Команды SII-GAIR и Sand.ai опубликовали daVinci-MagiHuman — открытую мультимодальную 15B-модель на основе однопоточного трансформера, которая одновременно генерирует видео с липсинком и синхронное аудио и создает 5-секундный клип в 256p за 2 секунды на одном GPU H100. Весь стек открыт под лицензией Apache 2.0: базовая модель, дистиллированная версия, модуль сверхразрешения и код для запуска доступны на GitHub и Hugging Face, демо — на Hugging Face Spaces. Это редкость для моделей такого уровня — большинство конкурентов (Veo 3, Sora 2, Kling 3.0) закрыты. Среди открытых аналогов (Ovi, LTX-2) daVinci-MagiHuman показывает лучшее качество видео и самую низкую долю ошибок при распознавании сгенерированной речи — 14.60% против 40.45% у Ovi 1.1, что говорит о значительно более чёткой и разборчивой речи в выходном видео.
Пример липсинк-видео, сгенерированного daVinci-MagiHuman на основе фото:

Зачем вообще делать один поток вместо двух?
Большинство современных моделей для совместной генерации видео и аудио устроены так: один поток токенов обрабатывает видео, другой — аудио, а между ними стоит блок перекрёстного внимания (cross-attention), который их «склеивает». Это логично, но создаёт проблемы на практике: нестандартные вычислительные паттерны сложно оптимизировать на железе, а сам код становится громоздким. Качество липсинка тоже страдает, когда видео и аудио не обучаются совместно с самого начала.
daVinci-MagiHuman идёт другим путём. Текст, видео и аудио просто складываются в одну последовательность токенов и прогоняются через единый трансформер с самовниманием (self-attention). Никакого перекрёстного внимания, никаких отдельных блоков слияния модальностей. Это называется однопоточная архитектура, и именно она позволяет модели учить липсинк напрямую в процессе совместного шумоподавления, а не как отдельный этап слияния.
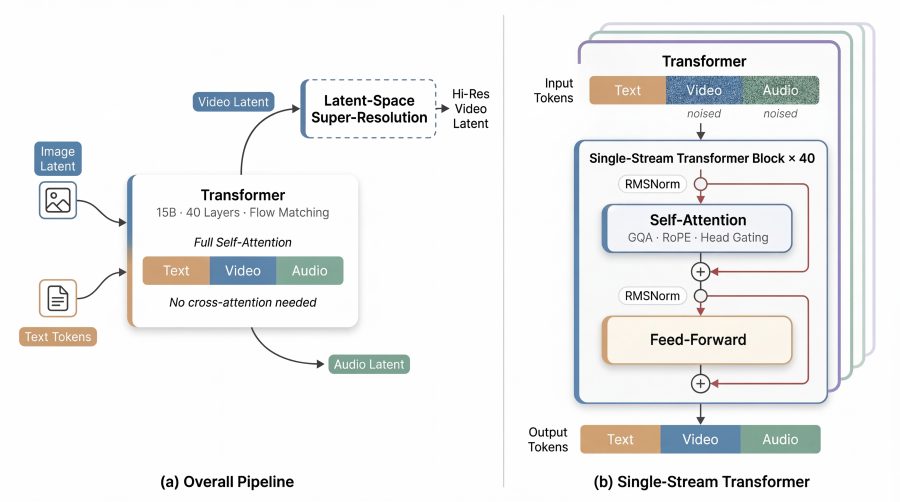
Как устроен трансформер внутри
Модель содержит 15 млрд параметров и 40 слоёв. Авторы выбрали «сэндвич»-раскладку (sandwich layout): первые и последние 4 слоя используют модально-специфичные проекции и параметры нормализации RMSNorm, чтобы правильно «прочитать» и «записать» каждую модальность. 32 слоя посередине полностью разделяют веса между всеми модальностями. Именно здесь происходит глубокое мультимодальное смешение скрытых представлений, включая акустико-визуальное выравнивание, необходимое для точного липсинка.
Ещё два нестандартных решения. Первое — модель работает без явного вложения временно́го шага (timestep embedding): вместо того чтобы явно передавать модели номер шага шумоподавления, она сама вычитывает текущее состояние из зашумлённых скрытых представлений на входе. Второе — гейтинг по головам внимания (per-head gating): выход каждой головы механизма внимания взвешивается обучаемым скалярным коэффициентом через сигмоиду. Формально выход h-й головы умножается на σ(g_h), где g_h — обучаемый параметр. Это улучшает численную устойчивость при обучении и почти не добавляет вычислительных затрат.
Как модель генерирует липсинк-видео быстро
Генерация липсинк-видео высокого разрешения «с нуля» дорого стоит — количество токенов растёт квадратично при увеличении разрешения. Авторы решают это через сверхразрешение в пространстве скрытых представлений (latent-space super-resolution): базовая модель сначала генерирует видео в низком разрешении (256p), потом отдельный модуль сверхразрешения уточняет скрытое представление за 5 дополнительных шагов шумоподавления прямо в скрытом пространстве — без лишнего прохода через кодировщик и вариационный автоэнкодер (VAE). Аудио участвует в сверхразрешении как вспомогательный сигнал — это особенно важно для сохранения точности липсинка при апскейлинге от низкого базового разрешения.
