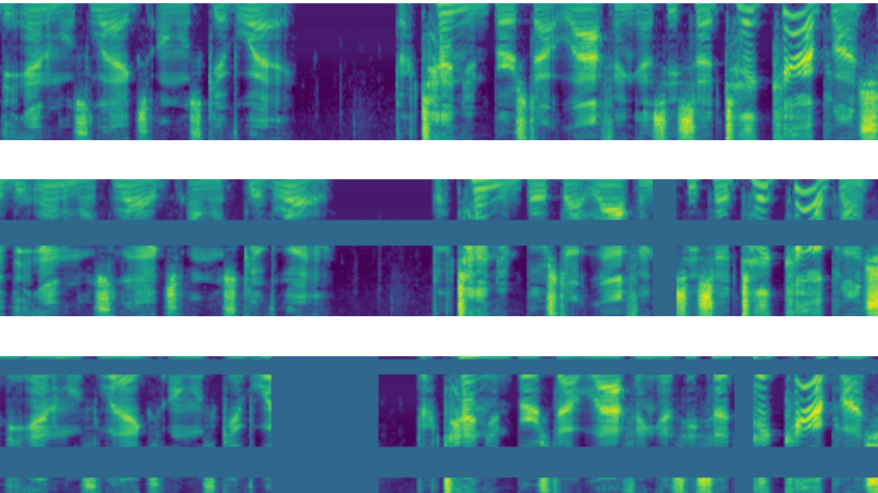
SpecAugment: алгоритм аугментации аудиоданных от Google AI

Просмотров: 5720
Подписаться
0 Comments
Старые