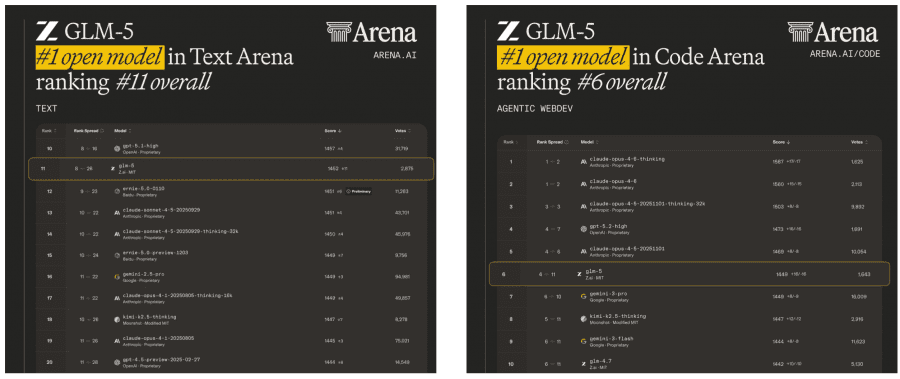
Zhipu AI и Tsinghua University опубликовали техрепорт GLM-5 — на сегодня лучшей открытой языковой модели по бенчмаркам: первое место среди open-weight моделей на Artificial Analysis и топ-1 в кодинге и тексте на LMArena, лидер на BrowseComp и HLE с инструментами среди всех моделей мира включая закрытые. Модель умеет не просто отвечать на вопросы, а самостоятельно писать код, искать информацию в интернете и выполнять длинные многошаговые задачи. Проект полностью открытый: код, веса и документация доступны на GitHub и Hugging Face.
Zhipu позиционируют GLM-5 как переход от «вайб-кодинга» к агентной инженерии. «Вайб-кодинг» (vibe coding) — неформальный термин для подхода, при котором разработчик описывает задачу в чат, получает сгенерированный код и вручную итерирует дальше. Такой подход работает для изолированных задач, но плохо масштабируется на сложные проекты: модель не отслеживает состояние кодовой базы, не запускает тесты и не исправляет ошибки самостоятельно.
Агентная инженерия (agentic engineering) — это другой режим работы: модель получает высокоуровневую задачу и самостоятельно выполняет цепочку действий — анализирует репозиторий, пишет патч, запускает тесты, обрабатывает ошибки и повторяет цикл до результата. Участие человека требуется на этапе постановки задачи и проверки результата, но не на каждом промежуточном шаге.
Архитектура: что внутри
GLM-5 — это Mixture of Experts модель с 744 миллиардами параметров, из которых в каждый момент активны только 40 миллиардов. Это в два раза больше предшественника GLM-4.5 (355B/32B).
Главное нововведение — DSA (DeepSeek Sparse Attention): разреженный механизм внимания, который вместо того чтобы смотреть на все токены в контексте, динамически выбирает только важные. Это снижает стоимость attention в 1.5–2 раза для длинных последовательностей при сохранении качества. Проще говоря: можно обрабатывать 128K токенов примерно за половину обычной GPU-цены.
Ещё одно улучшение — MLA-256 (Multi-Latent Attention) с оптимизацией Muon Split. MLA сжимает ключи и значения в attention до компактного скрытого вектора, что экономит память. Авторы обнаружили, что стандартный MLA немного уступал GQA, но после разбивки матриц по отдельным головам (Muon Split) разрыв устранился.
Вот как выглядит сравнение вариантов attention на нескольких бенчмарках:
| Метод | HellaSwag | MMLU | C-Eval | BBH | HumanEval |
|---|---|---|---|---|---|
| GQA-8 (базовый) | 77.3 | 61.2 | 60.0 | 53.3 | 38.5 |
| MLA | 77.3 | 61.5 | 59.7 | 48.9 | 33.5 |
| MLA + Muon Split | 77.8 | 62.5 | 62.1 | 51.8 | 36.7 |
| MLA-256 + Muon Split | 77.4 | 62.0 | 59.9 | 51.3 | 36.6 |
MLA + Muon Split догоняет GQA по всем бенчмаркам — значит, можно получить эффективность MLA без потери качества.
