
Исследователи из компании Xiaomi представили end-to-end генератор звука RawNet. Он использует сеть кодера для извлечения характеристик звука и сеть голосовых сигналов (voder) для генерации речи. Эксперименты по задачам Copy-Synthesis показывают, что RawNet достигает качества LPCNet, но при этом имеет более простую архитектуру и быстрее генерирует речь.
Архитектура
Архитектура сети включает в себя сеть кодера, которая извлекает акустические характеристики из необработанного звука, и сеть голосовых сигналов, которая генерирует звук иходя из акустических характеристик.
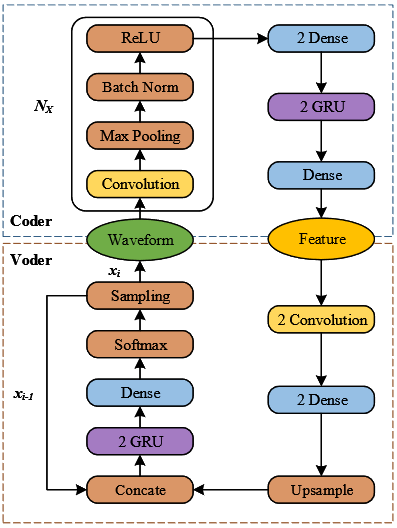
Сеть кодера состоит из стака (Max Pooling, Batch Norm, ReLU) свёрточных слоёв, плотных (dense) слоёв и слоёв GRU. Благодаря стэку свёрточных слоёв сеть изучает представления высокого уровня через фильтры нижнего уровня. Расширение сети с помощью GRU и плотного слоя позволяет фиксировать долгосрочные связи (long-term relationship).
Сеть голосовых сигналов имеет структуру аналогичную LPCNet, но с некоторыми изменениями. LPCNet в качестве входных данных принимает текущую прогнозируемую выборку, прогнозируемое возбуждение, глобальные характеристики частоты кадров из сети и линейное прогнозирование текущей выборки. RawNet принимает текущий прогнозируемый образец и акустические характеристики, которые объединяются для передачи в следующие слои.
Эксперименты
Для обучения модели было использовано несколько наборов данных:
- CMU ARCTIC — содержал 1150 высказываний женщин и мужчин.
- Mufei — содержал 20 часовой аудиофайл высказываний женщины.
- LJ-Speech 1.1 — содержал 24 часовой аудиофайл высказываний женщины.
При обучении сети кодера на вход поступали короткие аудиоклипы по 3 200 образцов. На выход выводилось 20 кадров с размером 64. Обучение проходило на 4-х видеокартах NVIDIA P40 с объемом памяти 22 ГБ каждая.
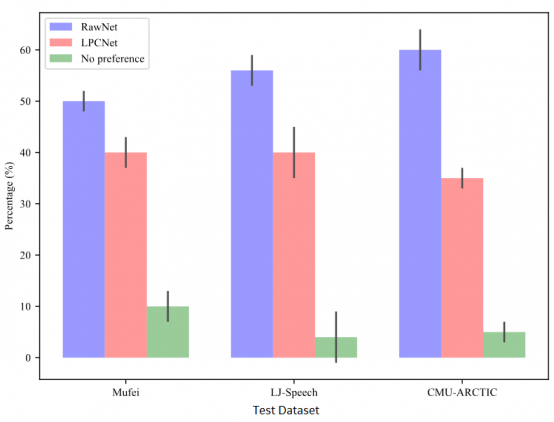
В тесте на качество генерируемой речи участвовало 20 человек, RawNet оказался предпочтительнее LPCNet.






