that can traverse walls, and the WiFi signal is one of them. To be able to address the problem of detecting what is behind a wall (of concrete) one has to record the reflected signal that traversed the wall and bounced off an object. In the RF-Pose, the researchers use a commonly known technique called FMCW (Frequency Modulated Continuous Wave) alongside with antenna arrays. In essence, FMCW separates the RF reflections (Note: RF is the Radio Frequency signal used in this approach and it is 1000 lower than the WiFi) based on the distance of the reflecting object. On the other hand, antenna arrays separate the reflections based on the spatial direction.
In this way, the input data of the RF-Pose method are two projections of the signal reflections with are represented as heat maps, created with the two antennas: vertical and horizontal.
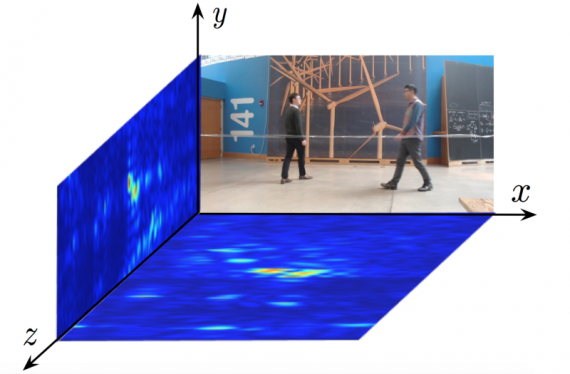
The Method
To be able to exploit Deep Learning techniques, it is of crucial importance to define a proper input-output scheme along with proper architecture design, taking into account all the limitations and the nature of the data. Having proved as very successful, Convolutional Neural Networks have been used in many cases where pixels are not the natural representation. In this case, the problem is similar — the RF (Radio Frequency) signals differ significantly from visual data, in terms of their property.
To overcome this, the authors explain and take into account the limitations of RF signals. Mainly, they argue that RF signals, and especially the frequencies that traverse walls have a low spatial resolution (measured in tens of centimetres) as opposed to vision data having a resolution in parts of the millimetre.
Secondly, they argue that the wavelength has to be tuned accordingly to the human body so that humans act as reflectors and not a scatterer. Finally, the data representation differs a lot from images, i.e., visual data because RF signals are given as complex numbers.
Having defined the problem-specific requirements, the researchers propose a method based on cross-modal supervision to tackle the problem of human pose estimation under occlusions. They suggest a teacher-student architecture using synchronized pairs of RGB images and heatmap projections of the RF-signal reflections.
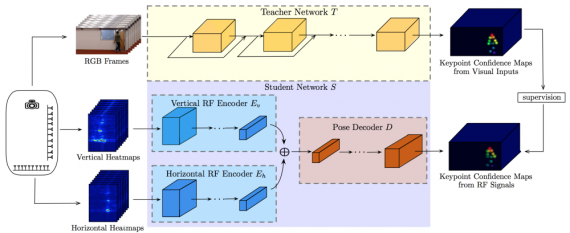
The teacher network is trained using RGB images, and it learns to predict 14 key points, corresponding to the anatomical parts of the human body: head, neck, shoulders, elbows, wrists, hips, knees and ankles. These predicted confidence maps with key points from the teacher network are used for explicit cross-modal supervision for the student network.
Therefore, the training objective is the minimization of the error between the student network’s prediction and the teacher network’s prediction. To achieve this goal, they define a pixel-wise loss function between the confidence maps corresponding to the binary cross entropy.![]() Since the radio is used in this approach generates 30 pairs of heatmaps per second, the authors had the freedom to train the network by aggregating information from multiple, subsequent snapshots of RF heatmaps. They do this to overcome the problem of key point localization using only one snapshot.
Since the radio is used in this approach generates 30 pairs of heatmaps per second, the authors had the freedom to train the network by aggregating information from multiple, subsequent snapshots of RF heatmaps. They do this to overcome the problem of key point localization using only one snapshot.
To overcome the problem of different views of the camera and the RF-heatmaps, they impose an encoder-decoder architecture in the student network that forces the network to learn the transformation from the views of RF-heatmaps to the view of the camera. Thus, they employ two encoder networks for both the horizontal and vertical heatmaps (plural because of the use of multiple snapshots) that encode the information and one decoder network that predicts the keypoint confidence maps by getting channel-wise concatenated encodings (from both encoder networks) as input.
The spatiotemporal convolutional encoder networks use 100 frames as input (3.3 seconds), each one having 10 layers of 9x5x5 convolutions. The decoding network consists of 4 layers with 3x6x6 convolutions, and both networks use ReLU units and batch normalization. The implementation was done in PyTorch, and the training was conducted using the batch size of 24.

Evaluation and Conclusions
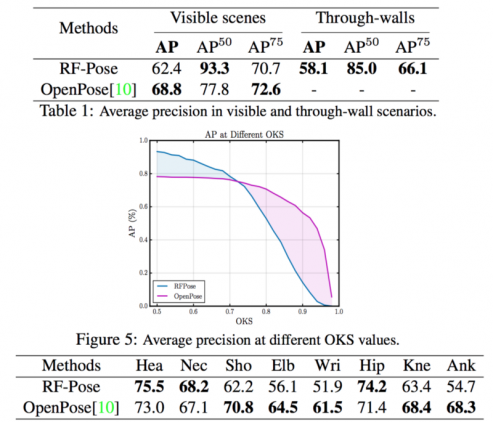
This approach shows very good results, taking into account the low number of examples used for training. RF-Pose outperforms OpenPose on the visible scenes reporting on the AP evaluation metric (the mean average precision over 10 different OKS thresholds ranging from 0.5 to 0.95.) The comparison between the two is given in the tables and the plot below.
Arguing that occlusion is one of the most significant problems in human pose estimation, the researchers propose a new method using deep neural networks and RF signals to overcome it and provide robust and accurate human pose estimation. We expect to see many applications of this approach since the problem of (human) pose estimation represents an important task especially in the fields of surveillance, activity recognition, gaming, etc.