Команда из более чем 50 исследователей со всего мира — из Berkeley, Stanford, CMU, Oxford и других университетов — опубликовала Very Big Video Reasoning (VBVR) — огромный набор данных для обучения видеомоделей рассуждению. Это первый датасет такого масштаба, который учит видеомодели не просто генерировать последовательность кадров, а думать — решать задачи на пространство, физику, абстракцию и логику. На основе датасета авторы создали бенчмарк VBVR-Bench, который проверяет способность видеомоделей рассуждать. Дообученная на датасете VBVR открытая модель Wan2.2 превзошла все закрытые коммерческие модели, включая Sora 2 и Veo 3.1, в рассуждениях. Проект полностью открытый: датасет, веса обученной модели, код бенчмарка и генераторы задач доступны на GitHub и Hugging Face.
Зачем это вообще нужно?
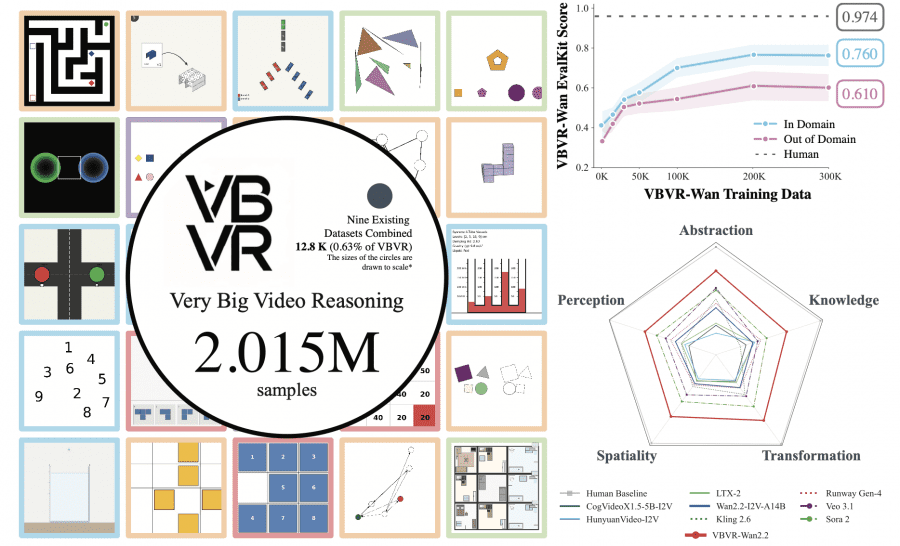
Современные видеомодели — Sora, Veo, Kling, Wan — умеют делать потрясающе реалистичные ролики. Но если попросить их решить задачу на навигацию в лабиринте или симулировать физику мяча, они не справляются. Проблема не в генерации — проблема в рассуждении. А данных для обучения именно этому навыку почти не было: все существующие датасеты вместе взятые содержали около 12 800 примеров. VBVR — это 2 015 000 примеров. Разница примерно в 157 раз.
Как устроена таксономия задач
Авторы не просто набрали случайных задач. Они опёрлись на когнитивную науку — от Аристотеля до современной нейронауки — и выделили пять фундаментальных способностей человеческого разума, которые и легли в основу датасета.