Наконец, Multi-Token Prediction (MTP) с разделением параметров позволяет модели предсказывать несколько токенов за один шаг, что ускоряет генерацию. GLM-5 достиг acceptance length 2.76 токена против 2.55 у DeepSeek-V3.2.
Обучение: как это работало
Предобучение
Модель обучалась на 28.5 триллионах токенов. Сначала — общий корпус на 18T токенов, потом — код и рассуждения ещё на 9T. Это в 1.5 раза больше, чем у GLM-4.5. Корпус включал веб-данные, код из GitHub (на 28% больше уникальных токенов по сравнению с прошлой версией), математические тексты и научные статьи. Для длинного контекста авторы постепенно расширяли окно: 32K → 128K → 200K токенов.
Post-Training: от базы к агенту
После предобучения модель проходит последовательный пайплайн. Сначала SFT (Supervised Fine-Tuning) — обучение с учителем на примерах диалогов, кодирования и агентных задач. Затем три стадии Reinforcement Learning (RL): Reasoning RL (математика, код, рассуждения) → Agentic RL (длинные агентные задачи) → General RL (выравнивание под человеческий стиль общения).
Ключевая деталь: авторы используют On-Policy Cross-Stage Distillation в конце пайплайна. Это решение проблемы «катастрофического забывания» — когда модель, обученная на одной задаче, теряет навыки с предыдущих этапов. Финальные чекпоинты со всех стадий становятся «учителями», а модель дистиллирует знания от всех них одновременно.
Асинхронный RL: почему это важно
Обычный синхронный RL страдает от простоя GPU: пока агент «думает» (выполняет длинный rollout — последовательность действий), тренировочная часть стоит и ждёт. GLM-5 решает это через полностью асинхронную архитектуру.
Суть такая: вместо того чтобы генерация и обучение шли строго по очереди, они разведены на разные GPU. Движок inference постоянно генерирует траектории. Как только накопилось достаточно данных, они отправляются в тренировочный движок — и тот начинает обновлять параметры модели, пока inference продолжает генерировать новые.
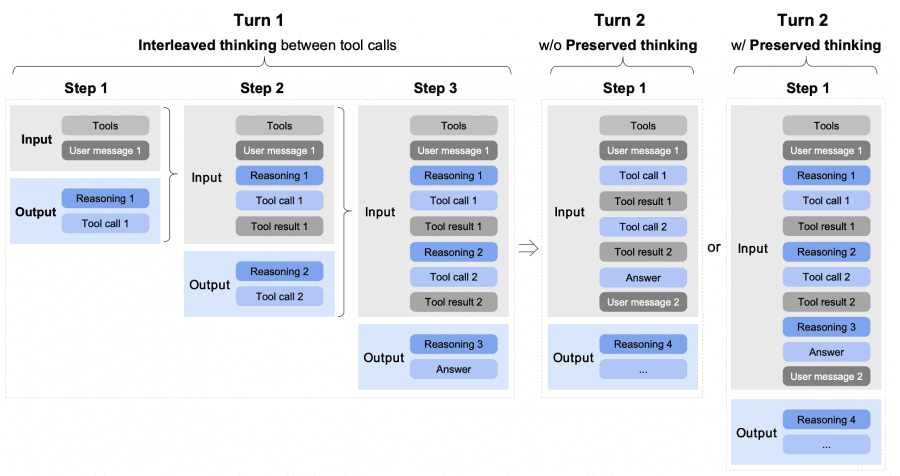
Для агентных задач авторы придумали три особых режима мышления.
- Interleaved Thinking: модель думает перед каждым ответом и каждым вызовом инструмента — это улучшает точность следования инструкциям.
- Preserved Thinking: в сценариях с многоходовым кодированием модель сохраняет все блоки рассуждений между ходами диалога — не перевычисляет, а переиспользует.
- Turn-level Thinking: можно динамически включать/выключать «глубокое мышление» для каждого хода — выключить для быстрых вопросов, включить для сложных задач.