Дополнительно применяются: ускоренный декодировщик Turbo VAE (облегчённый декодировщик, ускоряющий финальное декодирование), полная компиляция вычислительного графа через MagiCompiler (даёт ~1.2× ускорение на H100) и дистилляция базовой модели по методу DMD-2 — дистиллированная версия укладывается в 8 шагов шумоподавления без весового коэффициента classifier-free guidance (CFG).
В итоге на одном GPU H100 дистиллированная модель генерирует 5-секундное липсинк-видео в 256p за 2 секунды, в 540p — за 8 секунд, в 1080p — за 38.4 секунды.
Как запустить самому
Авторы предлагают два способа поднять модель локально. Первый — через Docker: разработчики подготовили образ sandai/magi-compiler с уже настроенным окружением, куда нужно просто смонтировать папку с весами. Второй — через conda с Python 3.12 и PyTorch 2.9. В обоих случаях отдельно устанавливается Flash Attention для архитектуры Hopper и MagiCompiler — собственный компилятор вычислительного графа от Sand.ai, который и даёт то самое ускорение 1.2× на H100.
После установки в репозитории есть готовые скрипты для каждого режима: базовая модель в 256p, дистиллированная версия (8 шагов без CFG), сверхразрешение до 540p и до 1080p — каждый запускается одной командой bash. Веса нужно скачать с Hugging Face и прописать пути в конфиг-файлах в папке example/.
Насколько хорошо работает липсинк
Для оценки качества видео авторы использовали тестовый набор VerseBench с метриками VideoScore2 (визуальное качество, соответствие тексту, физическая согласованность), а для аудио и качества липсинка — TalkVid-Bench с метрикой WER (доля ошибочно распознанных слов в сгенерированной речи — чем ниже, тем чище и разборчивее звук). daVinci-MagiHuman лидирует по трём из четырёх метрик, показывая WER 14.60% — почти втрое ниже, чем 40.45% у Ovi 1.1, что напрямую отражает качество липсинка и чёткость речи.
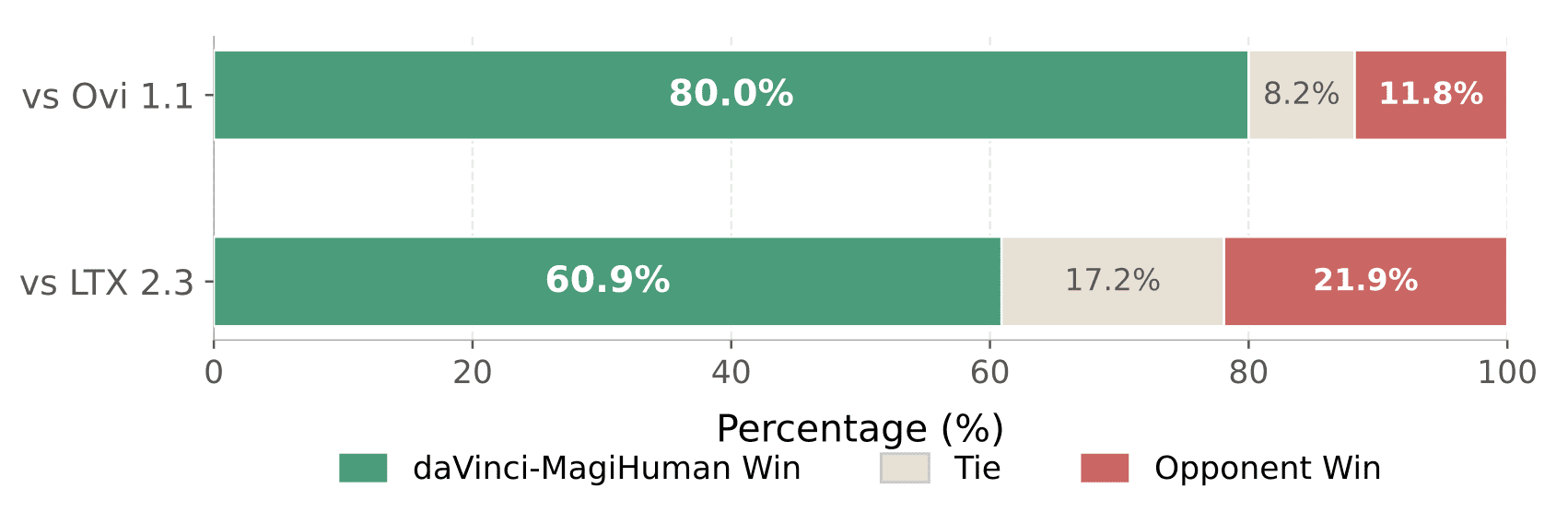
Помимо автоматических метрик, провели попарную оценку с участием людей. 10 асессоров оценили 2000 пар клипов — 100 сравнений с каждым конкурентом на каждого асессора. daVinci-MagiHuman победил в 80.0% случаев против Ovi 1.1 и в 60.9% против LTX 2.3.
Заключение
daVinci-MagiHuman показывает, что однопоточная архитектура — это не просто простота, но и более естественный подход к генерации липсинка: речь и движения лица учатся как единый сигнал, а не склеиваются постфактум. Единый трансформер проще оптимизировать, проще масштабировать и проще воспроизводить сообществу. Полная открытость стека под лицензией Apache 2.0 — базовая модель, дистиллят, модуль сверхразрешения, код — делает это особенно ценным для исследователей, которые хотят продолжать работу над липсинком и аудио-видеогенерацией.