Google представила SoundStream — аудиокодек на базе искусственного интеллекта, который может использоваться в режиме реального времени на смартфонах. В отличие от Lyra, предыдущего нейрокодека Google, SoundStream работает с аудио более высокого качества и поддерживает кодирование большего количества типов звуков, включая отчетливую речь, речь на фоне шумов и музыку.
Задача аудиокодека — эффективно сжать звук, чтобы он занимал меньше места и требовал меньшей пропускной способности сети. Лучшими из разработанных в последние несколько лет кодеками являются Opus (используется в Google Meet и Youtube) и EVS (используется в мобильной связи). Хотя эти кодеки обладают высокой эффективностью сжатия, в последнее время наблюдается интерес к использованию подходов машинного обучения для кодирования аудио.
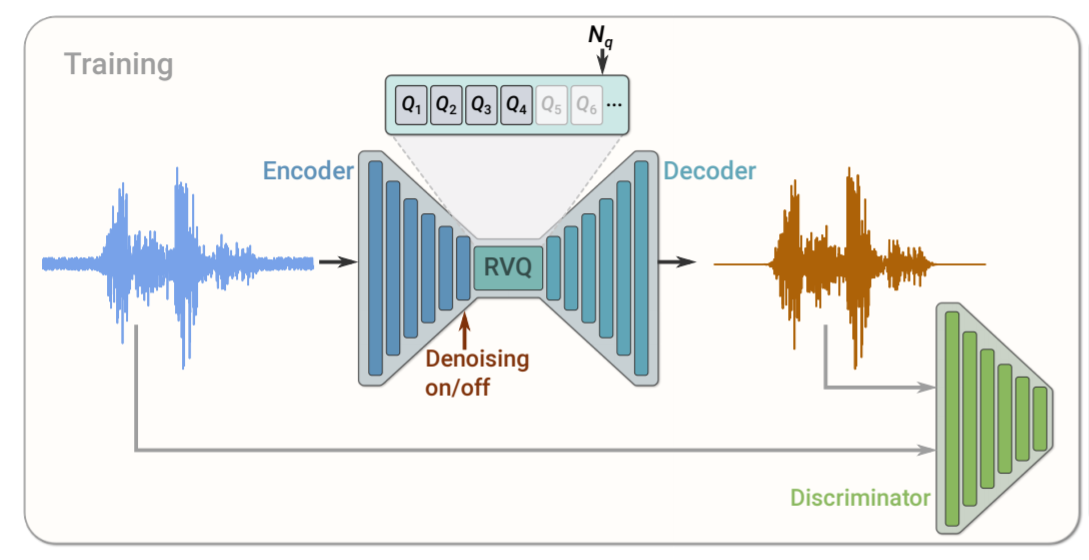
SoundStream — это расширенная версия Lyra, нейронного аудиокодека Google для речи с низким битрейтом. SoundStream состоит из нейросети, включающей энкодер, декодер и векторное квантование. Энкодер преобразует аудио в кодированный сигнал, который сжимается с помощью квантования и преобразуется обратно в аудио с помощью декодера. Дискриминатор, который вычисляет комбинацию функций потерь, максимально приближает восстановленный звук к исходному несжатому аудио. После обучения энкодер и декодер могут быть запущены по отдельности для эффективной передачи звука по сети.
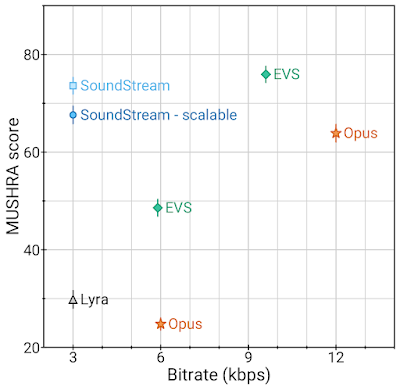
SoundStream является первым нейронным кодеком, способным работать в режиме реального времени на смартфоне. При битрейте 3 Кбит/с качество звука после SoundStream превосходит качество звука после Opus с битрейтом 12 Кбит/с и схож с качеством звука после EVS с битрейтом 9,6 Кбит/с. Таким образом, кодирование может обеспечить аналогичное качество звука при значительно меньшей (в 3-4 раза) пропускной способности.