
Разработчики Google AI выложили в открытый доступ исходный код BERT (Bidirectional Encoder Representations from Transformers). Модель предназначена для предварительного обучения алгоритмов обработки естественного языка. После тренировки на больших наборах данных, модели смогут лучше справляться с последующими специфическими задачами.
Особенности BERT
В блоге компании отмечают, что BERT позволит разработчикам обучить NLP-модель за 30 минут на Google Cloud TPU или за несколько часов с помощью одного графического процессора. Обработка BERT является двунаправленной, т.е. учитывает прошлый и будущий контекст во время анализа предложений. Кроме того, подход основан на обучении без учителя, поэтому модель способна работать с неразмеченными и неклассифицированными данными.
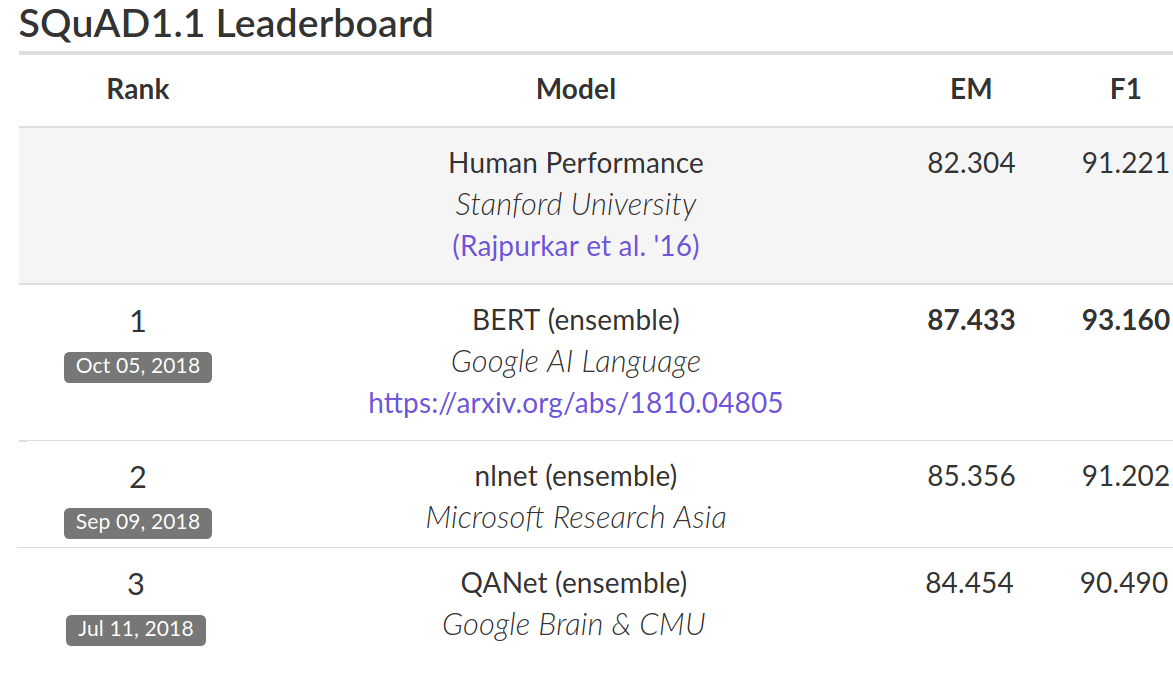
В тестировании на наборе данных для ответов на вопросы Stanford Question (SQuAD), точность работы модели составила 93,2%. На контрольном тесте GLUE он достиг точности 80,4%.
Релиз доступен на GitHub и включает в себя предварительно подготовленные модели на английском языке и исходный код, построенный на основе TensorFlow.








