U-GAT-IT — это генеративная нейросеть для синтезации изображений, которая обучается без учителя. Разработчики протестировали ее работу на задаче генерации изображений аниме-персонажей из обычных фотографий людей. Результаты экспериментов показывают, что U-GAT-IT справляется с задачей image-to-image генерации лучше, чем state-of-the-art подходы. Код проекта опубликован и доступен в репозитории на GitHub.
U-GAT-IT включает в себя новый модуль с вниманием и обучающуюся функцию нормализации, что позволяет тренировать модель end-to-end. Модуль внимания учит модель фокусироваться на более важных частях изображения при генерации целевого изображения из входного. Прошлые модели с модулем внимания не были устойчивы к изменениям в формах между целевым изображением и reference изображением. AdaLIN (Adaptive Layer-Instance Normalization) функция помогает модели с вниманием контролировать объем изменений формы и текстуры объектов на входном изображении. В AdaLIN есть обучающиеся параметры, которые отвечают за контроль над объемом изменений.
Что внутри
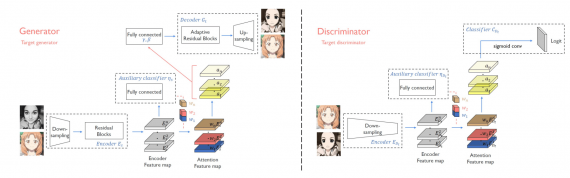
Кодировщик внутри генератора состоит из двух сверточных слоев и четырех residual блоков. Декодировщик генератора состоит из четырех residual блоков и двух сверточных слоев. Для кодировщика используется instance нормализация, а для декодировщика — AdaLIN. Это обусловлено тем, что для задачи классификации нормализация слоя работает хуже, чем батч-нормализация. Для дискриминатора используется спектральная нормализация.
В дискриминаторе реализована PatchGAN, которая классифицирует, являются ли локальная и глобальная часть изображения сгенерированным изображением.
Сравнение работы нейросети с другими подходами
Исследователи сравнили метод с конкурирующими подходами, включая CycleGAN, UNIT, MUNIT и DRIT. Все базовые модели были имплементированы с использованием оригинального кода.
CycleGAN использует состязательную функцию потерь, чтобы выучить сопоставление объектов из пространства X в пространство Y. Это метод регуляризации сопоставления через cycle consistency функции потерь. CycleGAN состоит из двух сверточных блоков, 9 residual блоков, 2 развертывающих блоков и 4 слоев дискриминатора.
UNIT состоит из двух VAE-GAN с общим скрытым пространством. Структура модели схожа с CycleGAN, но отличается структурой дискриминатора.
MUNIT может генерировать различные выходные изображения из одного входного изображения. Модель допускает, что представление изображения может быть разделено на кодирование содержания и кодирование стиля.
DRIT, как и MUNIT, может генерировать несколько выходных изображений из одного входного.
Работа моделей оценивалась с помощью 5 датасетах с изображениями. Среди датасетов selfie2anime — набор реальных фотографий и аниме-изображений. Ниже видно, что для 4-х из 5 задач результаты U-GAT-IT участники опроса выбирали чаще, чем результаты остальных моделей.