Рекомендательные системы, основанные на машинном обучении, получили широкое распространение для бизнеса в последние годы. В этой статье приведено описание принципов работы основных методов для реализации рекомендательных систем и метрик для оценки их работы.
Перевод статьи Recommendation Systems — Models and Evaluation, автор — Neerja Doshi, ссылка на оригинал — в подвале статьи.
Я принимал участие в создании нескольких различных типов рекомендательных систем, и я заметил одну вещь: каждый вариант использования отличается от других, поскольку каждый из них направлен на решение своей бизнес-задачи. Давайте рассмотрим несколько примеров:
- Рекомендации по фильмам / книгам / новостям — Предложение нового контента, повышающего заинтересованность пользователей. Цель состоит в том, чтобы познакомить пользователей с новым контентом, который может заинтересовать их, и побудить их потреблять больше контента на нашей платформе.
- Рекомендации по акциям — Предложение акций, которые являются наиболее прибыльными для клиентов. Рекомендации могут быть акциями, которыми они пользовались в прошлом. Новизна здесь не имеет значения, только рентабельность акций.
- Рекомендации по продукту — Предложение сочетания старых и новых продуктов. Старые продукты, известные с прошлых транзакций пользователей, служат напоминанием об их частых покупках. Также важно предложить новые продукты, которые пользователи могут захотеть попробовать.
Все эти задачи схожи тем, что они направлены на повышение удовлетворенности клиентов и, в свою очередь, стимулируют бизнес увеличением комиссий, увеличением продаж и т.д. Независимо от варианта использования, данные обычно имеют следующий формат:
- Идентификатор клиента, идентификатор продукта (фильм / акция / продукт), №: единиц / рейтинг, дата транзакции.
- Любые другие признаки, такие как подробности о продукте или данные о клиенте.
Далее обсудим следующие темы:
- Методы, используемые для построения рекомендательных систем — контент-ориентированные, коллаборативная фильтрация, кластеризация
- Метрики оценки — Статистические метрики, Метрики поддержки принятых решений
- Что нужно иметь в виду

Методы создания рекомендательной системы
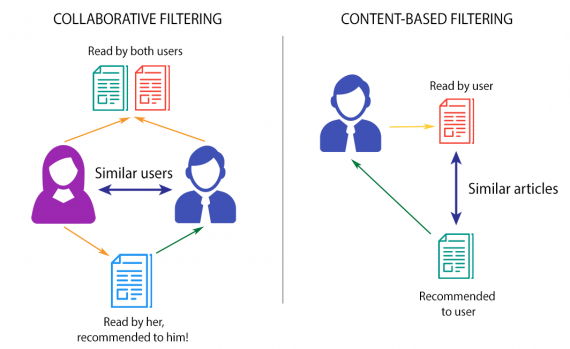
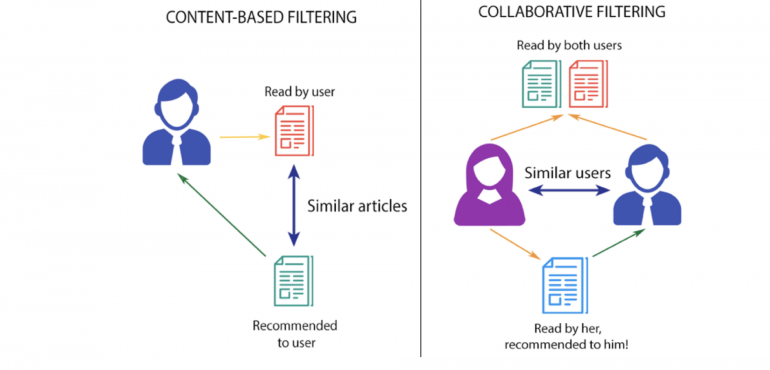
Существует два основных подхода к созданию рекомендательных систем — контент-ориентированная и коллаборативная фильтрация. В следующем разделе я расскажу о каждом из них и когда они подходят.