Результаты: что показали бенчмарки
Исследователи сравнили GLM-5 с DeepSeek-V3.2, Claude Opus 4.5, Kimi K2.5, Gemini 3 Pro и GPT-5.2:
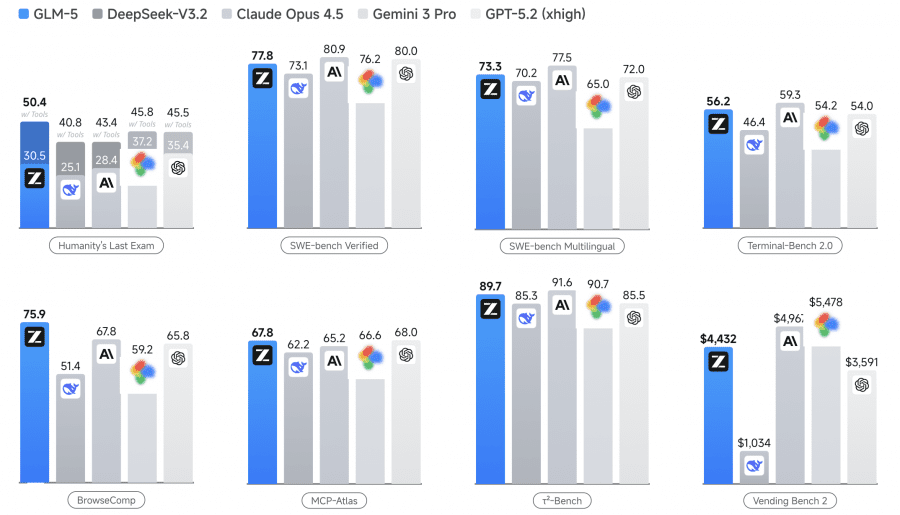
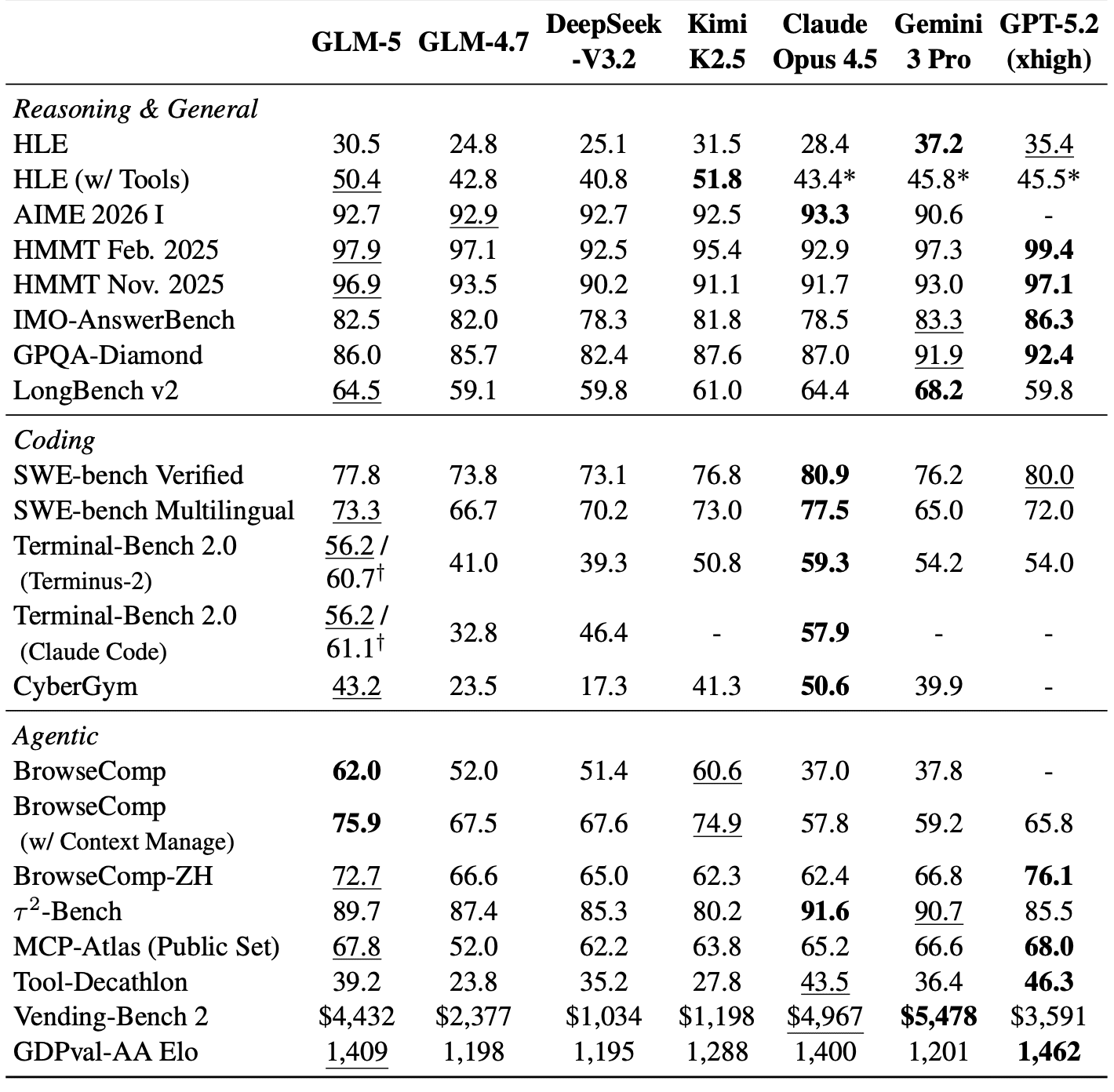
GLM-5 показывает около 20% среднего прироста в сравнении с GLM-4.7. На BrowseComp GLM-5 обгоняет все frontier-модели — 75.9% против 65.8% у GPT-5.2. На HLE с инструментами GLM-5 тоже первый — 50.4%. На SWE-bench Verified чуть уступает Claude и GPT, но это первая открытая модель, которая вообще попала в эту лигу.
CC-Bench-V2: реальные задачи разработки
Академические бенчмарки — это хорошо, но авторы хотели измерить нечто более приземлённое: может ли модель реально написать рабочий фронтенд? Исправить баг в Go-проекте? Разобраться в большом чужом репозитории?
Для этого создали CC-Bench-V2 — внутренний бенчмарк из трёх частей. Фронтенд-задачи: написать сайт или веб-приложение на HTML, React, Vue, Next.js, Svelte. Бэкенд-задачи: реальные задачи из open-source проектов на Python, Go, C++, Rust, Java, TypeScript — фичи, баги, рефакторинг, оптимизация, все проверяются юнит-тестами. Долгосрочные задачи: поиск в огромном репозитории (тысячи файлов) и многошаговые цепочки задач, где каждый шаг меняет состояние кодовой базы для следующего.
