В FAIR агента обучили играть в кооперативную карточную игру Ханаби. Ханаби является базовой задачей для обучения игровых агентов, потому что содержит в себе и кооперацию, и скрытую информацию. Бот обыгрывает предыдущие алгоритмы в Ханаби с помощью поиска оптимальных решений в реальном времени. Это первый бот, который обошел человека в этой игре.
Ранее агенты с использованием обучения с подкреплением обыгрывали людей в игры с нулевой суммой, как шахматы, Го и покер. В таких играх участники выступают против друг друга. Несмотря на это, в задачах из реального мира агентам необходимо уметь взаимодействовать друг с другом, чтобы достичь цели. Методы поиска, которые используются в играх с полной информацией, как шахматы и Го, не подходят для игры в Ханаби. Это связано с тем, что каждый игрок не может видеть все карты, которые находятся в игре.
Игроки в Ханаби обязаны понимать убеждения и намерения других игроков. чтобы успешно завершить игру. Агент от FAIR достигает это с помощью алгоритма поиска оптимального решения в реальном времени. Алгоритм схож с методом поиска ограниченной глубины (depth-limited search) в Pluribus. Этот алгоритм поиска работает совместно с предопределенной стратегией. Такой подход позволяет подгонять свои действия под отдельные ситуации, которые встречаются во время игры.
Предложенный метод поиска может использоваться для улучшения стратегии игры в Ханаби, включая алгоритмы глубокого обучения с подкреплением. Ранее state-of-the-art решениями игры в Ханаби являлись методы из глубокого обучения с подкреплением.
Описание игры
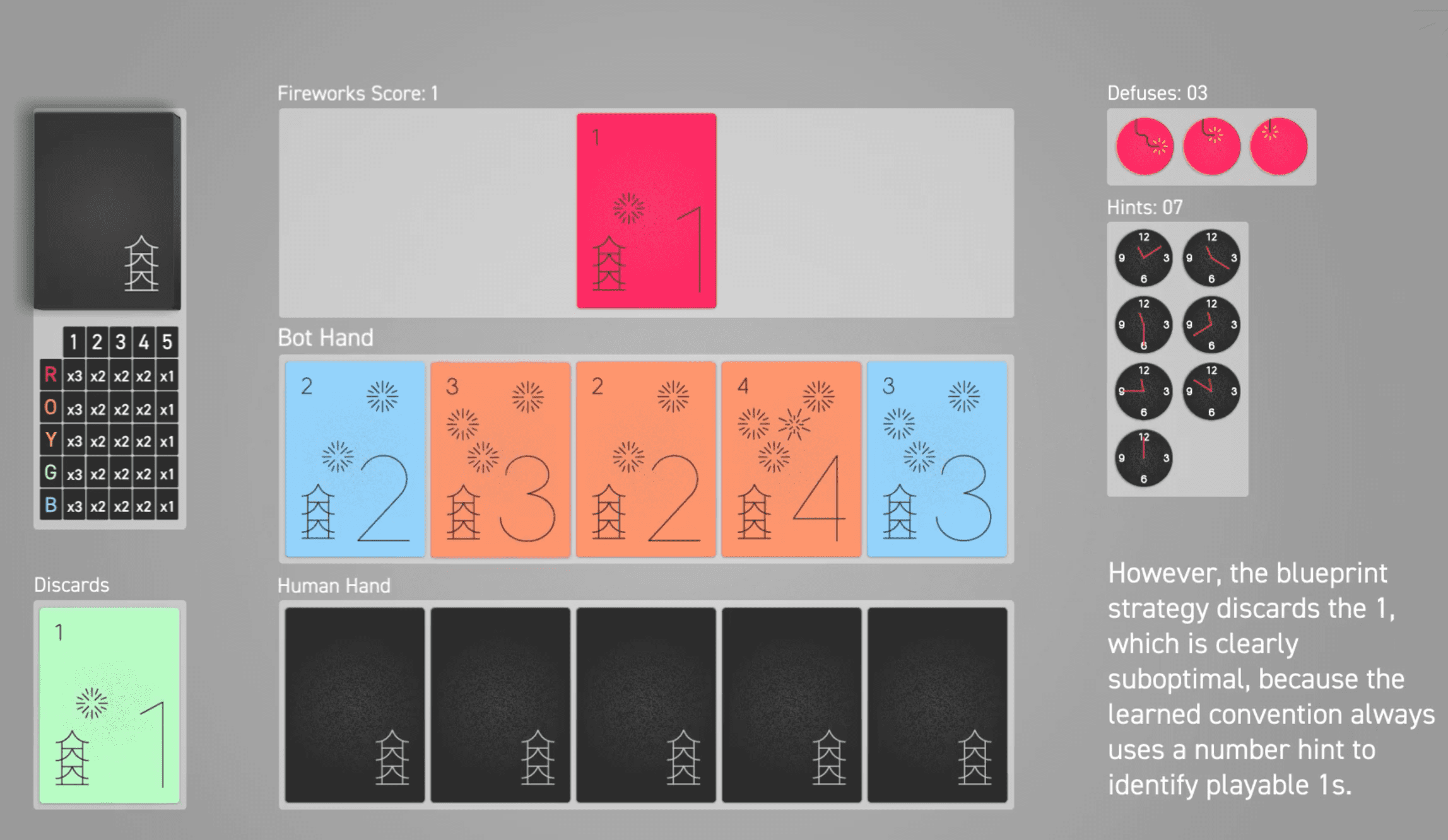
Ханаби — это полностью кооперативная карточная игра, которую иногда описывают как “командный солитер”. Каждый игрок видит карты остальных игроков, но не видит свои.
Поиск выигрышной стратегии
Предыдущие работы для поиска стратегии игры в Ханаби использовали алгоритмы обучения с подкреплением. Агент следовал выученной стратегии на протяжении всей игры. Такие алгоритмы должны определить действия для всего множества событий в игре. С этим связан их недостаток: они только грубо аппроксимируют оптимальную стратегию для отдельных ситуаций.
Предложенный метод поиска подгоняет выученную стратегию под ситуации. Чтобы обучить агента верно определять наиболее оптимальный ход, ему необходимо знать вероятностное распределение для возможных состояний среды. Возможные состояния среды — это те карты, которые он может держать в руке на текущем шаге. В FAIR для этого тестируют два подхода:
- Single-agent поиск;
- Multi-agent поиск
Результаты экспериментов
Предыдущий state-of-the-art подход для игры в Ханаби получал результат 24.08 в игре с двумя игроками. Если добавить к боту на эвристиках, который обычно получает результат 22.99, single-agent поиск, результат возрастет до 24.21. Метод от FAIR обходит все текущие подходы, которые основываются на глубоком обучении с подкреплением.