
Исследователи из Carnegie Mellon University, Facebook AI Research, Argo AI и University of California разработали нейросетевую модель, которая генерирует 3D модели людей и прилегающих объектов из одного 2D изображения. При этом модель учитывает пространственные отношения между объектами.
Подробнее про модель
PHOSA (Perceiving 3D Human-Object Spatial Arrangements) работает без разметки на уровне сцены или объекта. Модель извлекает множество связей между человеком на изображении и остальными объектами и переводит их в 3D пространство. Исследователи внедрили в процесс обучения модели ограничения, которые позволяют разрешать спорные ситуации во время генерации 3D моделей. Для этого в функционале ошибки модели используется несколько loss terms, которые отвечают за:
- Масштаб: размер объекта;
- Силуэт: оптимизация позы человека;
- Взаимодействие: оптимизация связей человека с остальными объектами на изображении
Предложенный фреймворк использует модели 3D оценки позы человека, модели instance-сегментации и дифференцируемую 3D рендеринг модель.
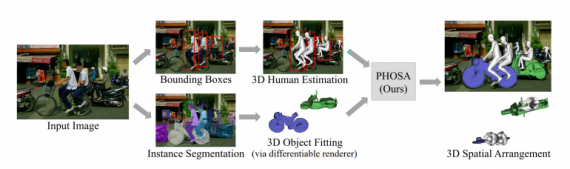
Оценка работы модели
Исследователи оценивали результаты модели качественными и количественными метриками. Тестировали фреймворк на датасете COCO-2017. PHOSA выдает сравнимые с state-of-the-art результаты для изображений, в которых люди соприкасаются с обыденными объектами.
