Сегментация сущностей на переднем и заднем планах изображения — впечатляющая способность детекторов, которые становятся все точнее и вариативнее. Но на практике модели сегментации ограничены узким участком визуального мира, который включает примерно 100 категорий объектов. Причина этого ограничения проста — современные алгоритмы сегментации требуют обучения с учителем, а значит, данные должны быть размечены людьми, что дорого для сбора новых категорий. Для сравнения, ограничивающие объект рамки (bounding box) популярнее и дешевле для разметки (поместить объект в прямоугольник куда проще, чем аккуратно выделить).
Подход к сегментации от FAIR
FAIR представили новую задачу частичного обучения (partially supervised learning, похожую на semi-supervised learning, некоторые авторы не различают эти методы) сегментации сущностей и предложили новый метод обучения для ее решения. Частично контролируемая задача сегментации объекта формулируется следующим образом:
- Дан набор интересующих категорий, небольшое подмножество имеет разметку (маску и рамки), в то время как другие категории имеют только ограничивающие рамки.
- Алгоритм сегментации объекта должен использовать эти данные, чтобы научить модель, которая может сегментировать объекты всех категорий в интересующем наборе (то есть разметить подмножество, где есть только рамки).
Поскольку обучающие данные представляют собой смесь сильно размеченных примеров (маска + рамки) и слабо размеченных примеров (только с рамками), задача относится к частично контролируемым. Для решения проблемы частично контролируемой сегментации экземпляров используется новый подход к обучению, основанный на Mask R-CNN. Mask R-CNN хорошо подходит для этой задачи, поскольку она разбивает задачу сегментации экземпляра на подзадачи обнаружения рамок и выделения масок.
Учимся сегментировать всё
Пусть C — набор категорий объектов, для которых обучается модель сегментации. Все обучающие примеры из C имеют маски. Предполагается, что С = А ∪ B, где образцы категорий A имеют маски, а B только рамки. Поскольку примеры категорий B размечены слабо, то задача (сегментация объектов) относится к обучению на комбинации сильно и слабо размеченных данных, как частично контролируемая задача.

Этот метод основан на использовании Mask R-CNN, потому что это простая модель сегментации сущностей, которая достигает современных (state-of-the-art) результатов. В маске R-CNN присутствует две ветви. В конечном итоге одна ветвь предсказывает ограничивающие рамки (будем называть её ветвью рамок), а вторая маску объекта (будем называть её ветвью маски). В последних слоях данных веток содержатся дополнительные параметры для каждой категории, которые используются при предсказании. Вместо этого авторы предлагают в некоторый момент прокинуть веса с ветви рамок на ветвь масок и называют это transfer function. При этом функция передачи (transfer function) это тоже какая-то настраиваемая функция (может быть нейронной сетью) которая, вообще говоря, выбирается дифференцируемой, чтобы обучать end-to-end.
Пусть для заданной категории cat, w(det) — те самые индивидуальные веса объектов класса в последнем слое ветви рамок, а w(seg) — аналогичные веса в ветви маски. Вместо того, чтобы рассматривать w(seg) в качестве параметров модели, w(seg) параметризуется с помощью общей функции прогнозирования веса T(·):
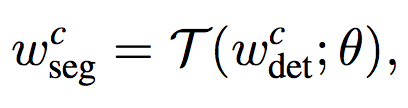
где θ не зависящие от класса настраиваемые параметры. Функция передачи T(·) может быть применена к любой категории cat и, таким образом, θ должна быть выбрана так, что T обобщается на классы, маски которых не наблюдаются во время обучения.
T(·) может быть реализована в виде небольшой полносвязной нейронной сети. На рис. 1 показано, как функция передачи помещается в маску R-CNN для формирования Mask^X R-CNN. Обратите внимание, что ветвь рамки содержит два типа весов: веса региона интересов(RoI) w(cls) и веса регрессии ограничивающей рамки w(box).
Эксперименты на наборе данных COCO
Этот метод был применен на наборе данных COCO, который включает в себя мало категорий, но содержит исчерпывающие маски для 80 категорий. Каждый класс имеет вектор параметров размерности 1024 для региона интересов(RoI) w(cls), вектор параметров размерности 4096 для регрессии ограничивающей рамки w(box) и вектор из 256 параметров для сегментации w(seg). Заметим, что последние два вектора w(box) и w(seg) находятся в голове сети. Разрешение выходной маски M × M = 28 × 28. В таблице ниже приведено сравнение с бейзлайнами.
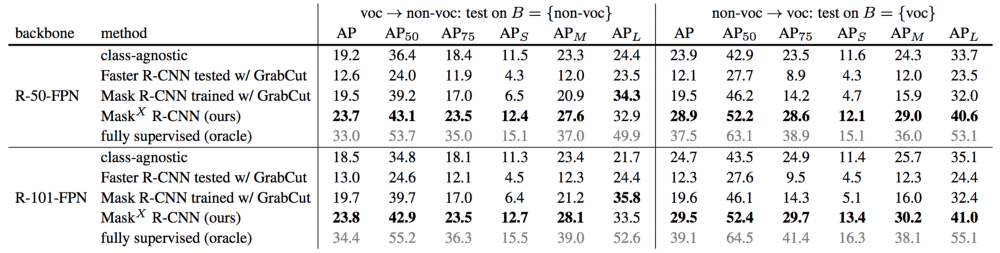
Результаты

В исследовании рассматривалась проблема сегментации объектов с помощью частично контролируемого обучения, в которой только подмножество классов имеет маски во время обучения, а остальные имеют только рамки. Исследователи предлагают новый подход к функции передачи, где обученные веса предсказывают, как каждый класс должен быть сегментирован на основе параметров обнаружения рамок. Экспериментальные результаты на наборе данных COCO показывают, что этот метод значительно улучшает обобщающую способностью прогнозирования масок на категории без размеченных масок.

Модель способна помочь построить крупномасштабную модель сегментации экземпляров на основе 3000 классов в наборе данных Visual Genome.