
Jiant — это библиотека на Python для решения задач из области обработки естественного языка. Разработкой библиотеки занимаются исследователи из NYU. Jiant включает в себя модели для multitask и transfer обучения.
Подробнее о библиотеке
Среди характеристик Jiant можно отметить следующие:
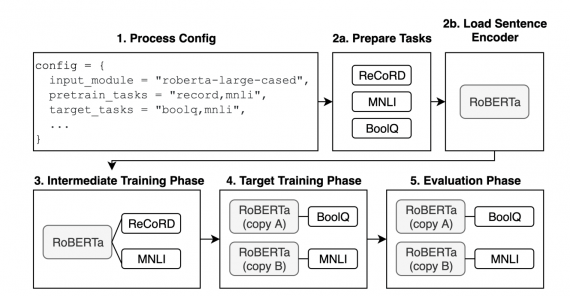
- Работа с библиотекой основана на изменении конфигурационных файлов. Это позволяет без значительных временных затрат менять параметры экспериментов. Помимо этого, есть возможность расширять существующую кодовую базу, если необходим функционал, который на данный момент недоступен;
- В библиотеке есть реализации базовых моделей для задач из GLUE и SuperGLUE датасетов;
- Библиотека поддерживается лабораторией Machine Learning for Language Lab в NYU;
- Jiant основан на PyTorch и использует компоненты из AllenNLP и библиотеки Transformers от HuggingFace
Модель
Модели в jiant имеют три составляющие:
- Входной компонент: обычно это слой с эмбеддингом или предобученная ELMo, GPT, BERT или XLNet модель;
- Общий кодировщик, который идет поверх входного блока: это опциональный компонент, обычно BiLSTM, которую обучили с нуля;
- Компоненты, характерные для отдельных задач
Входные компоненты
Разработчики использовали реализацию ELMo из AllenNLP. Для CoVe модели взяли реализацию от Salesforce. В jiant в качестве входного компонента можно использовать готовые предобученные векторы FastText или GloVe.
Кодировщики
На данный момент в библиотеке доступны энкодеры из следующих архитектур: BERT, XLNet, GPT, GPT-2, Transformer-XL, XLM или RoBERTa.

Tagged in: Обработка естественного языка


