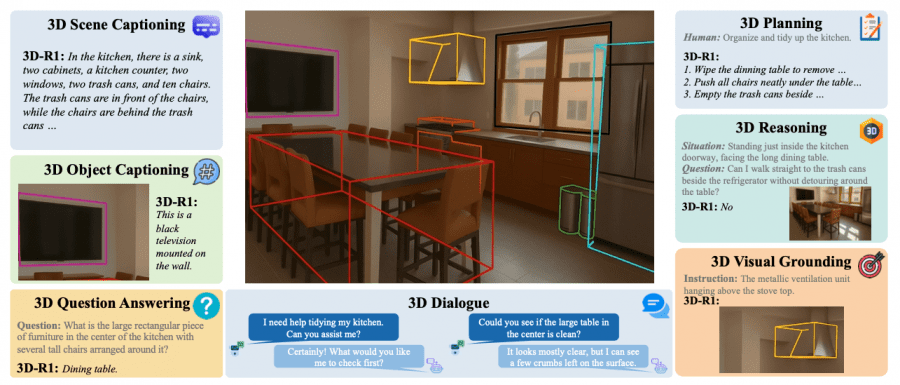
Исследователи из Шанхайского университета инженерных наук и Пекинского университета представили 3D-R1 — новую foundation-модель, которая значительно улучшает способности к рассуждению в трёхмерных vision-language моделях (VLM). Модель демонстрирует среднее улучшение производительности на 10% в различных 3D-бенчмарках, что подтверждает её эффективность в понимании и анализе трёхмерных сцен. Код модели доступен на Github, датасет выложен на HuggingFace.
Архитектура и подход
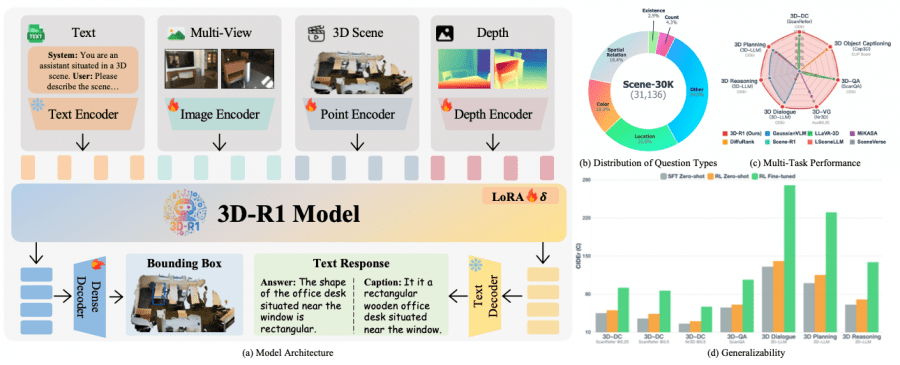
3D-R1 использует двухэтапный подход к обучению. На первом этапе создаётся высококачественный синтетический датасет Scene-30K с цепочками рассуждений (Chain-of-Thought), который служит для холодного старта модели. Датасет содержит 30,000 сложных примеров рассуждений, сгенерированных с использованием Gemini 2.5 Pro на основе существующих 3D-VL датасетов.
Ключевой особенностью архитектуры является унифицированное кодирование, которое объединяет:
- Текстовый энкодер для обработки естественного языка;
- Энкодер многоракурсных изображений на базе SigLIP-2 для анализа изображений;
- Энкодер облака точек на основе Point Transformer v3 для работы с 3D-данными;
- Энкодер глубины с использованием Depth-Anything v2 для понимания глубины.