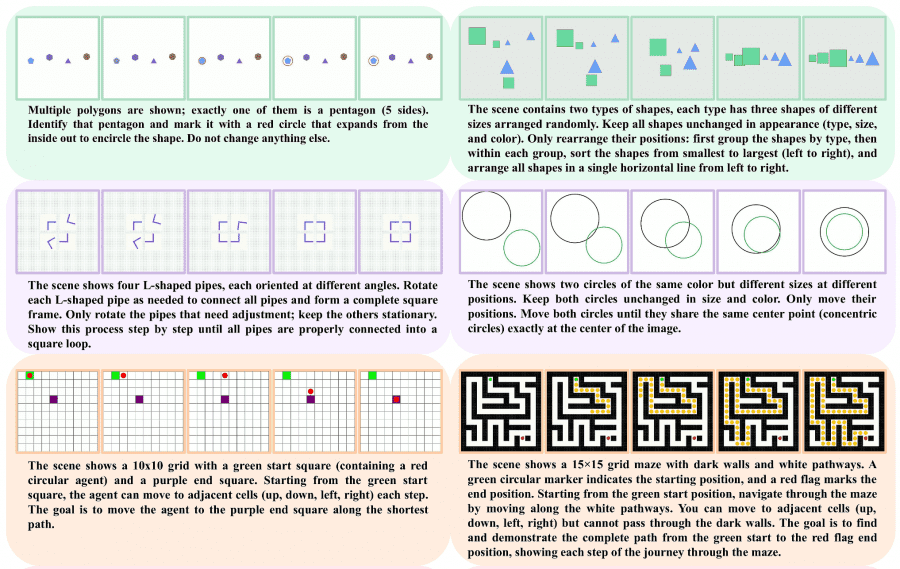
- Восприятие (Perception) — это умение вытащить структуру из сенсорного потока: определить цвет, форму, найти уникальный объект среди одинаковых.
- Трансформация (Transformation) — манипуляция с ментальными представлениями: вращение объектов в уме, предсказание траектории.
- Пространственность (Spatiality) — навигация, понимание геометрических отношений между объектами.
- Абстракция (Abstraction) — нахождение закономерностей и применение правил: матрицы Равена и задачи на сортировку.
- Знание (Knowledge) — применение фактов о мире: законы физики, поведение жидкостей, чтение часов.
Как генерируются данные
Вместо ручной разметки авторы написали параметрические генераторы — программы, которые создают задачи автоматически. Каждый генератор принимает набор параметров — размер сетки, количество объектов, расположение препятствий — и выдаёт четыре компонента: начальный кадр (first_frame.png), текстовую инструкцию (prompt.txt), финальный кадр (final_frame.png) и правильное решение в формате видео (ground_truth.mp4). Решение вычисляется алгоритмически — например, через поиск кратчайшего пути методом поиска в ширину.
Генерация запускается параллельно на 990 серверах AWS Lambda одновременно. Миллион примеров они генерируют примерно за 2–4 часа при стоимости около 800–1200 долларов за запуск. Каждый пример автоматически проверяется: существует ли решение, не перекрываются ли объекты, читается ли текст. Процент ошибок — меньше 1%.
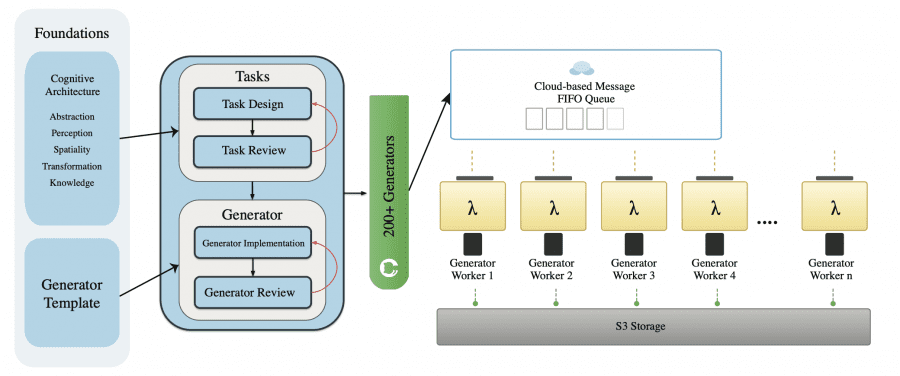
150 из 200 типов задач уже в открытом доступе, оставшиеся 50 придержали для честного лидерборда — чтобы никто не мог натренировать модель специально под бенчмарк.