Контент-ориентированные
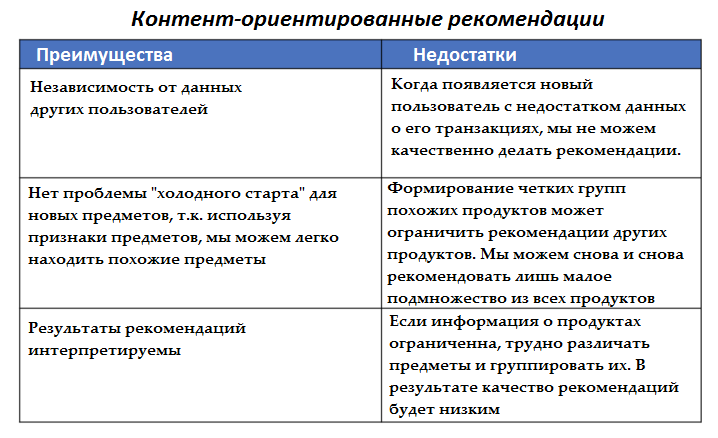
Суть этого подхода заключается в том, что мы сопоставляем пользователей с тем контентом или товарами, которые им нравились или были ими куплены. Здесь важны атрибуты пользователей и продуктов. Например, для рекомендаций к фильмам мы используем такие признаки, как режиссер, актеры, продолжительность фильма, жанр и т.д., чтобы найти сходство между фильмами. Кроме того, мы можем извлечь такие характеристики, как оценка настроений и оценки TF-IDF из описаний фильмов и обзоров. (Оценка TF-IDF отражает, насколько важно слово для документа в наборе документов). Цель контент-ориентированных методов — создать «профиль» для каждого пользователя и каждого предмета.
Рассмотрим пример рекомендации новостных статей пользователям. Допустим, у нас есть 100 статей и словарь размера N. Сначала мы вычисляем оценку TF-IDF для каждого слова в каждой статье. Затем мы строим 2 вектора:
- Вектор предмета: это вектор длины N. Он содержит значения 1 для слов, которые имеют высокую оценку TF-IDF в этой статье, в противном случае значение 0.

Пример двух векторов предмета (item vectors) - Вектор пользователя: снова вектор размерностью 1xN. Для каждого слова мы храним вероятность появления слова в статьях, которые употребил пользователь. Обратите внимание, что вектор пользователя основан на атрибутах элемента (в данном случае это оценка слов TF-IDF).

Построив эти «профили», мы вычисляем сходства между пользователями и предметами. Предметы должны быть рекомендованы пользователю, если: 1) они имеют наибольшее сходство с пользователем или 2) имеют большое сходство с другими элементами, прочитанными пользователем. Есть несколько способов сделать это. Давайте посмотрим на 2 распространенных метода:
- Косинусное сходство:
Чтобы рекомендовать предметы, которые наиболее похожи на те, которыми интересовался пользователь, мы вычисляем косинусное сходство между статьями, которые пользователь прочитал, и другими статьями. Наиболее схожие будут рекомендованы. Таким образом, это подобие предмет-предмет.
Косинусное сходство Косинусное сходство лучше всего подходит, когда ваши признаки высокоразмерны, особенно в области поиска информации и анализа текста.
Чтобы вычислить сходство между пользователем и предметом, мы просто берем косинусное сходство между вектором пользователя и вектором предмета. - Сходство Жаккара
Также известное как пересечение над объединением, формула выглядит следующим образом:
Сходство Жакара (пересечение над объединением) Используется для подобия предмет-предмет. Мы сравниваем векторы элементов друг с другом и возвращаем наиболее похожие предметы.
Сходство Жакара полезно только тогда, когда векторы содержат бинарные значения. Если у них есть ранжирование или рейтинги, которые могут принимать более двух возможных значений, сходство Жаккара не применимо.
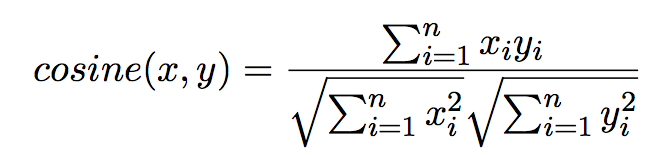
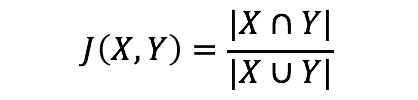
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics import jaccard_similarity_score
sim_cosine = []
sim_jaccard = []
# x = user or item vector
# articles = vectors correcponding to every article
for a in articles:
sim_cosine.append(list(cosine_similarity(x,a).reshape(1,))[0])
sim_jaccard.append(list(jaccard_similarity_score(x,a).reshape(1,))[0]) # only if all the vectors have binary values
np.argsort(sim_cosine)[::-1] # reverse indices according to similarity
np.argsort(sim_jaccard)[::-1] # reverse indices according to similarity
В дополнение к контент-ориентированным методам мы можем рассматривать рекомендацию как простую задачу машинного обучения. Здесь пригодятся обычные алгоритмы машинного обучения, такие как случайный лес, XGBoost и т.д.
