CoS-E — датасет, который состоит из описания обыденных случаев и объяснений к ним. Датасет собирали исследователи из Salesforce. Данные доступны по ссылке.
Примеры из датасета. Единица данных состоит из вопроса, объяснения ответа и написанного человеком ответа
Репозиторий содержит человеческие объяснения для Commonsense Question Answering (CQA) датасета. Исследователи собрали объяснения для обучающих выборок из v1.0 и v1.11 версий датасета. Идентификаторы вопросов совпадают с оригинальными идентификаторами из CQA.
Каждый файл содержит два типа объяснений:
- Отобранные: цитаты из текста вопроса, которые выступают как объяснение для выбора ответа;
- Открытые: объяснения на естественном языке в свободной форме
Помимо сырых файлов, датасет включает в себе обработанные данные, не содержащие шумов, для каждой категорий. Несмотря на это, для экспериментов использовали оригинальные необработанные файлы.
Этические вопросы
Исследователи заметили значительный дисбаланс вопросов по гендеру. Помимо этого, есть смещение в CQA датасете такое, что женские местоимения чаще встречаются в негативном контексте.

Подобное смещение распространяется и на собранный CoS-E. Это нужно принимать во внимание при обучении моделей. Несмотря на смещение в вопросах, люди для создания CoS-E привлекались через краудсорсинговую платформу. Это вносит в данные объяснений разнообразие.
Тестирование датасета и CAGE
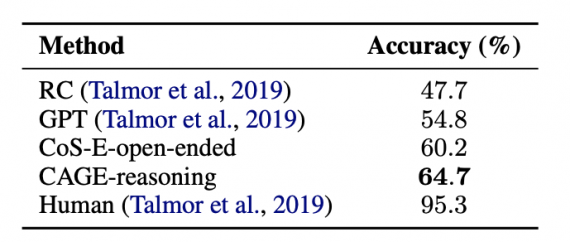
Исследователи предлагают модель для генерации человеческих объяснений — Commonsense Auto-Generated Explanations (CAGE).
CAGE — это языковая модель, которая адаптирована под задачу генерации человеческих объяснений. В основе CAGE лежит BERT. Результаты языковой модели исследователи проверяли на датасете CQA. В качестве базового подхода был стандартный предобученный BERT — один из state-of-the-art методов в обработке естественного языка. CoS-E-open-ended — это BERT модель, которая обучалась на открытых объяснениях из датасета CoS-E.
Видно, что CAGE выступает лучше state-of-the-art подходов.