
VFusion3D introduces a novel method in 3D generative modeling by utilizing video diffusion models to overcome the scarcity of 3D data. The model generates meshes in .obj format, which can be tested and explored directly here. By fine-tuning a pre-trained video diffusion model, VFusion3D generates large-scale synthetic multi-view datasets, significantly enhancing the training of 3D models. This approach enables the efficient generation of high-quality 3D assets from a single image.

Methodology
VFusion3D transforms a video diffusion model into a 3D multi-view data generator. The EMU Video model, fine-tuned with 100K 3D objects, generates 3 million synthetic multi-view videos. These videos are used to train a feed-forward 3D generative model, producing consistent 3D assets from single images.
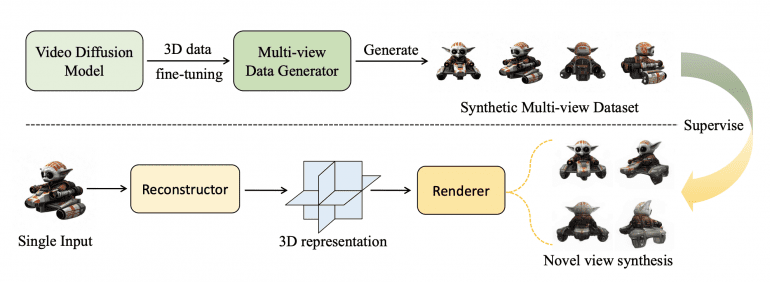
Results
VFusion3D outperforms existing models like OpenLRM and LGM in both 3D consistency and visual fidelity. It achieves higher CLIP Image and Text Similarity scores, indicating better alignment with input data.
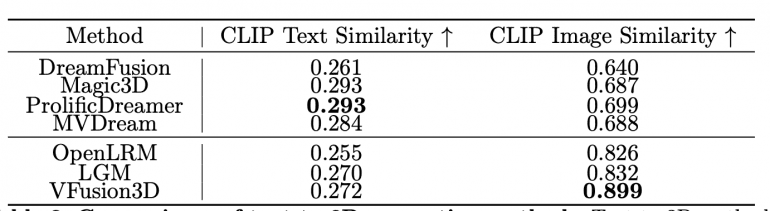
Performance and Speed
VFusion3D not only delivers high-quality 3D models but also does so efficiently. It can generate a 3D asset from a single image in 17 seconds, making it significantly faster than traditional methods, which are often slower and less consistent.
Input:

Result:
Scalability
The method allows for scalable 3D asset creation, ideal for industries like gaming and AR/VR. Its ability to generate high-quality 3D assets quickly and from minimal input data sets a new benchmark in 3D generative modeling.
VFusion3D addresses the challenge of limited 3D data by using video diffusion models to generate scalable, high-quality 3D assets. This advancement has significant implications for industries relying on 3D content, setting a new standard in the field. As VFusion3D continues to evolve, its ability to quickly generate consistent 3D models from single images will likely drive further innovation in 3D content creation.





