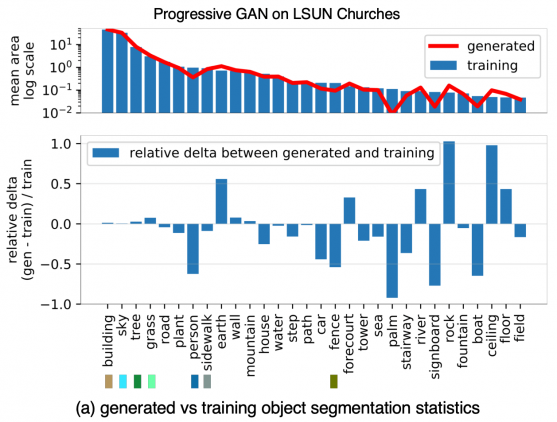
Исследователи из MIT CSAIL изучили, какие объекты генеративным нейросетям сложнее синтезировать. На примере датасета LSUN churches такие классы объектов, как люди, машины и ворота, игнорируются генератором нейросети.
Несмотря на успех генеративно-состязательных нейросетей (GAN), сбой генератора (mode collapse) остается одной из проблем обучения GAN. Генератор в GAN отвечает за синтез изображений. Сбой генератора результирует в ограниченность генерируемых моделью объектов. В своей работе исследователи визуализируют сбой генератора на уровне распределения и на уровне отдельных объектов.
Сначала для сгенерированных изображений исследователи семантически сегментируют объекты. Это необходимо, чтобы сравнить распределения сегментированных объектов на сгенерированным и целевых изображениях. Разница в статистике показывает классы объектов, которые GAN генерировать сложнее. Затем распознанные классы объектов, которые GAN не генерирует, визуализируются напрямую. Исследователи сравнивают отдельные фотографии и распознанные объекты на целевой и сгенерированной фотографиях.
Ниже видно распределение сегментаций объектов в обучающей выборке датасета LSUN churches и в сгенерированных изображениях. Например, такие классы объектов, как люди, машины и ворота, игнорируются генератором.
Методы исследования результатов GAN
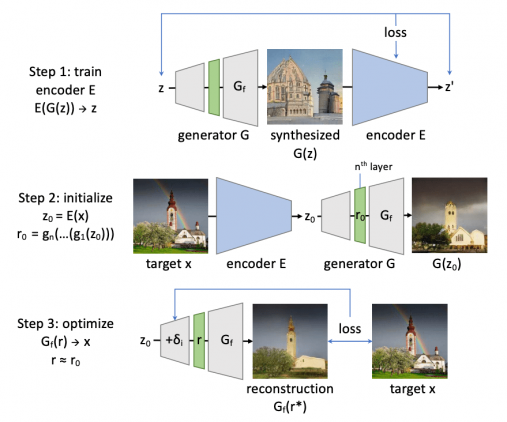
Цель исследования в визуализации семантических концептов, которые GAN не могут генерировать. Исследователи визуализируют результаты GAN двухуровнево: на уровне полного распределения сгенерированных объектов и на уровне отдельных изображений.
Процесс можно поделить на следующие шаги:
- Сначала измеряется Generated Image Segmentation Statistics через сегментирование сгенерированных и целевых изображений и определение типов объектов, которые игнорируются GAN;
- Затем для сравнения отбираются кейсы, где GAN проигнорировала отдельные типы объектов. Сгенерированное изображение сравнивается с целевым из обучающей выборки
Для второго шага находятся реальные изображения из обучающей выборки с игнорируемыми типами объектов. Эти изображения проецируются на наиболее схожие сгенерированные изображения через промежуточный слой генератора. Исследователи называют этот шаг инверсией слоя (Layer Inversion).
В качестве модели для семантической сегментации используется Unified Perceptual Parsing сеть. Нейросеть присваивает каждому пикселю один из 336 классов объектов.