Трансформеры являются state-of-the-art архитектурой для решения задач обработки естественного языка. Reformer — это модификация для стандартного трансформера, которая позволяет расходовать меньше памяти и быстрее обрабатывает данные при обучении. В стандартном трансформере в контекстном окне учитывается до нескольких тысяч токенов. В свою очередь, Reformer способен обрабатывать контекстные окна размером до миллиона токенов.
Описание проблемы
Анализ последовательных данных, как язык, музыка или видео, — это комплексная задача, которая требует учет контекста для текущего элемента. Например, объект может пропасть из кадра и появиться в кадре через длительный промежуток времени. Большинство моделей неспособны учитывать длительный контекст. В сфере обработки естественного языка LSTM покрывают достаточно контекста, чтобы переводить по одному предложению в входном тексте. В этом случае контекстное окно включает в себя от десятков до сотен слов. Контекстным окном (context window) называется промежуток в входной последовательности, который модель берет во внимание при решении задачи. В приведенном примере задачей является машинный перевод. Более поздняя архитектура трансформера позволяет учитывать уже несколько тысяч слов в контекстном окне. Это способствует повышению качества сгенерированных предложений. Помимо NLP задач, трансформеры нашли применение в компьютерном зрении и обработке звуков.
У увеличения контекстного окна в трансформере имеет ограничения:
- Необходимость обработать все возможные пары токенов в блоке с механизмом внимания;
- Популярной практикой является хранить выход каждого слоя модели локально. В случае с широкими контекстными окнами такой подход упирается в ограничения памяти
Reformer обходит оба ограничения с помощью механизма хэширования токенов в контекстном окне и reversible residual слои для более эффективного расходования памяти.
Механизм внимания в Reformer
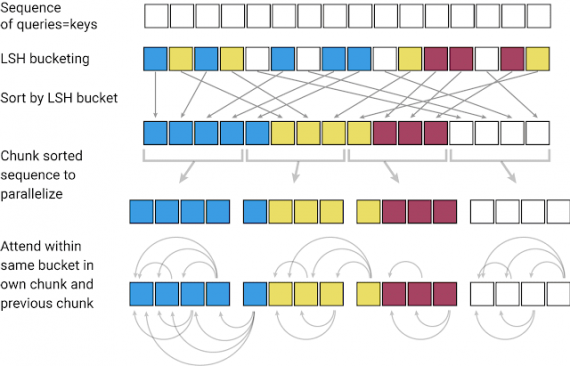
Чтобы обрабатывать в механизме внимания более длительные последовательности, в модели используют locality-sensitive-hashing (LSH). LSH используется для хэширования токенов в контекстном окне. Модель принимает на вход последовательность ключей, где каждый ключ — это вектор слова в первом слое и вектор большего контекста в последующих слоях. LSH применяется к последовательности, после чего ключи сортируются по хэшу и делятся на части. Внимание применяется только к одному чанку ключей одновременно и к его непосредственным соседям.
Оптимизированное расходование памяти
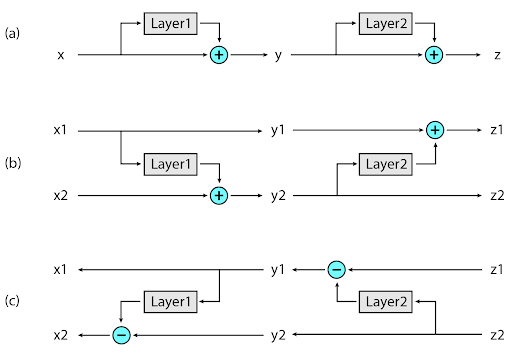
Чтобы избавиться от проблемы с неоптимальным расходованием памяти, исследователи разработали reversible residual слои. Использование таких слоев позволяет пересчитывать входные данные для каждого слоя во время backpropagation, вместо того, что бы хранить их в памяти.