Компания Uber открыла доступ к фреймворку глубокого обучения Ludwig, который позволяет создавать модели без написания кода. Ludwig создан на базе TensorFlow и должен помочь опытным разработчикам быстрее улучшать модели, а также сделать машинное обучение доступным для начинающих специалистов.
Разработчики Uber создавали инструмент в течение последних двух лет, чтобы упростить внедрение глубокого обучения в свои проекты. Ludwig упрощает прототипирование и обработку данных, исследователи могут сосредоточиться на разработке архитектур.
Инструмент содержит готовые модели, которые можно комбинировать, чтобы разрабатывать модели машинного обучения под собственные задачи. Для тренировки модели нужен датасет с массивом данных в формате CSV и файл конфигурации YAML, в котором указано, какие столбцы содержат входные данные, а какие — выходные переменные. Если целевых переменных несколько, Ludwig обработает их паралелльно.
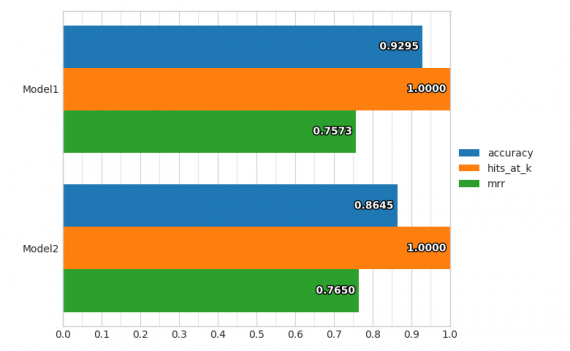
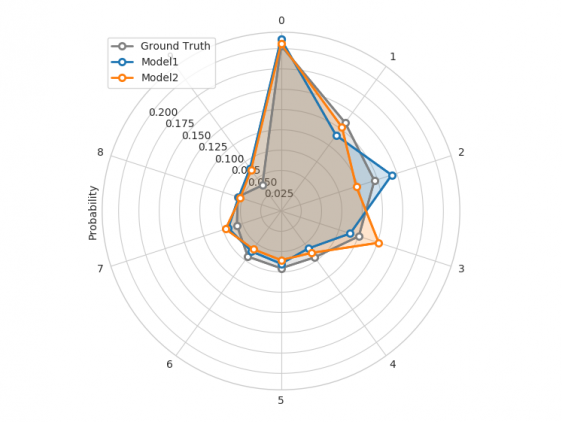
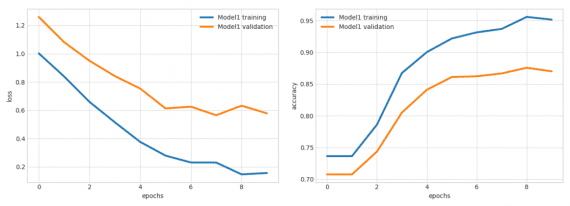
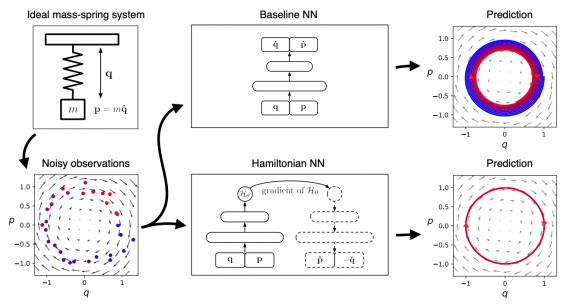
Фреймворк использует энкодеры и декодеры специфичные для каждого типа данных, что позволяет создавать высокомодульную архитектуру: каждый тип поддерживаемых данных (текст, изображения, категории и т. д.) имеет определенную функцию предварительной обработки. Энкодеры отображают необработанные данные в тензоры, а декодеры отображают тензоры в необработанные данные.
«Сопоставляя эти компоненты для конкретных типов данных, пользователи могут создавать модели для решения самых разнообразных задач. Например, комбинируя энкодер текста и декодер классов, пользователь может получить классификатор текста» — написали разработчики в своем блоге. Универсальная и гибкая архитектура энкодер-декодер позволит неопытным специалистам обучать модели для решения задач классификации, регрессии, моделирования, машинного перевода, прогнозирования временных рядов и других.
Ludwig содержит:
- набор утилит командной строки для обучения, тестирования моделей и создания прогнозов;
- инструменты визуализации для оценки моделей;
- Python API, который позволяет пользователям обучить модель или загрузить готовую модель и использовать ее для получения прогнозов по новым данным;
- поддержку распределенного обучения моделей на нескольких GPU с использованием фреймворка Horovod.
Подробнее об инструменте и возможностях читайте в посте.