MuZero — RL-алгоритм, который основан на AlphaZero и позволяет встроить в процесс обучения выученную модель. Разработкой алгоритма занимались исследователи из DeepMind. MuZero выдает state-of-the-art результаты для игры Atari 2600 и обходит людей в таких играх, как шахматы, сеги и го. Алгоритм расширяет AlphaZero на большее количество сред, среди которых среды с одним игроком.
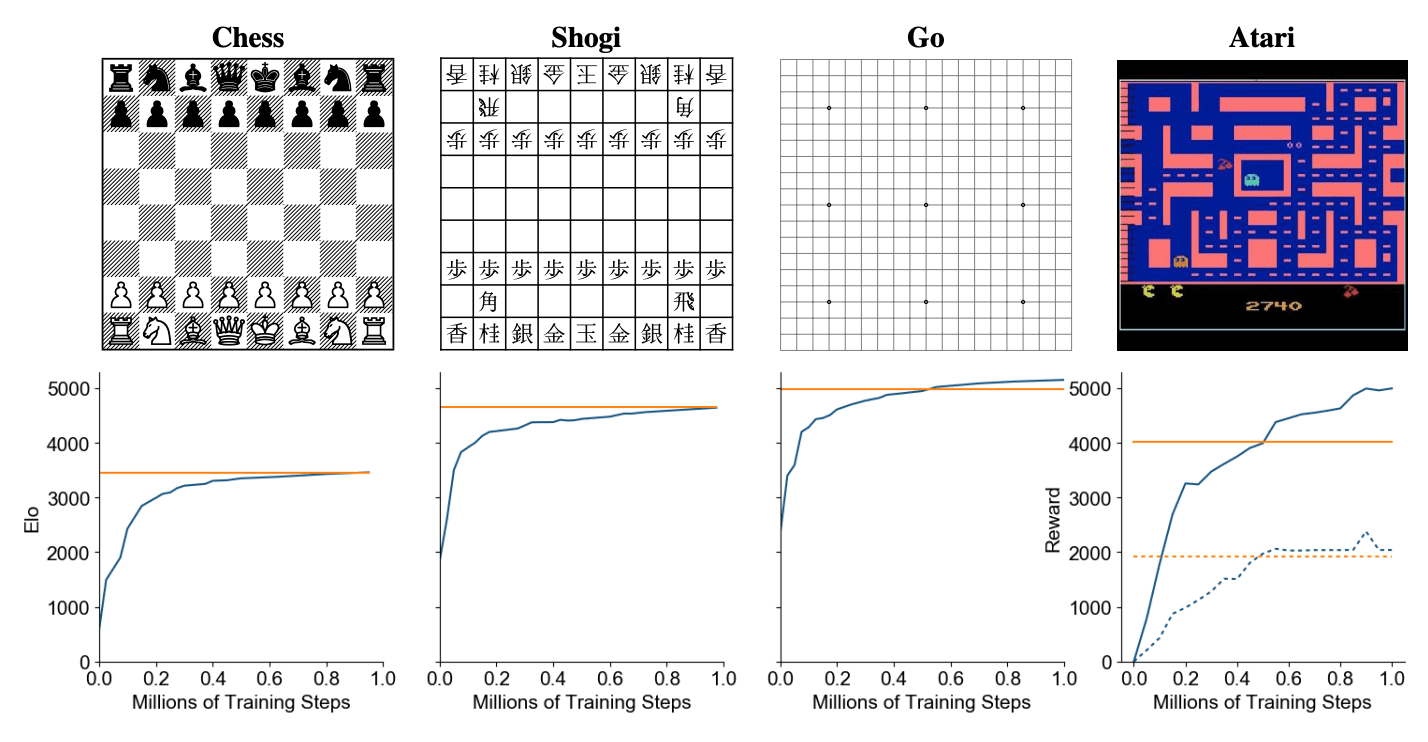
Обучение агентов, которые способны планировать, является одной из наиболее сложных проблем. Методы планирования на деревьях широко распространены в шахматах и го, где есть доступ к идеальному симулятору. Несмотря на это, в задачах из реального мира среда чаще всего динамическая и непредсказумая. Восстановить такой симулятор невозможно. MuZero совмещает в себе методы поиска на деревьях с выученной моделью. При том, что алгоритм обходит людей в планировании в сложных средах, никаких дополнительных знаний о динамике сред алгоритм не имел. MuZero выучивает модель, которая итеративно предсказывает награду, следующее действией и функцию ценности (value function).
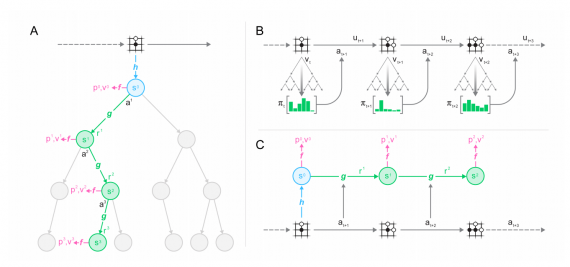
Структура обученной модели
Модель состоит из трех связанных друг с другом компонентов:
- представление;
- динамика;
- предсказание
MuZero
Внутри модель представлена как комбинация 3 функций: функция представления, функция динамики и предсказательная функция. Функция динамики в MuZero отражает структуру MDP модели, которая рассчитывает ожидаемую награду и переход в новое состояние для текущего состояния и действия. Традиционные подходы к model-based RL учитывают состояние семантики среды. В MuZero функция динамики детерминированная.
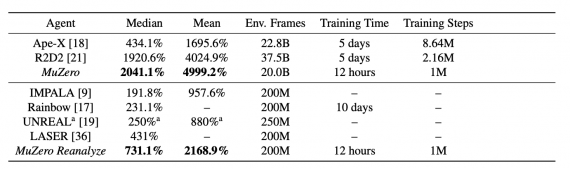
Оценка работы алгоритма
Исследователи сравнили MuZero с предыдущими state-of-the-art агентами для игры в Atari. Отдельно сравнивались агенты, которые тренировались на большом объеме данных и на маленьком. Ниже — средний и медианный скоры моделей в сравнении с людьми. MuZero устанавливает новый state-of-the-art как для обучения на большом количестве данных, так и для обучения на маленьком.