Обучение с подкреплением через GRPO
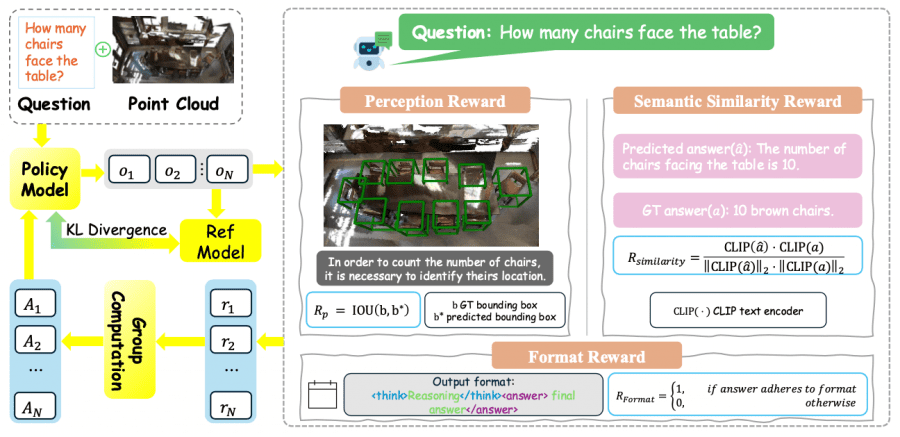
На втором этапе 3D-R1 применяет Group Relative Policy Optimization (GRPO) для улучшения способностей к рассуждению. Модель использует три функции вознаграждения:
Format reward, награда за формат, контролирует структурную корректность выходных данных, проверяя соответствие формату <think>рассуждение</think> <answer>финальный ответ</answer>.
Perception reward, награда за восприятие, фокусируется на точности пространственного восприятия, оценивая пересечение предсказанных и истинных bounding box через метрику IoU.
Semantic similarity reward, награда за семантическое сходство, использует предобученный текстовый энкодер CLIP для оценки семантического соответствия между предсказанным и истинным ответами через косинусное сходство.
Динамический выбор ракурсов
3D-R1 использует инновационную стратегию динамического выбора ракурсов, которая автоматически выбирает наиболее информативные 2D-ракурсы из 3D-сцены. Алгоритм использует три комплементарных оценочных функции:
- Text-to-3D score оценивает релевантность ракурса к текстовому контексту;
- Image-to-3D score анализирует покрытие пространственной информации;
- CLIP score обеспечивает кросс-модальное выравнивание.
Адаптивное взвешивание этих компонентов позволяет модели динамически выбирать оптимальные ракурсы для каждого конкретного сценария.
Результаты экспериментов

Эксперименты на семи ключевых 3D-тестах демонстрируют значительные улучшения. На задаче трёхмерного детального описания 3D-R1 достигает 91.85 CIDEr@0.25 на ScanRefer, превосходя предыдущий лучший результат на 6.43 пункта. В задаче ответов на вопросы модель показывает 106.45 CIDEr на валидационном наборе ScanQA.
Особенно впечатляющими являются результаты на задачах трёхмерной локализации обхектов, где 3D-R1 достигает 68.80 Acc@0.25 на Nr3D и 65.85 Acc@0.25 на ScanRefer. На задачах трёхмерного рассуждения модель демонстрирует 138.67 CIDEr на SQA3D, что значительно превосходит существующие методы.
Синергия отдельных компонентов
Детальный анализ компонентов подтверждает важность каждого элемента модели. Обучение с подкреплением с тремя функциями вознаграждения увеличивает производительность ScanQA CIDEr с 97.95 до 106.45. Динамический выбор ракурсов показывает преимущество над фиксированными стратегиями, улучшая CLIP R@1 с 30.18 до 32.23 на задаче трёхмерного описания объектов.
Инкрементальное добавление модальностей демонстрирует вклад каждого компонента: текст и изображения создают базовую функциональность, энкодер глубины добавляет геометрическое понимание, а энкодер облака точек критически важен для сложных пространственных рассуждений.
Практические применения
3D-R1 поддерживает широкий спектр задач понимания трёхмерных сцен: от базового описания объектов до сложного диалога и планирования действий. Модель способна генерировать детальные описания сцен, отвечать на пространственные вопросы, локализовать объекты по текстовым описаниям и даже планировать последовательности действий для реорганизации пространства.
Модель демонстрирует особенно сильные результаты в задачах, требующих понимания пространственных отношений и многоэтапного рассуждения. Это делает 3D-R1 перспективным решением для применений в области робототехники и дополненной реальности.
Заключение
3D-R1 представляет значительный шаг вперёд в развитии трёхмерных визуально-языковых моделей, объединяя структурированное обучение с цепочками рассуждений, обучение с подкреплением с множественными функциями вознаграждения и адаптивные стратегии восприятия. Комплексный подход к оптимизации архитектуры, данных, алгоритмов и методов вывода открывает новые возможности для создания доступного и эффективного искусственного интеллекта в области понимания трёхмерных сцен.








