
Депрессия является серьёзным заболеванием, от которого страдает большое количество людей в мире. Исследователи из Индийского технологического института Патна и Университета Кана в Нормандии представили глубокую нейронную сеть, которая может быть использована для определения депрессии за счёт модальных признаков — выражения лица, положения головы и других внешних проявлений. Исходя из результатов эксперимента можно сказать, что данная модель превосходит существующие на 7% по квадратичной ошибке (RMSE) и на 8% по средней абсолютной ошибке (MAE).
Архитектура
Архитектура модели состоит из трёх основных компонентов:
- Модальные кодеры — принимают на вход модальные данные, такие как голос человека, положение его лица и кодирует их для подсети слияния.
- Подсеть слияния — объединяет все кодеры.
- Подсеть регрессии — выводит оценочный балл PHQ-8.
Датасет DAIC-WOZ
DAIC-WOZ содержит клинические опросы, предназначенные для диагностики тревоги, депрессии и стресса.
Датасет содержал в себе 189 сеансов интервью, где помимо аудиозаписей подробно описаны положения лица, его характеристика и направление взгляда. В обучении использовался набор данных, которые включали в себя запись интервью, двоичные метки PHQ-8, баллы PHQ-8, пол участника и ответы, которые он давал на поставленные вопросы. В тестовом наборе данных использовались только интервью и пол участника.
Эксперимент
Ниже приведена таблица эффективности данной модели и других методов (VFSC, MMD, AW) по трём метрикам: среднеквадратическая ошибка (RMSE), средняя абсолютная ошибка (MAE) и оценка дисперсии (EVS).
- Кодер положения лица MEFL, использует слой LSTM c 256 ячейками памяти.
- Кодер позиции наклона головы MEHP, использует двухслойный LSTM с 6 и 5 ячейками памяти.
- Кодер положения глаз MEEG, использует слой LSTM с 64 ячейками памяти.
- Кодер действий MEAU, использует слой LSTM с 16 ячейками памяти
- Кодер транскрипции METR, использует слой LSTM с 200 ячейками памяти.
- Кодеры голоса и акустической характеристики MECOV и MEFMT, имеют по одному LSTM слою с 37 и 10 ячейками соответственно.
- CombAtt AxV — слияние кодеров MECOV, MEFMT, MEFL, MEHP, MEAU, MEEG.
- CombAtt TxV — слияние кодеров MEFL, MEHP, MEAU, MEEG, METR.
- CombAtt AxTxV — слияние всех кодеров.
- CombAtt attentionless — слияние всех кодеров, но с использованием 300 скрытых слоёв ReLU.
Результаты тестирования:
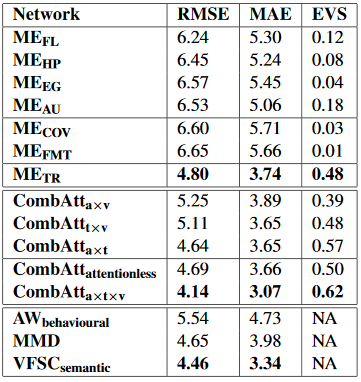
По результатам можно сделать вывод, что алгоритм со всеми модулями даёт лучшие результаты.



