
Многие приложения предназначенные для редактирования изображения или пост-продакшена фильмов опираются на естественное матирование изображений, как один из шагов обработки. Задача алгоритма матирования состоит в точной оценке прозрачности объекта переднего плана, находящегося на картинке или видеоряде. Исследователи из Тринити Колледжа из Дублина предлагают AlphaGAN архитектуру для данной задачи.
В математических терминах, каждый пиксель i на изображении воспринимается, как линейная комбинация цветов переднего плана и заднего:
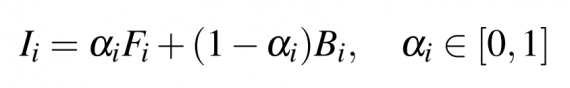
где ai это скалярная величин, которая оперделяет прозрачность переднего плана в пикселе i и относится, как альфа-значение.
Итак, как же решить данное уравнение со столькими переменным? Давайте для начала узнаем state-of-art подходы к решению данной задачи.
Предыдущие работы
Большое количество существующих алгоритмов относятся к решению уравнения матирования, как к проблеме раскраски с помощью подходов sampling или распространения.
Sample-based матирование подразумевает, что истинные переднего и заднего планов на неизвестных пикселях могут быть получены от образцов (samples) пикселей, которые находятся рядом. Методы которые основаны на этом предположении:
- Байесовское матирование
- Итеративное матирование
- Shared sampling матирование
- Sparse coding
Матирование распространением (propagation) работает посредством распространения известных альфа-значений от локальных образцов переднего и заднего планов к неизвестным пикселям. Известные примеры:
- Пуассоновское матирование
- Случайное блуждание
- Геодезическое матирование
- Спектральное матирование
- Матирование с помощью нечеткой связности
- Аналитическое матирование
Однако, если опираться только на информацию о цвете, то это может привести к появления артефактов в изображениях, где распределения цветов на переднем и заднем планах перекрывают друг друга.
Недавно было предложено несколько подходов к матирования в контексте глубокого обучения:
- Двуступенчатая нейросеть, состоящая из энкодер-декодер стадии и стадии доводки, за авторством Зу и коллег.
- End-to-end сверточная нейросеть для автоматического матирования портретов, автор Шен и др.
- End-to-end сверточная нейросеть, которая использует результаты, полученные от локального и нелокального алгоритмов матирования, авторы Чо и др.
- Гранулированая архитектура глубокого обучения от Ху и коллег.
Но возможно ли улучшить данные результаты с помощью генеративно-состязательной нейросети? Давайте выясним.
State-of-art идея
Лютз, Амплианитис и Смолич из Дублинского Тринити-Колледжа первыми предложили использовать генеративно-состязательные нейросети для естественного матирования изображений. Их генеративная нейросеть обучена на предсказание визуальных проявлениях альфа-значений, тогда как дискриминатор натренирован классифицировать качественные изображения. Под качеством здесь следуют понимать хорошо скомпонованые изображения.
Исследователи основывают свой подход на идеях, предложенных Зу, улучшая архитектуру сети ради решения проблем пространственной локализации присущие сверточным нейросетям. В частности, они использовали расширенные свертки для улавливания глобальной контекстной информации без уменьшения карт признаков и потерь пространственной информации.
Архитектура сети
AlphaGAN архитектура состоит из генератора G и дискриминатора D.
Генератор G это сверточная энкодер-декодер сеть обучается с помощью ground-truth альфа-значений и состязательных потерь, которые предоставляет дискриминатор. Он принимает изображение, составленное из переднего плана, альфа-значения и случайного заднего фона присоединенный с помощью тримапа, как 4-й канал входного сигнала и пытается предсказать корректную альфу. Для кодировщика использована архитектура Resnet50.
Как можно увидеть на картинке ниже на картинке ниже, декодер включает в себя skip-connection из кодировщика для улучшения предсказания предсказания альфа-значений путем переиспользования локальной информации для детектирования тонких структур в изображении.
