Graph2Diff — это графовая нейросеть, которая предлагает исправления для ошибок при сборке программы. Разработкой модели занимались исследователи из Google.
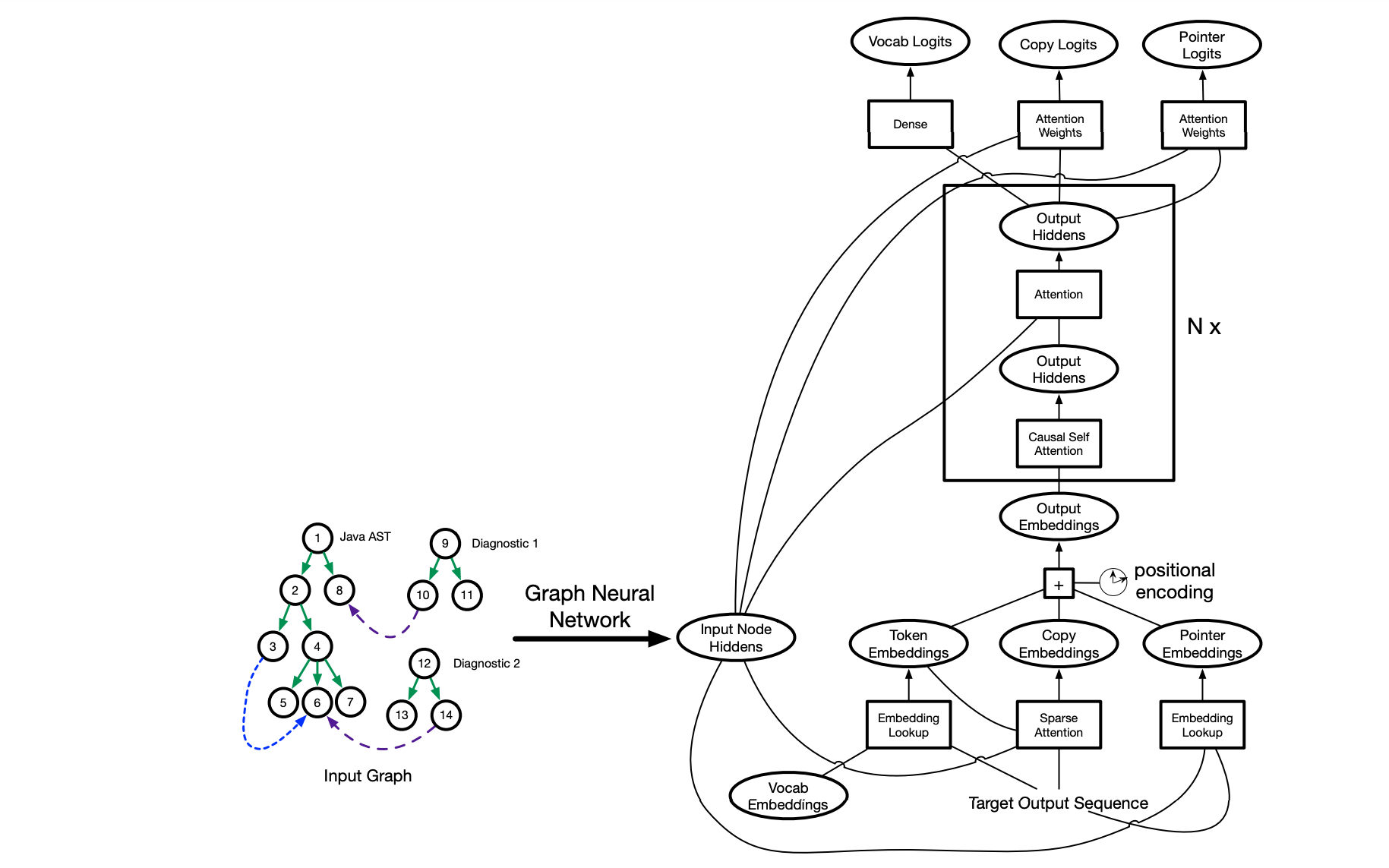
Профессиональные программисты тратят значительную часть времени на исправление ошибок при сборке программы. Несмотря на это, эта задача до сих пор не решается средствами автоматической починки программ. Исследователи предложили архитектуру Graph2Diff, чтобы автоматически находить и исправлять ошибки в коде при сборке программы. Исходный код, конфигурационные файлы сборки и диагностические сообщения компилятора представляются в виде графа. Затем графовая нейросеть предсказывает разницу. Разница — это те изменения, которые необходимо внести в AST программы, чтобы избавиться от ошибок. AST программы является представлением исходного кода программы в виде графа.
Graph2Diff — это пример более общей абстракции, которую исследователи называют Graph2Tocopo. Graph2Tocopo можно использовать в любом инструменте разработчиков для предсказания изменений исходного кода. Исследователи оценили работу Graph2Diff на датасете с более чем 500 тысячами реальных ошибок сборки и их решений. Данные предоставляли профессиональные разработчики.
В сравнении с подходом DeepDelta Graph2Diff решает более сложную задачу и при этом выдает в два раза более точные предсказания.
Как это работает
Graph2Diff сети соотносят графовое представление проблемного кода с корректной разницей, которая написана на специальном языке. Разница может содержать не только токены, но и указатели во входной граф и действия копирования. Примером указателя является команда “insert token HERE”.
Предложенная модель опирается на 3 ключевые архитектурные идеи: графовые нейросети, модели с указателями (pointer models) и механизмы копирования. В качестве кодировщика входных данных используется GGNN. Декодировщик — это нейросеть, которая предсказывает необходимое редактирование кода.

Тестирование модели
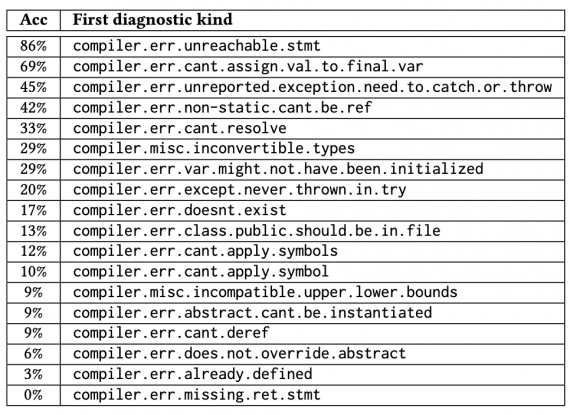
Ниже можно посмотреть на точность предсказаний модели для разных типов ошибок сборки. Типы ошибок были выбраны так, чтобы каждый тип встречался как минимум 10 раз в валидационном наборе данных.

исправте пж код true_number = 4 print(«Привет! Я подарю тебе стикеры, если ты угадаешь, какое число я загадал!») your_variant = int(input(«Твой вариант:»)) while: print(«Не угадал!») … Подробнее »