Исследователи из DeepMind обучили мультиагентную систему, которая играет в Quake III Arena: Capture The Flag так же хорошо, как человек. Методы обучения с подкреплением (RL) показывают хорошие результаты в случае среды с одним агентом. В реальном мире агент взаимодействует с другими агентами и принимает решение на основе взаимодействия. Проблема обучения множества агентов принимать решения независимо и сообща пока открыта.
Агенты должны были научиться видеть, принимать решения, кооперироваться и соревноваться в неизвестной ранее среде. Все на основе одного сигнала — является ли ближайший агент членом его команды или нет.
Для этого исследователи обучают агентов, опираясь на следующие идеи:
- Вместо того, чтобы тренировать одного агента, они тренируют популяцию агентов, которые учатся во время игры друг с другом;
- Каждый агент в популяции генерирует собственные локальные цели (например, захватить флаг) — агенты одновременно учатся оптимизировать свою стратегию взаимодействия с другими агентами, чтобы достичь локальную цель;
- Агенты действуют в двух временных режимах: быстром и медленном, — это улучшает их способность использовать память и генерировать последовательные цепочки решений
Агент объединяет в себе 2 рекуррентные нейросети для быстрого и медленного режимов, модуль памяти. Баллы из игры агент конвертирует в персональную награду. Выученные политики поведения агентов устойчивы к размеру среды, количеству сокомандников и поведению других агентов в команде.
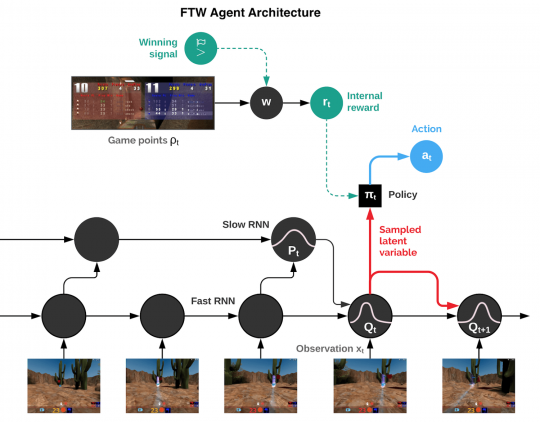
Мультиагентная система vs. Человек
Чтобы проверить, как система выступает может сравниться с человеком, был проведен турнир с 40 людьми. Люди и обученные агенты были случайно объединены в команды.
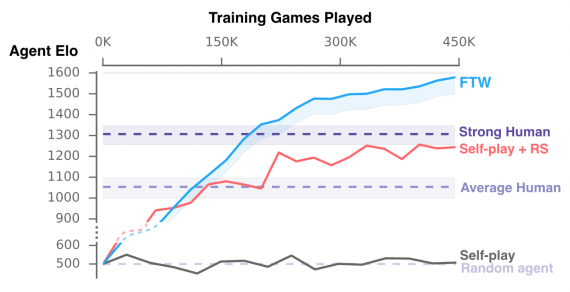
Обученные агенты со увеличением количества игр начинают обгонять сильных игроков. Опрос показал, что агенты системы сотрудничали больше, чем игроки-люди.
Видеодемонстрации и симуляции доступны по ссылке.