-

Генератор сети AlphaGAN
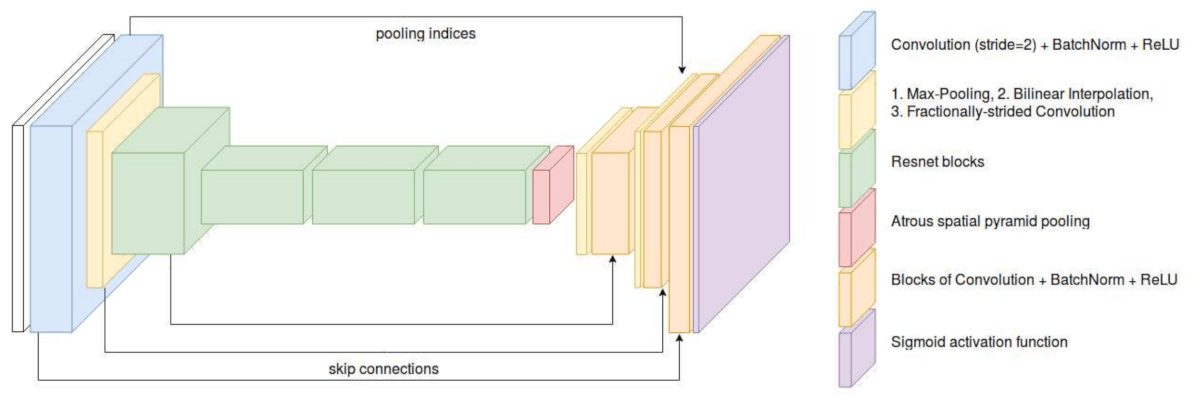
Дискриминатор D пытается найти отличия между реальным 4-х канальным вводом и искусственным, где первые три канала составлены из переднего плана, заднего плана и предсказанной альфы. PatchGAN, представленный Изолой и коллегам, используется в дискриминаторе.
Полная целевая функция нейросети включает в себя потери предсказания альфа-значений, потери композиции и состязательные потери:
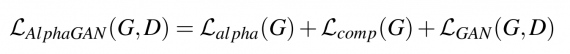
Экспериментальные результаты
Предложенный метод оценивался на двух датасетах:
- Composition-1k датасет, который включает 1000 тестовых изображений составленных из 50 уникальных передних планов
- alphamatting.com датасет, который состоит из 28 тренировочных изображений и 8 тестовых; для каждого набора представлены три размера тримапа: маленький(S), большой(L), пользовательский(U).
Composition-1k Dataset
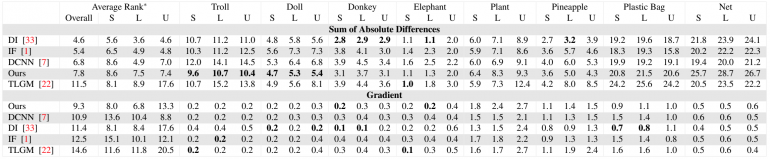
Метрики использовавшиеся для оценки:
- сумма абсолютных различий (SAD)
- Среднеквадратичная ошибка
- Градиентная ошибка
- Ошибка связности
Исследователи сравнивают AlphaGAN подход с нескольким другими state-of-art подходами, с открытым исходным кодом. Для всех методов использованы оригинальные коды, без модификаций.
-
Количественные результаты на Composition-1k. Результаты AlphaGAN в скобках

Как можно увидеть из таблицы AlphaGAN показывает значительно лучшие результаты, чем конкуренты, и только один случай, где AlphaGAN показал себя хуже.