Эти методы полезны, когда у нас есть множество «внешних» признаков, таких как погодные условия, рыночные факторы и т.д., которые не являются собственностью пользователя или продукта и могут сильно варьироваться. Например, цена открытия и закрытия предыдущего дня играет важную роль в определении прибыльности инвестирования в конкретную акцию. Это относится к классу supervised примеров задач, когда имеются метки, которые могут обозначать, понравился ли пользователю продукт, кликнул ли он на него (0/1), или рейтинг, который пользователь указал этому продукту, или количество единиц, купленных пользователем.
Коллаборативная фильтрация
Основополагающее предположение подхода коллаборативной фильтрации заключается в том, что если А и В покупают аналогичные продукты, А, скорее всего, купит продукт, который купил В, чем продукт, который купил случайный человек. В отличие от контентно-ориентированного подхода, здесь нет признаков, соответствующих пользователям или предметам. Все, что у нас есть — это Матрица полезности. Вот как это выглядит:
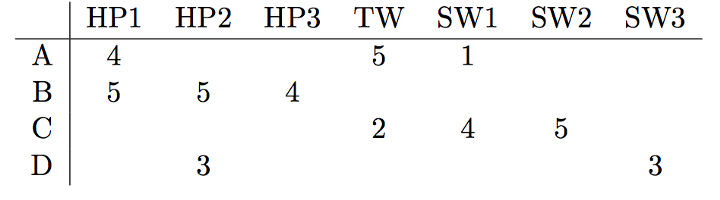
A, B, C, D — пользователи, а столбцы представляют фильмы. Значения представляют оценки (1–5), которые пользователи дали фильму. В других случаях эти значения могли бы быть 0/1 в зависимости от того, смотрел ли пользователь фильм или нет. Существует две широких категории, на которые можно разделить коллаборативную фильтрацию:
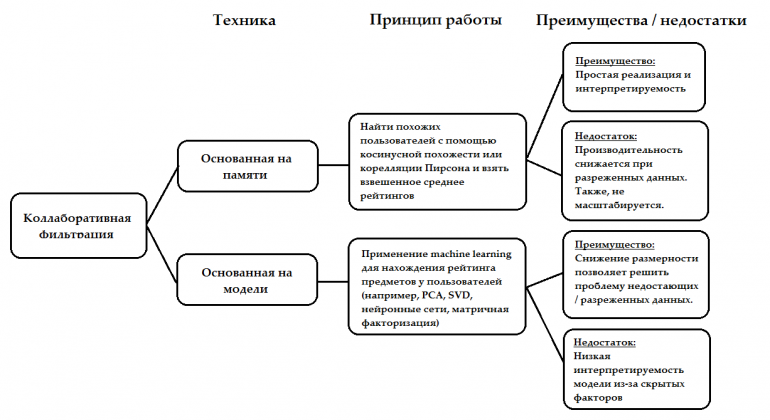
Подход на основе памяти
Для этого подхода запоминается матрица полезности, и рекомендации составляются путем запроса данного пользователя к остальной части матрицы полезности. Давайте рассмотрим тот же пример: у нас есть фильмы т и пользователи U, и мы хотим узнать, насколько пользователь i любит кино k.
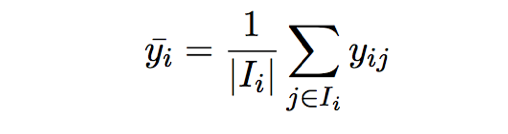
Это средний рейтинг, который сформирован для пользователя i на основе всех фильмов, которые он/она когда-либо оценивал. Используя это, мы оцениваем рейтинг фильма k для пользователи i следующим образом:

Сходство между пользователями a и i можно вычислить с использованием любых методов, таких как косинусное сходство / сходство Жаккара / коэффициент корреляции Пирсона и т.д.
Эти результаты очень легко получать и интерпретировать, но как только данные становятся слишком разреженными, производительность ухудшается.
Подход на основе модели
Одной из наиболее распространенных реализаций подхода на основе модели является матричная факторизация. В этом случае мы создаем представления пользователей и предметов из матрицы полезности. Вот как это выглядит:

Таким образом, наша матрица полезности разлагается на U и V, где U представляет пользователей, а V представляет фильмы в низкоразмерном пространстве. Это может быть достигнуто с помощью методов разложения матриц, таких как SVD или PCA, или обучение двух векторных представлений (embeddings) с использованием нейронных сетей с помощью некоторого оптимизатора, такого как Adam, SGD и т.д.
