
Исследователи из Оксфорда представили нейросеть, которая по одному размеченному изображению распространяет разметку на всю видеозапись. На вход нейросети поступает размеченное изображение (часть видеозаписи), цель нейросети сохранить информацию о распознанных объектах на изображении. Этот подход можно использовать и для определения позы человека на видео. Нейросеть обходит state-of-the-art решения в сегментации видео среди self-supervised моделей.

Структура нейросети
Исследователи обучают нейросеть с помощью CNN на датасете Kinetics. Экстракция признаков из изображения производится с помощью вариации ResNet-18.

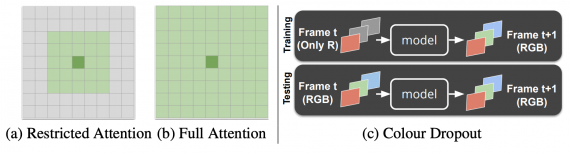
Основной вклад исследователей делится на два пункта. Colour Dropout — подход, при котором из изображений во время обучения фильтруются по одному цветовые каналы. Это позволяет модели не реагировать на изменения распределения цветов на изображении и делает ее более устойчивой. Второй пункт — метод семплирования фреймов изображений для обучения. Исследователи обучали нейросеть на более длительных кусках видеозаписей и предложили scheduled sampling. Scheduled sampling подразумевает, что текущий фрейм не имеет доступ к реальным данным прошлых фреймов, вместо этого модель сохраняет информацию о прошлых предсказаниях.
Чтобы сократить объем памяти и ресурсов на обучение нейросети, исследователи использовали ограниченный механизм внимания (Restricted Attention).
Оценка работы нейросети
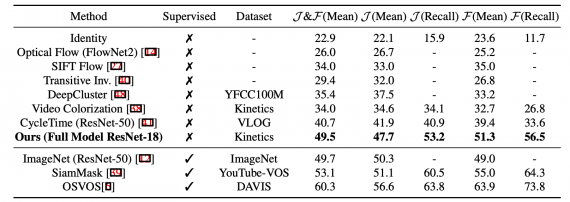
Для сравнения работы модели и state-of-the-art решений исследователи обучили self-supervised модели на датасете Kinetics и тестировали на DAVIS-2017. Среди self-supervised моделей предложенный подход превосходит конкурирующие архитектуры. Однако работает хуже, чем модели с учителем.
Ограничения модели
Среди ограничений модели исследователи выделили три:
- Модель плохо справляется с случаями, когда объекты в видео часть видео были заслонены;
- Когда объекты на видеозаписи выходят на какое-то время за рамки камеры;
- Сложные трансформации объектов на видеозаписи модель не улавливает