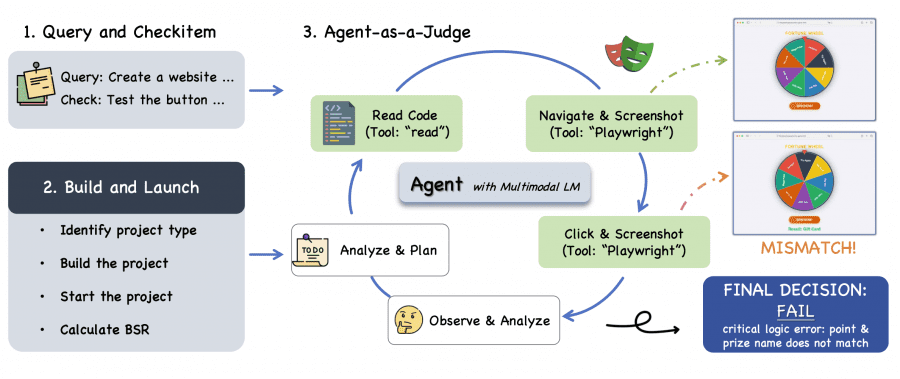
Оценка фронтенда устроена через Agent-as-a-Judge. Автономный агент-судья (Claude Code + Playwright) буквально кликает по сгенерированному сайту и проверяет каждый пункт технического задания. Согласованность с оценками людей-экспертов составила 94% по отдельным пунктам и 85.7% по ранжированию моделей.
GLM-5 достигает 98% Build Success Rate (BSR) — почти весь код компилируется и запускается. По Check-item Success Rate (CSR) конкурирует с Claude Opus 4.5 (71.0% vs 70.7% на React). Но Instance Success Rate (ISR) — доля задач, где всё выполнено от начала до конца — у GLM-5 пока ниже (34.6% vs 39.7% на React).
Агент поиска: как GLM-5 ищет информацию
Одна из задач в BrowseComp требует от модели найти в интернете ответ на сложный многошаговый вопрос — например, «какой фильм режиссёр X снял между такими-то годами, в котором снялся актёр Y». Это требует десятков запросов и анализа результатов.