Как оценивают модели
VBVR-Bench — это оценочный фреймворк, у которого есть одно принципиальное отличие от большинства аналогов: никаких LLM-судей. Оценка полностью детерминированная и основанная на правилах (rule-based). Для задачи на навигацию проверяется, дошёл ли агент до цели, не прошёл ли сквозь стены, насколько оптимальный путь выбрал. Для каждой из 100 тестовых задач — свой оценочный модуль с весами для разных критериев.
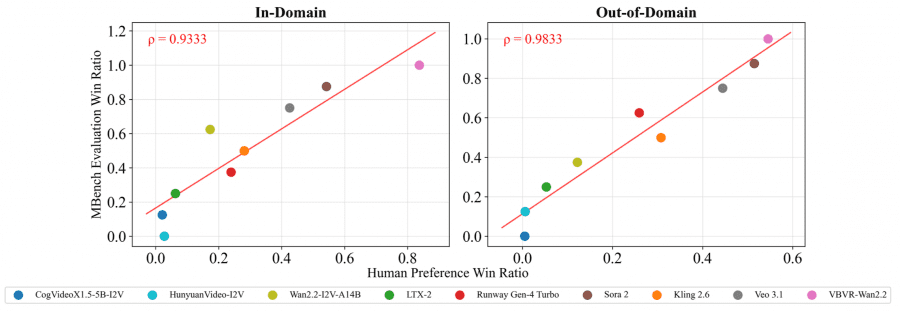
Чтобы убедиться, что автоматические оценки совпадают с человеческими суждениями, авторы провели масштабный эксперимент: аннотаторы смотрели видео и ставили оценки по трём критериям — выполнена ли задача, корректна ли логика рассуждений, хорошее ли качество видео. Корреляция Спирмена между автоматическими метриками и человеческими оценками — ρ > 0,93 для in-domain задач и ρ > 0,98 для out-of-domain. Это очень высокие значения.
Результаты
Итоги неутешительные для существующих моделей, но обнадёживающие для дообученной версии. Среди открытых моделей лучший результат у Wan2.2-I2V-A14B — 0,371 из 1,0. Среди закрытых лидирует Sora 2 с результатом 0,546, за ней Veo 3.1 с 0,480. Человеческий baseline — 0,974. Разрыв колоссальный.
Но когда авторы дообучили Wan2.2 на датасете VBVR с помощью LoRA адаптера с rank=32, результат вырос до 0,685 — это улучшение на 84,6% относительно базовой модели. VBVR-Wan2.2 обгоняет все остальные модели, включая закрытые коммерческие.
| Модель | Overall | In-Domain | Out-of-Domain |
|---|---|---|---|
| Human baseline | 0.974 | 0.960 | 0.988 |
| VBVR-Wan2.2 (fine-tuned) | 0.685 | 0.760 | 0.610 |
| Sora 2 | 0.546 | 0.569 | 0.523 |
| Veo 3.1 | 0.480 | 0.531 | 0.429 |
| Runway Gen-4 | 0.403 | 0.392 | 0.414 |
| Wan2.2 (base) | 0.371 | 0.412 | 0.329 |
Как растёт качество с увеличением данных
Авторы обучали модель на разных объёмах данных — от 0 до 500 000 примеров — и смотрели, как меняется результат. Результаты показали: от 0 до 200K примеров прирост очень заметный (с 0,412 до 0,767 на in-domain задачах). После 200K кривая выходит на плато и начинает колебаться. Это говорит о том, что просто добавить больше данных того же типа недостаточно — нужны архитектурные изменения или принципиально новые типы задач.
Важный момент: и in-domain, и out-of-domain результаты растут вместе, что указывает на реальное обобщение, а не просто запоминание. Разрыв между ними остаётся около 15%, и это следующая большая проблема для исследователей.
