FAIR опубликовали самый крупный датасет для распознавания речи. Libri-light содержит 60 тысяч часов неразмеченной речи на английском языке.
Данные для Libri-light собирали из общедоступных аудиофайлов и адаптировали для задачи автоматического распознавания речи (ASR) без размеченных данных. В качестве источника данных создатели использовали библиотеку с аудиокнигами LibriVox.
Предыдущие схожие датасеты обычно состояли из размеченных людьми обучающих примеров, которые подавались на вход ASR системе. Преимущественно ASR системы максимизировали supervised функцию потерь.
Кроме обучающего и тестового наборов данных, Libri-light содержит метрики и базовые модели для решения ASR. Цель создания датасета в том, чтобы спровоцировать исследования ASR систем, которые не зависят от размеченных данных или зависят в меньшей степени.
Данные в датасете были предобработаны:
- Отфильтрованы не работающие аудиофайлы и дупликаты;
- Добавлены метаданные речи, спикера и жанра
Базовые модели
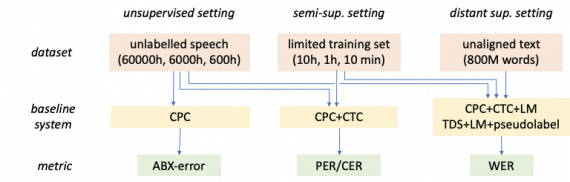
Исследователи обучили базовые модели и прописали метрики для оценки моделей поверх популярной ASR задачи LibriSpeech. Модели обучили тремя способами: Self-supervised, Semi-supervised и Distant supervision. Libri-light поддерживает 3 способа обучения, которые в меньшей степени опираются на размеченные данные:
- Предобучение акустических моделей на сырых неразмеченных данных;
- Обучение модели на миксе размеченных и неразмеченных данных;
- Обучение на не сопоставленных текстовых и аудио данных
Предобучение self-supervised модели на сырых аудиозаписях показало более точные результаты, чем state-of-the-art нейросеть в соревновании Zero Resource Speech Challenge.