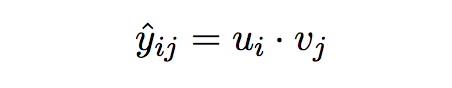
Для пользователя i и каждого фильма j нам просто нужно вычислить рейтинг y и рекомендовать фильмы с самым высоким прогнозируемым рейтингом. Этот подход наиболее полезен, когда у нас есть тонна данных, и они имеют высокую разреженность. Матричная факторизация помогает путем понижения размерности, что ускоряет вычисления. Одним из недостатков этого метода является то, что снижаться интерпретируемость, поскольку мы не знаем, что именно означают элементы векторов пользователей/предметы.
Кластеризация
Кластеризация обычно используется, когда задача рекомендательной системы становится задачей без учителя.
Если вы только начинаете заниматься бизнесом и у вас очень мало исторических/размеченных данных, вы можете кластеризовать наблюдения на основе набора признаков, а затем назначить рекомендации для кластеров на основе меток, которые имеются у объектов в этом кластере.
Это решение, конечно, не дает лучших результатов сразу, но является хорошей отправной точкой для таких случаев, пока не будет получено достаточно данных. Кластеризация также может быть использована для создания мета-признаков для объектов. Например, после кластеризации можно назначить значения от 1-k в качестве нового элемента «кластер» для каждого наблюдения, а затем обучить основную модель всем функциям. Это может быть сделано на уровне пользователя или продукта.
Оценивающие метрики
Основное препятствие при разработке систем рекомендаций — выбор метрик для оптимизации. Это может быть сложно, потому что во многих случаях цель — НЕ рекомендовать все те же продукты, которые пользователь купил ранее. Так как же узнать, хорошо ли работает ваша модель, предлагая продукты?
Статистические метрики
Они используются для оценки точности метода фильтрации путем сравнения прогнозируемых рейтингов непосредственно с фактическим рейтингом пользователей. Средняя абсолютная ошибка (MAE), среднеквадратическая ошибка (RMSE) и корреляция обычно используются в качестве статистических метрик. MAE является наиболее популярным и широко используемым — это мера отклонения рекомендации от фактической стоимости пользователя. MAE и RMSE рассчитываются следующим образом:
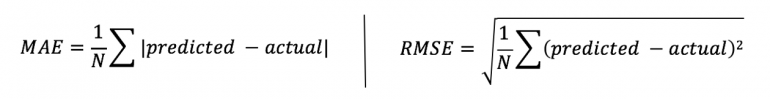 Чем ниже значения MAE и RMSE, тем точнее механизм рекомендаций прогнозирует пользовательские рейтинги. Эти метрики удобны, когда рекомендации основаны на прогнозировании рейтинга или количества транзакций. Они дают нам представление о том, насколько точны наши прогнозы и, в свою очередь, насколько точны наши рекомендации.
Чем ниже значения MAE и RMSE, тем точнее механизм рекомендаций прогнозирует пользовательские рейтинги. Эти метрики удобны, когда рекомендации основаны на прогнозировании рейтинга или количества транзакций. Они дают нам представление о том, насколько точны наши прогнозы и, в свою очередь, насколько точны наши рекомендации.
