Учёные из Лаборатории информатики и искусственного интеллекта (CSAIL) в MIT представили нейросеть, которая распознаёт объекты на изображении, сопоставляя их с голосовым описанием. Исследователи считают, что разработка может улучшить технологии распознавания речи и перевод с редких языков, которые не имеют достаточно данных для обучения моделей.
Сопоставление изображения и звука
Авторы используют две свёрточные нейросети (CNNs). Первая обрабатывает изображение, раскладывая его на сетку с пикселями, а вторая обрабатывает аудиопоток, создавая спектрограмму голоса. Аудиопоток разделяется на участки длиной 1 секунду, чтобы захватить слово или два. Затем нейросеть сопоставляет части спектрограммы с определённой ячейкой с пикселями и ищет соответствие. Разработчики обучили модель на 400000 изображений. В результате алгоритм научился сопоставлять несколько сотен слов с объектами.
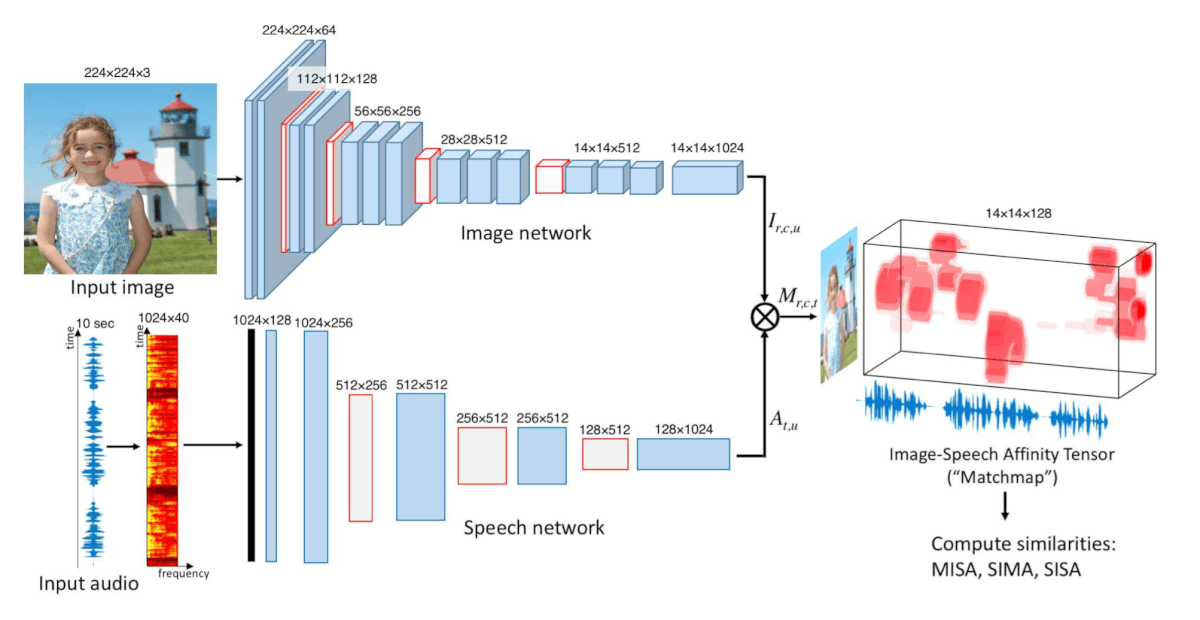
По мнению авторов, ключевое достижение исследования в доказательстве, что аудиовизуальные соответствия могут быть выведены автоматически. «Алгоритмы теперь могут связывать сегменты изображения со звуковыми элементами, не требуя при этом текста в качестве посредника» — отмечает Флориан Меце, профессор Института языковых технологий Университета Карнеги-Меллона.
Недавно исследователи из MIT создали нейронную сеть, которая распознаёт объекты на изображениях и видео и генерирует их текстовое описание. Алгоритм способен определять транформации объектов на видео в реальном времени с точностью 95%.