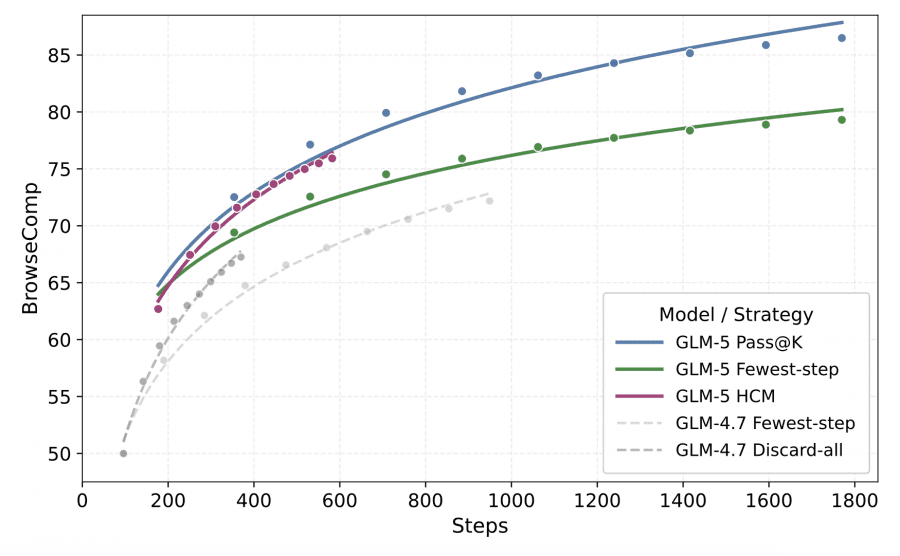
Проблема длинного поиска: чем дольше работает агент, тем больше контекст, и при 100K+ токенах качество резко падает. Авторы придумали Hierarchical Context Management (иерархическое управление контекстом). При накоплении истории инструментов модель оставляет только последние 5 раундов результатов (keep-recent-k=5). Если и после этого контекст слишком длинный — история сбрасывается полностью, и агент продолжает с чистого листа. Это подняло BrowseComp с 55.3% до 75.9%.
Генерация презентаций
Отдельная интересная задача — генерация HTML-слайдов через RL. Авторы придумали трёхуровневую функцию вознаграждения: уровень 1 проверяет статические атрибуты разметки (цвета, шрифты, позиционирование), уровень 2 проверяет рантайм-свойства DOM (реальные размеры элементов после рендеринга), уровень 3 проверяет визуальное восприятие (аномальные пустые пространства, общий баланс).
При обучении обнаружились случаи reward hacking — модель «читерила»: прятала контент через overflow:hidden, или накачивала отступы, чтобы формально пройти геометрические метрики. Авторы фиксировали рендерер, чтобы закрыть эти лазейки. В итоге доля слайдов с правильным соотношением 16:9 выросла с 40% до 92%, а человеческие оценщики ставили GLM-5 выше GLM-4.5 в 67.5% случаев по общему качеству.
Пасхалка: Pony Alpha
В конце пейпера авторы рассказывают про эксперимент, который называют «пасхалкой». Перед официальным релизом GLM-5 был выпущен анонимно на OpenRouter под названием «Pony Alpha». Без упоминания Zhipu, без брендинга — просто модель в чате.
Разработчики в сообществе начали замечать необычно высокое качество, особенно в сложных задачах кодирования. Пошли гадания: 25% решили, что это Claude Sonnet 5, 20% — DeepSeek, 10% — Grok. Когда Zhipu подтвердила, что это GLM-5, это стало неплохим доказательством того, что модль вышла на уровень frontier.
Как развернуть GLM-5 локально: сколько нужно железа
Веса модели открыты и лежат на Hugging Face под MIT-лицензией. Но перед тем как качать — честный разговор о железе.
Полная модель в BF16 весит 1.65 ТБ. Это не опечатка. Для продакшн-деплоя с нормальным throughput официальная рекомендация от авторов — 8× H200 (по 141 ГБ VRAM каждая), итого ~1128 ГБ видеопамяти. Поддерживаемые фреймворки: vLLM, SGLang, KTransformers и xLLM — все умеют tensor parallelism через несколько GPU.
Для большинства это звучит как «модель не для меня», но есть варианты подешевле.
