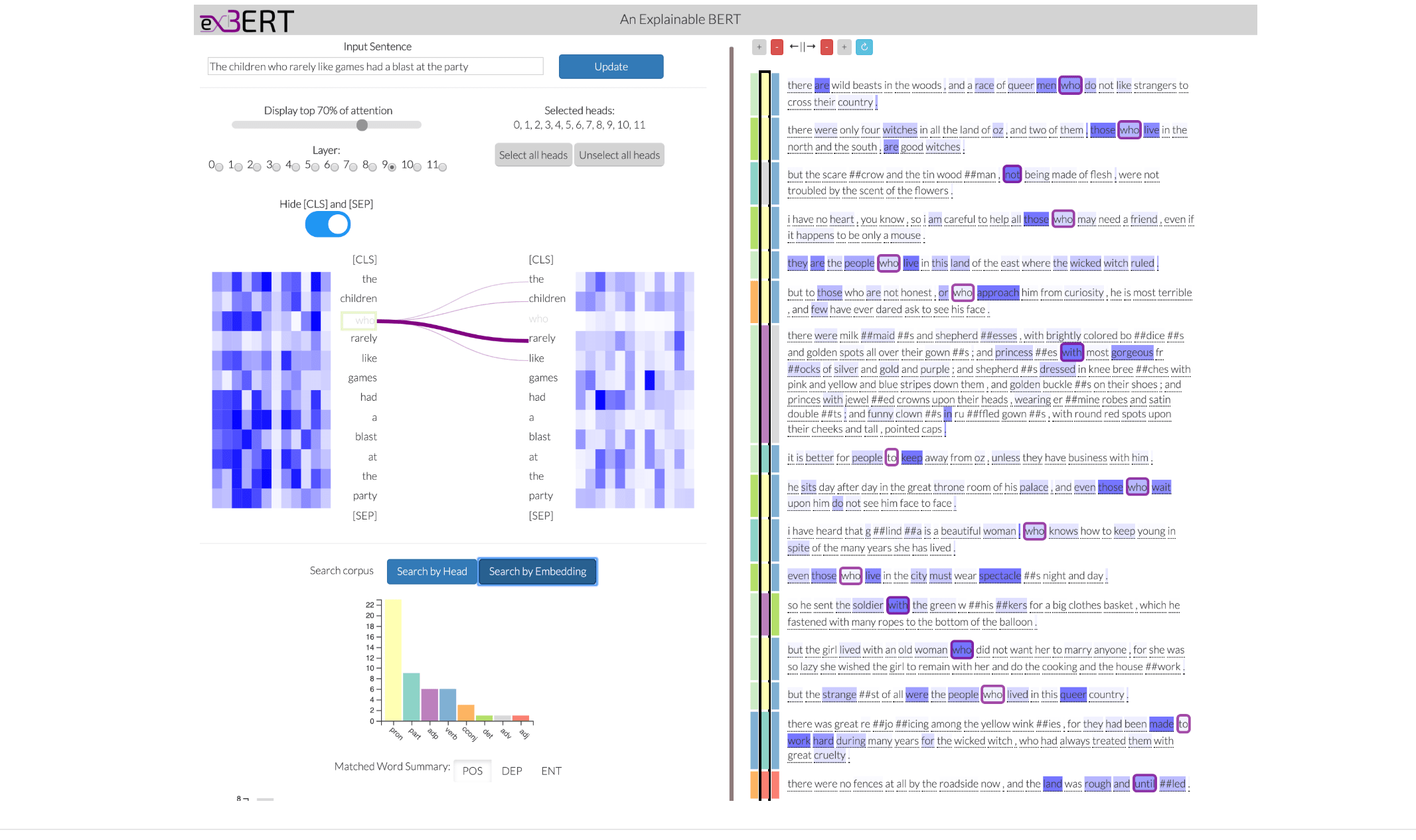
exBERT — это интерактивный инструмент для визуализации механизма внимания в обученной языковой модели. Инструмент позволяет исследовать, как языковая модель формирует пространство скрытых представлений. exBERT сопоставляет выбранные пользователем слова на входе модели с их схожими по контексту словами из выученного пространства. Система агрегирует аннотации наиболее близких по контексту слов. Это помогает интуитивно объяснить, что выучил каждый из механизмов внимание. Разработкой системы занимались исследователи из IBM Research и Harvard SEAS.
Крупные языковые модели хорошо справляются с контекстуальным представлением единиц измерения (слов, предложений и т.п.). Это ведет к значительным улучшениям качества моделей обработки естественного языка. В связи с тем, что обычно такие модели имеют последовательность обучаемых механизмов внимания и множество внутренних смещений, важно исследовать, как модель научилась распределять внимание. Методы статического анализа обученных моделей не позволяют динамически отслеживать процесс формирования решений внутри модели на разных ее этапах.
Обзор системы
Чтобы понять, как работает система, необходимо разобраться в том, что такое механизм внимания в современных языковых моделях. Работа exBERT делится на следующие шаги:
- Пользователь вводит предложение в строку;
- Отбирает интересующие механизмы внимания по их индексу;
- Токены и attention heads, которые были заданы, ищутся по размеченному корпусу;
- Система выдает результат;
- Каждый токен в результаты представляется с лингвистическими метаданными;
- Дается сводка наиболее близких токенов к входному токену;
- Гистограммы внизу показывают метаданные результатов для входного токена и токен с максимальным вниманием для входного токена
В начале статьи пример работы системы для токена “escape”.