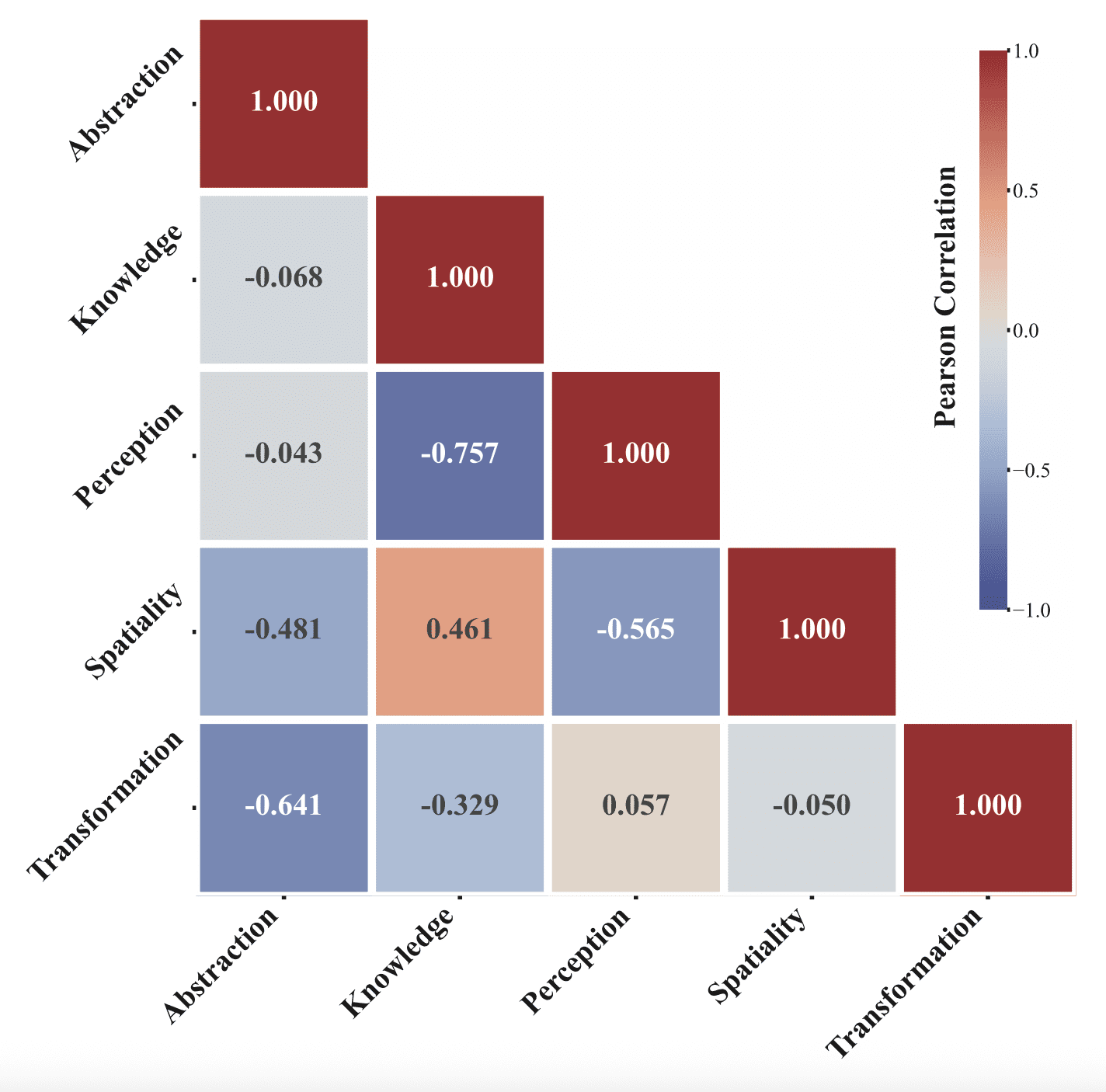
Интересные паттерны в способностях моделей
Авторы обнаружили нетривиальную структуру в том, какие когнитивные способности развиваются вместе. После того как убрали общий фактор «силы модели» (модели, которые сильнее в целом, сильнее везде), то оказалось, что Knowledge и Spatiality сильно коррелируют (ρ = 0,461). Это перекликается с нейронаукой. В мозге есть гиппокамп — область, которая отвечает за навигацию в пространстве. Там живут два типа нейронов: «клетки места» (place cells) — они активируются, когда ты находишься в конкретной точке пространства, и «клетки сетки» (grid cells) — они создают что-то вроде внутренней координатной карты мира. Нобелевскую премию за их открытие дали в 2014 году. Но оказалось, что тот же гиппокамп нужен не только для навигации — пациенты с его повреждениями хуже усваивают абстрактные концепции и факты. То есть пространственное мышление и накопление знаний в мозге завязаны на одну и ту же структуру. Похожий паттерн авторы обнаружили и у видеомоделей: те из них, что лучше справляются с пространственными задачами, как правило, лучше и в задачах на знание фактов.
