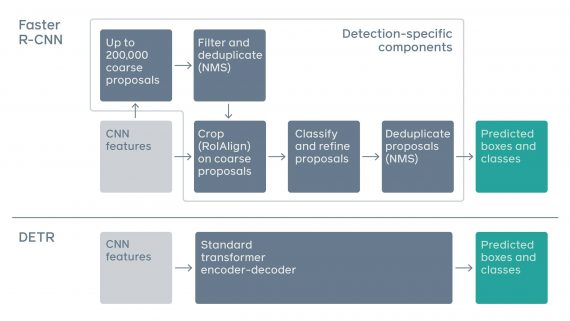
DEtection TRansformers (DETR) — это нейросетевой подход для распознавания объектов и паноптической сегментации объектов на изображении. DETR использует в своей основе архитектуру Transformer. Нейросеть выдает сравнимые с state-of-the-art результаты на датасете COCO. При этом в сравнении с стандартными моделями для распознавания объектов новый подход имеет облегченную архитектуру.
Что внутри DETR
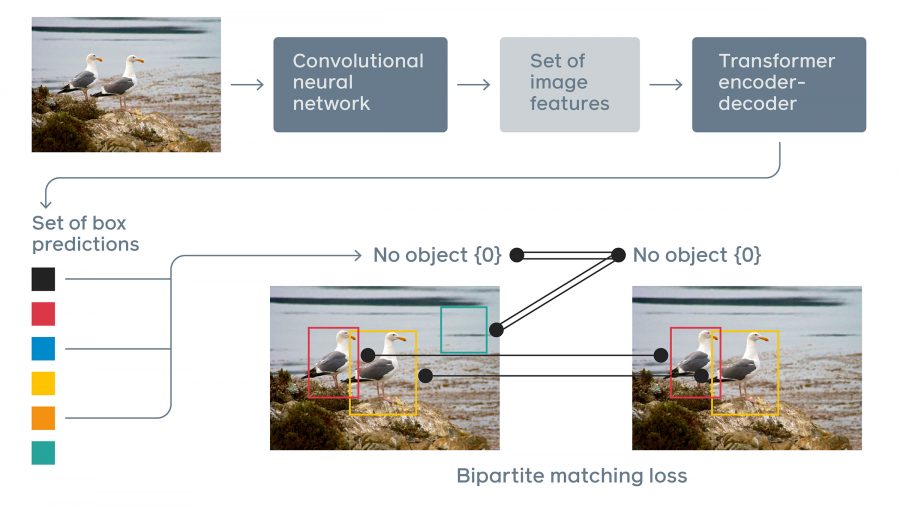
DETR решает задачу распознавания объектов как image-to-set задачу. На вход модель принимает изображение, а на выходе она отдает список из всех объектов на снимке. Каждый объект содержит класс, к которому он принадлежит, и границы (bounding box).
Пайплайн подхода состоит из двух шагов:
- На первом этапе сверточная нейросеть извлекает из изображения локальную информацию;
- Затем энкодер-декодер архитектура Transformer генерирует предсказания
Transformer предсказывает положение и класс объектов параллельно. Это возможно благодаря специальной глобальной функции потерь. Self-attention механизм в Transformer позволяет модели опираться на отдельные участки изображения при предсказании.
Подход масштабируется на такие задачи, как паноптическая сегментация. Цель паноптической сегментации заключается в том, что бы распознать объекты и на заднем, и на переднем фоне изображения. DETR выдает предсказания как для объектов на заднем фоне, так и для объектов на переднем фоне.
Использование Transformer в архитектуре позволяет улучшить интерпретируемость моделей компьютерного зрения. Механизм внимания позволяет смотреть, на какие участки изображения модель обращала большее внимание при предсказании.






