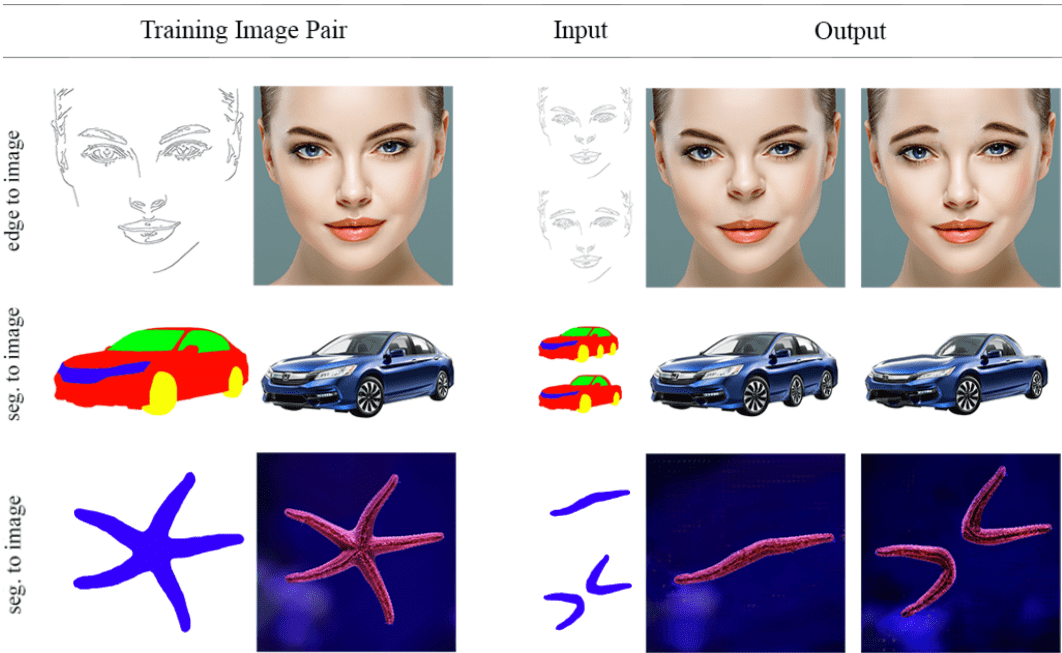
Исследователи из Hebrew University of Jerusalem обучили нейросеть, которая редактирует содержание изображение. Модель принимает на вход оригинальное изображение и карту сегментации отредактированного изображения. На выходе нейросеть выдает отредактированное в соответствии с картой сегментации оригинальное изображение. По результатам экспериментов, предложенная модель обходит pix2pixHD в фотореалистичности генерируемых изображений.
Описание проблемы
Задача изменения содержания на фотографии в последние годы решалась с помощью нейросетевых подходов. Основное ограничение таких подходов — необходимость большого количества размеченных данных для обучения. При этом данные для обучения должны иметь то же распределение, что и целевые данные на инференсе. Однако это невозможно для большинства приложений модели. Исследователи предлагают обучать условный состязательный генератор на одном целевом изображении. Они показывают, что этого достаточно для того, чтобы модель научилась совершать сложные манипуляции над изображением. Ключевым отличием подхода является новый метод аугментации входного изображения. Нейросеть учится соотносить представление изображения с самим изображением. На этапе редактирования генератор позволяет изменять содержание изображения с помощью изменения представления изображения.
Что внутри модели
Подход повторяет архитектуру условной генеративно-состязательной сети (cGAN). В частности исследователи взяли за образец архитектуру pix2pixHD. Нейросеть учится соотносить базовое представление изображения (границы и сегментацию) с изображением. У подхода есть несколько целей:
- Обучение на одном изображении;
- Реалистичность: сгенерированное изображение должно отражать базовое представление изображения;
- Консистентность: сгенерированное изображение должно выглядеть так, что бы было из того же распределения, что и тренировочное изображени
Исследователи предлагают новый метод аугментации данных, который позволяет cGAN фокусироваться на перечисленных целях.
Оценка работы модели
Исследователи сравнивают предложенную модель с pix2pixHD. Качественные и количественные сравнения показывают, что предложенная модель генерирует более реалистично редактирует входное изображение. В качестве количественных метрик исследователи использовали LPIPS и SIFID.