Knowledge и Perception, напротив, отрицательно коррелируют (ρ = −0,757): модели, которые хорошо «знают факты», хуже воспринимают сенсорную информацию напрямую.
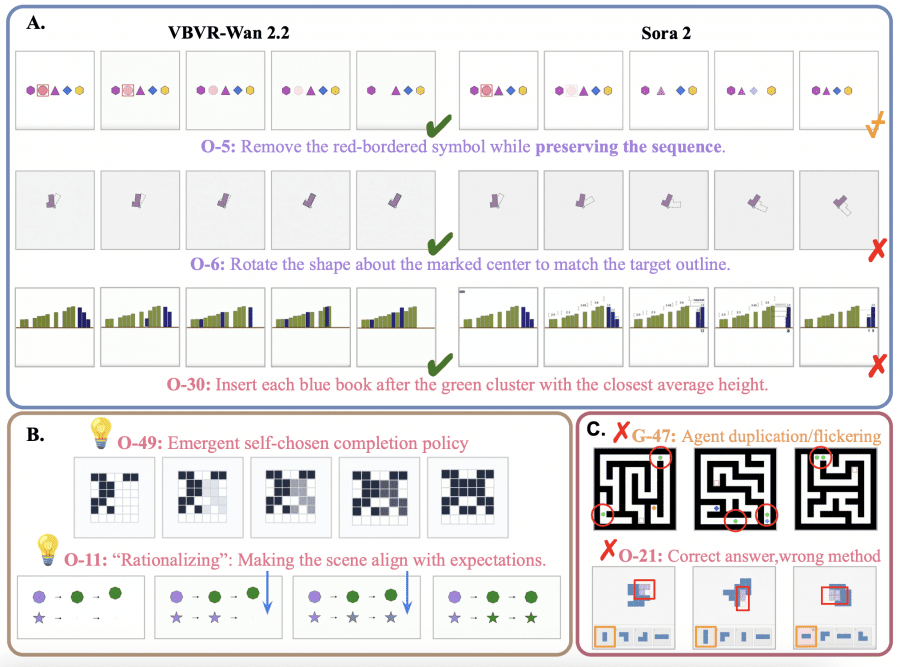
Главный вывод: controllability — фундамент рассуждения
Качественное сравнение на задачах, которые модель не видела во время обучения, показывает разницу наглядно. После дообучения VBVR-Wan2.2 научилась делать «ровно то, что попросили» — удалить символ без лишних изменений, повернуть объект вокруг нужной точки, а не вместе с рамкой. Sora 2 на тех же задачах добавляла лишние операции или теряла контроль над сценой. Это говорит о том, что controllability — способность точно следовать ограничениям — это предпосылка для верифицируемого рассуждения, а не отдельная опциональная фича.
VBVR — это не просто датасет, это инфраструктура: генераторы задач можно расширять, новые типы задач добавлять через стандартизированный шаблон, а бенчмарк будет обновляться вместе с полем. Всё это делает его бенчмарком, который не устареет сразу после публикации.








