FastSpeech — это нейросетевая модель для генерации речи из текста. Нейросеть работает на инференсе быстрее state-of-the-art подходов в 38 раз.

Зачем нужна FastSpeech
Нейросетевые модели на текущий момент являются state-of-the-art решением задачи генерация речи из текста (TTS). Обычно такие модели сначала генерируют спектрограмму (mel-spectrogram) из текстовой последовательности. Затем vocoder синтезирует из полученной спектрограммы аудиозапись.
Однако у текущих state-of-the-art архитектур есть ряд ограничений:
- Медленная скорость авторегрессивной генерации спектрограмм при том, что обычно длина последовательности составляет сотни или тысячи кадров;
- Неустойчивость модели при генерации речи: слова пропускаются или повторяются из-за распространения ошибки и неверного распределения внимания;
- Отсутствие контроля из-за того, что длина сгенерированной последовательности определяется автоматически: скорость голоса и паузы между словами не регулируются вручную
Для того, чтобы избавиться от вышеперечисленных ограничений, исследователи из Microsoft предложили FastSpeech.
Архитектура модели
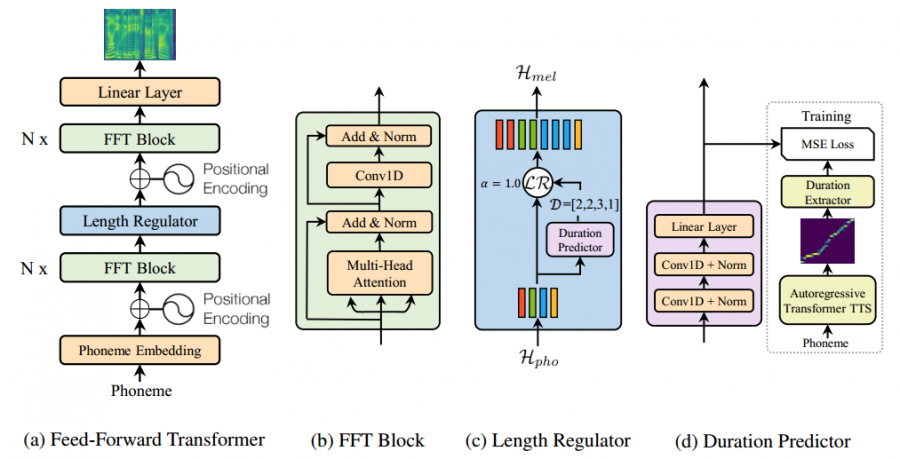
FastSpeech состоит из следующих частей:
- Feed-Forward Transformer. Ключевым блоком в трансформере является feed-forward transformer block (FFT), который состоит из механизма самовнимания и 1D конволюции. FFT отвечает за генерацию спектрограммы из входного текста;
- Регулятор длины. Одна фонема соответствует нескольким спектрограммам. С помощью регулятора длины можно корректировать длительность фонемы, чтобы изменять скороть голоса и паузы между словами;
- Предсказатель длительности. Эта часть нейросети состоит из двухслойной 1D конволюции и линейного слоя, чтобы предсказать длительность фонемы
Тестирование модели
Исследователи протестировали модель на скорость работы на инференсе и на качество генерируемых аудиозаписей. Для оценки качества провели опрос 20 добровольцев, которые ранжировали сгенерированные разными моделями аудиозаписи по предпочтени. Скорость работы на инференсе сравнивали с авторегрессионной Transformer TTS моделью с схожим количеством параметров модели. FastSpeech ускоряет генерацию спектрограмм в 270 раз и весь процесс генерации аудио из текста — в 38 раз.