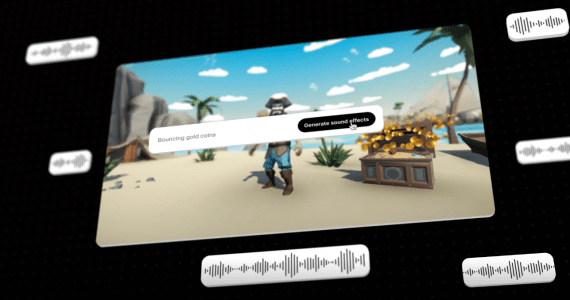
Deep Network Priors: unsupervised метод подавления аудиошума

Просмотров: 5803
Подписаться
0 Comments
Старые