Исследователи из Google Research предложили метод для распознавания объектов, которые сильно отличаются от объектов из обучающей выборки. Likelihood ratio — это метрика, которая минимизирует влияние заднего фона на предсказание и фокусируется на семантике.
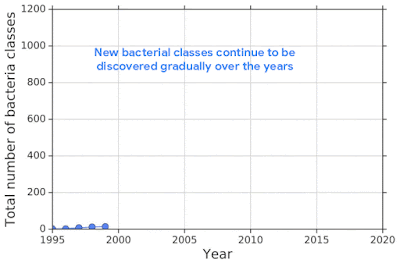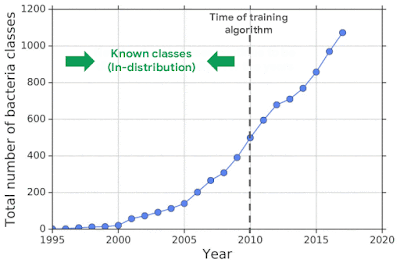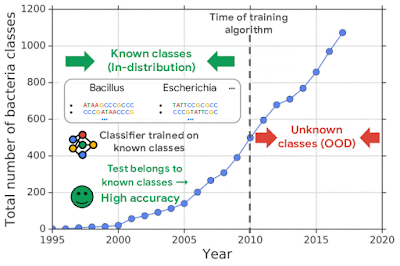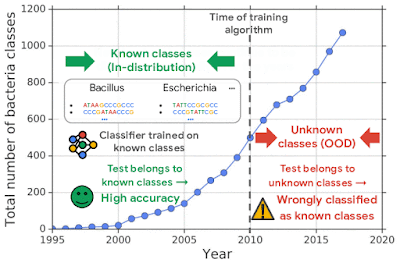
Успешное внедрение ML-систем требует, чтобы система умела отличать данные, которые значительно отличаются от тех, что были в обучающей выборке. Эта проблема актуальна для нейросетевых классификаторов. Нейросеть может присвоить объекту не из обучающей выборки (out-of-distribution или OOD) известный класс с высокой вероятностью. Такие ошибки критически важны в случаях, когда предсказания модели влияют на принятие решений в реальном мире.
Исследователи протестировали существующие методы для детектирования out-of-distribution объектов на данных генов. Предсказанные вероятности классов, которые выдает модель на выходе, для OOD объектов часто оказывались ошибочны. К такому же результату приходили в последних работах по генерации изображений. Чтобы решить эту проблему, исследователи предлагают likelihood-ratio подход. Предложенный метод значительно улучшает точность распознавания OOD данных.
Задача
Одним из применением моделей машинного обучения является распознавание бактерий по геномным последовательностям. Распознавание бактерий используется для диагностики и лечения инфекционных заболеваний. При этом появление новых классов бактерий — нередкое явление, которое не сразу отслеживается учеными. Нейросети, которые обучались на данных известных классов, могут ошибочно принять новый класс бактерии за ранее известный. Исследователи проверяют задачу распознавания OOD объектов на данных геномных последовательностей.
Чтобы синтезировать данные новых типов бактерий, исследователи использовали открытый каталог с геномными последовательностями от NCBI. Геномы были разделены на короткие последовательности с 250 парами. Затем были отделены данные для обучения и тестирования. В тестовую выборку попали типы бактерий, которые открыли после определенной даты. Модель не тестировалась на тех типах бактерий, которые были в обучающей выборке.
Likelihood ratio метрика
Likelihood ratio — это метод, который исключает влияние заднего фона на предсказание и фокусируется на семантике. Сначала обучается модель для заднего фона на модифицированных входных данных. Модификации вдохновлены генетическими мутациями. Случайно отбирается позиция в последовательности, и значение заменяется на другое с той же вероятностью. Для последовательностей ДНК значение выбирается из возможных нуклеотидов: A, T, C или G. Затем рассчитывается likelihood ratio между полной моделью и моделью заднего фона. Likelihood ratio является метрикой, которая отражает, насколько при предсказании учитывалась семантика, а не задний фон изображения.
Использование likelihood ratio метрики позволяет улучшить распознавание OOD объектов в тестовой выборке. На MNIST датасете AUROC метрика качества предсказания OOD возросла с 0.089 до 0.994.
