Улучшенная стратегия обучения нейронных сетей позволила IBM значительно увеличить эффективность средства преобразования речи в текст. Сервис работает на восьми языках и предоставляет рекордно высокую скорость обработки телефонных разговоров.
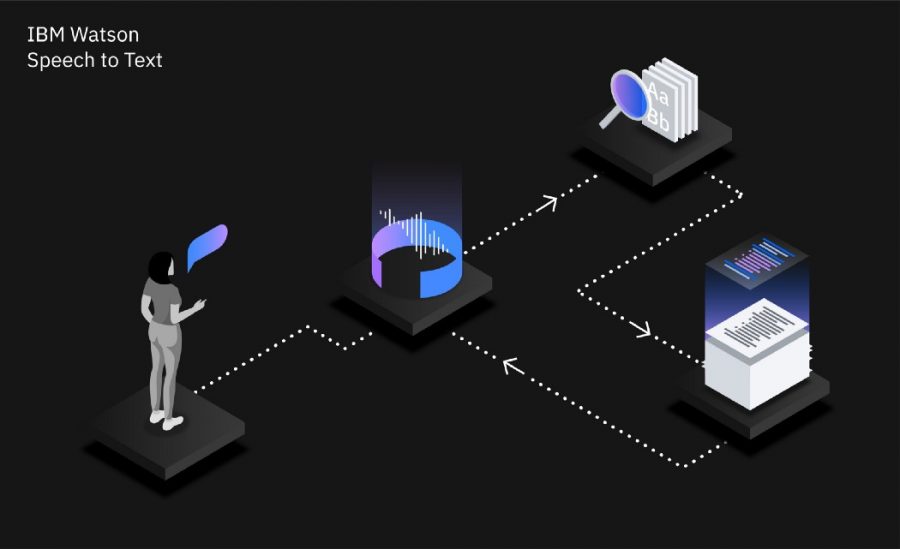
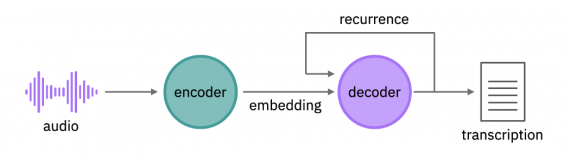
Модель состоит из энкодера и декодера (рис. 1). Энкодер формирует векторное представление звука, то есть генерирует многомерное разложение, которое можно использовать для задач классификации. Рекуррентная нейронная сеть извлекает признаки из звукового сигнала на различных уровнях абстракции. Нейросеть являются двунаправленной, что позволяет лучше предсказать правильную транскрипцию. Работает это так: приложение дважды «слушает» аудиозапись, и при втором прослушивании может более точно распознать произнесенные слова. Затем декодер делает предсказание для каждого символа на основе векторного представления и уже распознанных символов. Таким образом, модель предсказывает слово на основе его звучания и соседних слов.
Приложение работает с речью на восьми языках, причем для шести из них доступен режим сверхмалой задержки, позволяющий использовать Watson Speech to Text для общения клиентов с телефонными ассистентами. В этом режиме распознавание речи на английском языке стало на 19% более точным по сравнению с движком предыдущего поколения, а для других языков качество распознавания выросло вплоть до 57%. Более того, модель может распознавать слова, которые не использовались при обучении, автоматически форматировать числа и даты, заменять нецензурную речь и удалять конфиденциальные данные из расшифровки.
Помимо телефонных ассистентов, средство IBM может использоваться для автоматической обработки звонков клиентов, а именно выявления закономерностей или статистического анализа причин звонков, и расшифровки разговора в реальном времени, что позволит оператору быстрее предложить релевантную информацию. Сервис Watson Speech to Text доступен в IBM Cloud.