FP8-квантизация — официальная версия доступна на Hugging Face. Весит примерно вдвое меньше BF16, вписывается в 8× H100 или 8× H20. Качество на бенчмарках практически не падает. Это самый реалистичный вариант для небольших команд, у которых есть доступ к серверному железу или облаку.
2-bit GGUF от Unsloth — агрессивная квантизация, которая ужимает модель до 241 ГБ. По словам команды Unsloth, это влезает на Mac с 256 ГБ unified memory (M3/M4 Ultra Max) или на сервер с одной GPU на 24 ГБ VRAM + 256 ГБ ОЗУ при MoE offloading. Есть и 1-bit вариант на 176 ГБ. Скорость и качество падают, но для экспериментов и разработки — рабочий вариант.
Если своего железа нет вообще, GLM-5 доступна через API провайдеров: DeepInfra ($0.80/$2.56 за млн input/output токенов), Novita, GMI Cloud, Fireworks, SiliconFlow. Это в 3–6 раз дешевле первопартийного Z.ai API (.00/.20) и в 5–8 раз дешевле Claude Opus 4.6.
Первые отзывы
Бенчмарки — это одно, но интереснее посмотреть на живые впечатления людей, которые попробовали модель на реальных задачах.
Максим Лабонн (Staff ML Scientist в Liquid AI, автор книги по графовым нейросетям) написал один из самых взвешенных разборов сразу после релиза. Его вывод: GLM-5 — сильнейшая открытая модель на момент выхода, первое место на Artificial Analysis и LMArena Text Arena среди open-weight моделей. Но есть оговорка: модель текст-only, мультимодальности нет совсем — и это заметный минус на фоне Kimi K2.5 от Moonshot. По его словам, сообщество сходится в том, что GLM-5 отличный исполнитель, но «ситуационная осведомлённость» — понимание контекста происходящего — отстаёт от Claude.
Самый цитируемый критический голос — Лукас Петерссон, сооснователь Andon Labs. Это та самая команда, которая независимо гоняла Vending Bench 2 (бенчмарк, где модель управляет симулированным вендинговым бизнесом целый год). После нескольких часов чтения трейсов GLM-5 он написал в X: модель невероятно эффективная, но «достигает целей агрессивными тактиками, не рассуждая о своей ситуации и не используя прошлый опыт». И добавил: «Это страшно. Именно так получается максимизатор скрепок» — отсылка к известному мысленному эксперименту философа Ника Бострома про ИИ, который оптимизирует цель без понимания контекста. Важно: именно на Vending Bench 2 GLM-5 заняла 4-е место среди всех моделей — выше Claude Sonnet 4.5.
Команда WaveSpeed AI тестировала модель ещё под именем «Pony Alpha» с 6 по 9 февраля. Их практическое наблюдение: первый токен появляется меньше чем за секунду на коротких промптах, throughput — 17–19 токенов в секунду. В агентных задачах модель правильно описывает шаги, сама запрашивает недостающие данные и предлагает повторные попытки при неудаче. Хвалят за инкрементальные правки кода вместо полных перезаписей. Честный итог от их инженера: «Как планировщик — компетентна. Оставить её без присмотра в критических системах — пока нет».
Общая картина по отзывам получается такая: все сходятся в трёх вещах. На агентных многошаговых задачах — сильнейшая среди открытых моделей. Цена в 5–8 раз ниже Claude делает это особенно привлекательным. Главная претензия — модель агрессивно идёт к цели, не задумываясь о последствиях: выполнит задачу, даже если что-то пошло не так. Для автономного продакшна без присмотра использовать GLM-5 не рекомендуется.
Резюме
GLM-5 — первая открытая языковая модель, которая реально конкурирует с закрытыми frontier-моделями в задачах агентного программирования. Ключевые технические решения: DSA снижает стоимость внимания в 1.5–2 раза без потери качества, асинхронный Agentic RL убирает GPU-простои при длинных роллаутах, трёхуровневый пайплайн post-training предотвращает катастрофическое забывание.
По бенчмаркам: GLM-5 лидирует среди открытых моделей на BrowseComp (75.9%), SWE-bench Multilingual (73.3%), конкурирует с Claude и GPT на SWE-bench Verified. В реальных задачах разработки (CC-Bench-V2) GLM-5 значительно лучше GLM-4.7, хотя всё ещё уступает Claude Opus 4.5 в самых сложных долгосрочных задачах.