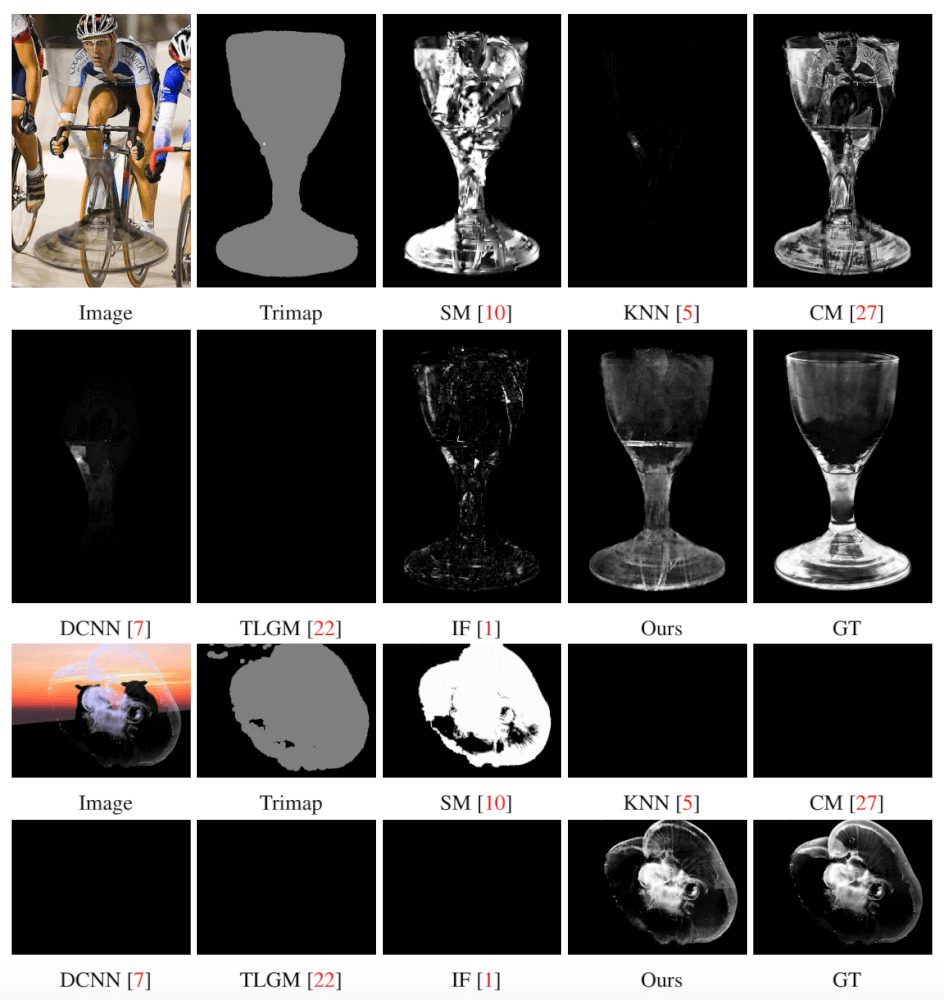
Рассмотрим также некоторые качественные результаты:
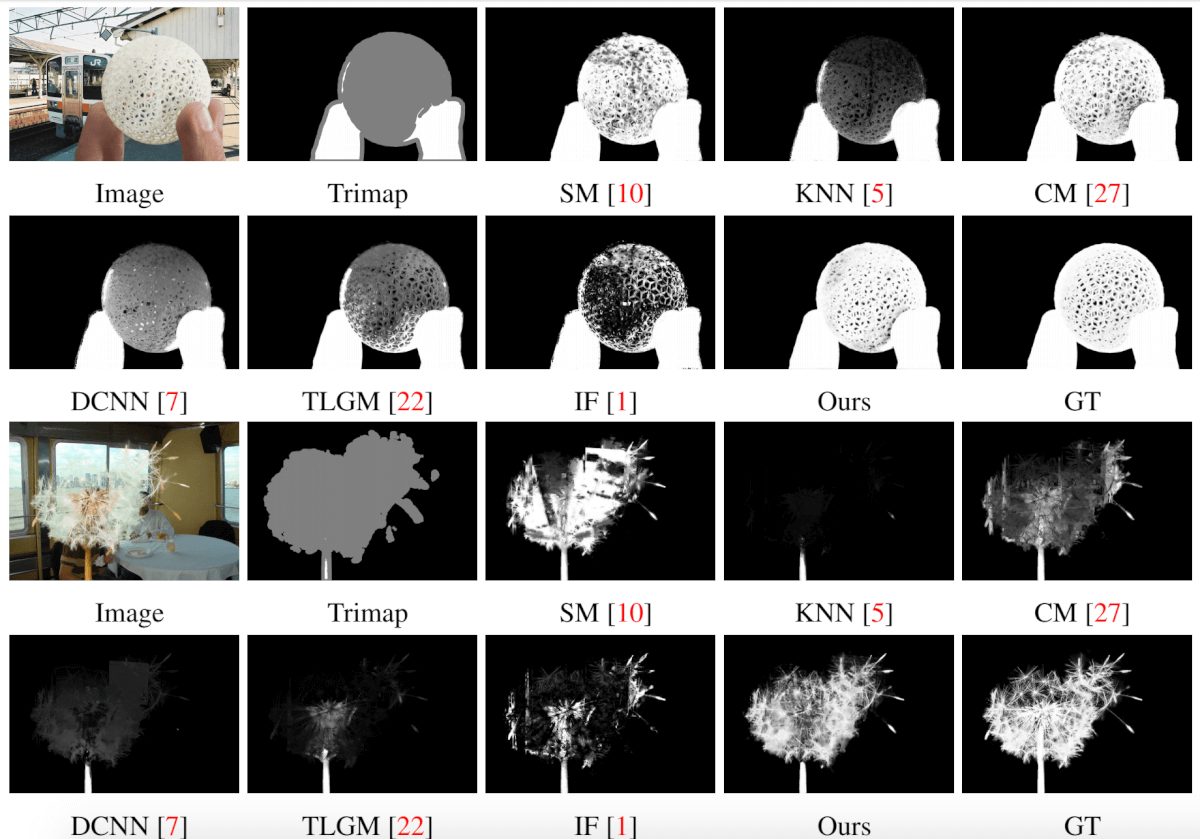

-
Сравнение результатов на Composition-1k
Alphamatting.com датасет
Исследователи приводят результаты, полученные AlphaGAN по бенчмарку alphamatting.com и он занял первые позиции на некоторых изображениях.
-
SAD и градиент результаты для 5 лучших методов на alphamatting.com dataset. Лучшие результаты выделены жирным
Лучших результатов удалось достичь на изображениях Тролля и Куклы и первое место среди всех по метрике градиента. Хорошие результаты на таких картинках показывают преимущества использования состязательных потерь для корректного предсказания альфа-значений для таких тонких структур, как волосы.
Худшие результаты были получены на изображении с сеткой. Однако, даже на ней AlphaGAN показывает результаты близкие к лучшим.
![Alpha matting predictions for the "Troll" and "Doll" images (best results) and the "Net" image (worst result) taken from the alphamatting.com dataset. From left to right: DCNN [7], IF [1], DI [33], âOursâ](https://neurohive.io/wp-content/uploads/2018/09/1.jpg)

Предсказание для Тролля и Куклы (лучшие результаты) и Сетки (худший результат). Слева направо DCNN, IF, DI, AlphaGAN
![Alpha matting predictions for the "Troll" and "Doll" images (best results) and the "Net" image (worst result) taken from the alphamatting.com dataset. From left to right: DCNN [7], IF [1], DI [33], âOursâ](https://neurohive.io/wp-content/uploads/2018/09/3.jpg)
Итог
AlphaGAN — это первый алгоритм, который использует GAN для естественного матирования изображения. Генератор обучен на предсказания альфа-значений из исходного изображения, тогда как дискриминатор обучен различать “хорошее” изображение полученное из ground-truth альфа значений от изображений построенного по предсказанным альфам.
Такая архитектура создает правдоподобные результаты. Исключительные результаты достигаются на изображениях с тонкими структурами, такими как, например, волосы. Это имеет большое значение для практических применений матирования, например в кинематографе.