Метрики поддержки принятых решений
Популярными среди них являются Precision (точность) и Recall (полнота). Они помогают пользователям выбирать продукты, которые более похожи среди доступного набора продуктов. Метрики рассматривают процедуру прогнозирования как бинарную операцию, которая отличает хорошие элементы от тех, которые не являются хорошими. Давайте посмотрим на них более подробно:
Precision@k и Recall@k
Давайте начнем с понимания того, что означает точность и полнота для систем рекомендаций:
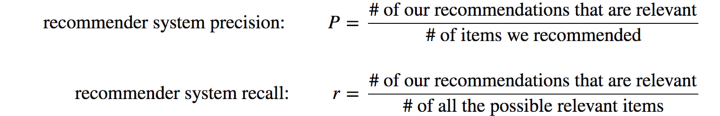
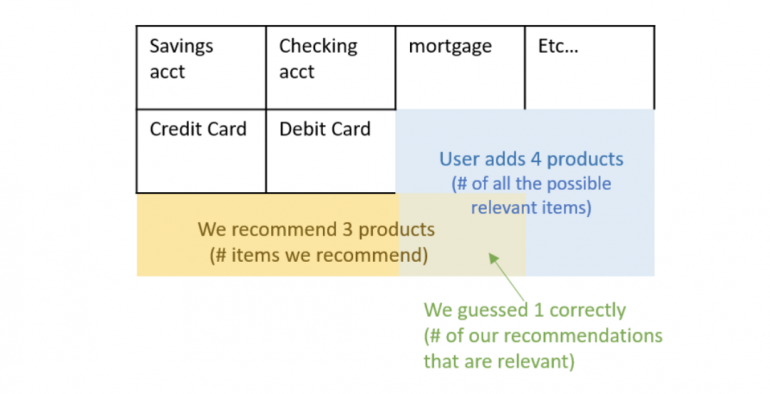
Но precision и recall не заботятся о порядке. Поэтому вместо этого мы используем точность и recall при отсечении k. Предположим, что мы даем N рекомендаций и рассматриваем только первый элемент, затем только первые два, затем только первые три и т. Д. … эти подмножества могут быть проиндексированы с помощью k.
Precision и recall в точке отсечения k, P@k и r@k — это просто precision и recall, рассчитанные с учетом только подмножества ваших рекомендаций от ранга 1 до k. Оценка рекомендаций определяется прогнозируемой ценностью. Например, продукт с самым высоким прогнозируемым значением ранжируется 1, продукт с k-м самым высоким прогнозируемым значением ранжируется k.

Средняя точность (Average Precision, AR)
Если мы должны порекомендовать N элементов и при этом в полном пространстве элементов m соответствующих элементов, средняя точность AP@N определяется как:

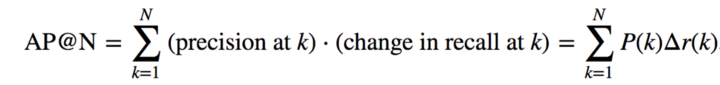
где rel (k) — это просто индикатор (0/1), который сообщает нам, был ли релевантен этот k-й элемент, а P (k) — точность @k. Если бы мы рекомендовали 2N элементов вместо N, метрика AP@N говорит, что мы думаем только о средней точности до N-го элемента.
AP вознаграждает вас за предоставление правильных рекомендаций,
AP вознаграждает вас за предварительную загрузку рекомендаций, которые, скорее всего, будут правильными,
AP никогда не накажет вас за добавление дополнительных рекомендаций в ваш список — просто убедитесь, что вы загружаете лучшие из них.
Средний precision по каждому классу (Mean Average Precision, MAP)
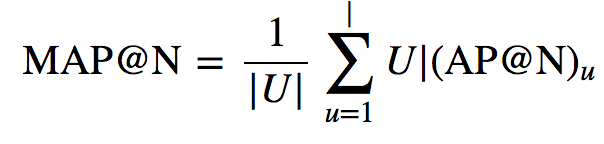
AP применяется к отдельным объектам выборки, например к отдельным пользователям. MAP@N просто делает шаг вперед и усредняет AP для всех пользователей.
Дополнительные предложения
Одно из предложений (это личное, в котором я не слишком уверен) заключается в поиске контента с истинной информацией, которая была получена не из исторических данных пользователей. Затем этот контент сравнивается с неисторическим содержанием в рекомендациях с использованием любой из стандартных метрик, описанных выше. Это дает нам представление о том, насколько хороша наша модель в рекомендации продуктов, которые напрямую не связаны с прошлыми транзакциями.
Что нужно иметь в виду
При разработке системы рекомендаций, особенно для рекомендаций, основанных на содержании, важно помнить, что нужно оптимизировать НЕ только одну метрику. То есть для рекомендации новостной статьи не рекомендуется отдавать статью с очень высоким значением привлекательности, потому что это означает, что мы рекомендуем пользователям контент, который они, скорее всего, потребляли бы и без нашей рекомендации.
Так мы в любом случае не улучшим бизнес. Мы должны обеспечить достойный precision/recall как показатель того, что наша модель способна изучать предпочтения пользователя, но нет цели пытаться максимально улучшить их. Кроме того, мы не хотим терять вовлечение пользователей в долгосрочной перспективе, рекомендуя одни и те же типы продуктов снова и снова. А это весьма вероятно, если мы попытаемся максимизировать precision@k/recall@k.
Спасибо за чтение!